Milestone Report: Parallel Differentiable Circuit Fault Simulator
Team Member: Xinyu Li (xinyul3), William Zou (yangzou)
URL: Project Webpage
URL: View this report in Google Doc
Summary of Work Done
- Analyzed the current baseline simulator and learned how DGL
graph_pull()andapply_edges()propagate logic and fault values. Transformed the original data structures to be CUDA compatible. - Implemented kernels for value propagation and fault observability propagation with support for evaluating different gate types concurrently.
- Implemented
graph_pullforward and backward kernels, and refactored the kernel from step 2 into a function used by both directions. - Integrated the new kernels into the simulation pipeline and tested them on small-sized benchmarks to verify correctness.
- Conducted initial rough performance analysis.
Progress with Respect to the Plan
We are on track to meet our goals. The main pending task is full implementation of apply_edges(). We did not use the GHC cluster due to AFS storage issues and instead used ECE lab machines.
Updated Poster Session Goals
- Finish implementing kernels for
apply_edges(). - Conduct detailed performance analysis across multiple benchmark circuits against the baseline.
- Experiment with various CUDA parameters to optimize for different circuit sizes.
- Analyze bottlenecks and apply possible edge optimizations.
- If time permits: early dependency resolution and locality investigation.
Poster Session Content
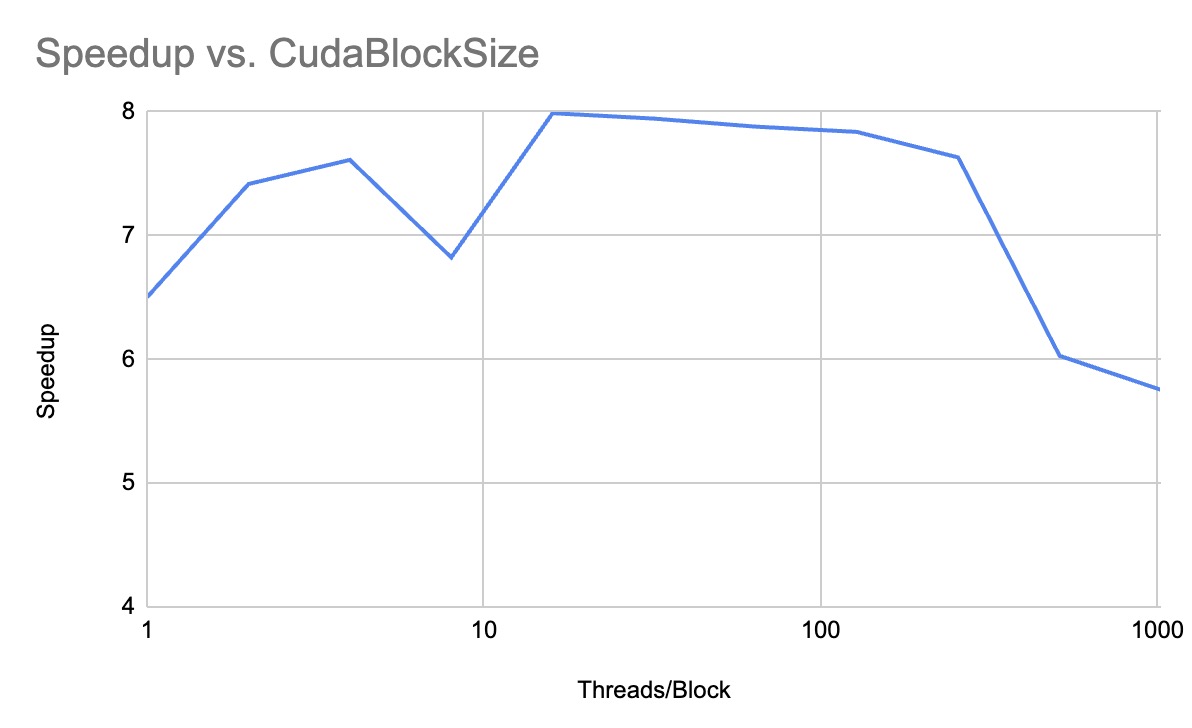
We will present stage-wise speedup results leading up to the final implementation using graphs. Additionally, we’ll show a detailed CUDA parameter analysis to demonstrate scalability with respect to circuit size.
Preliminary Result Graph
Comparison between cuda_graph_pull and dgl_graph_pull:
Issues and Concerns
- Memory access patterns are highly irregular and difficult to optimize.
- Gate heterogeneity is currently causing thread divergence. Early dependency resolution could help alleviate this.
Updated Schedule
Week 1 (03/27-04/01):
- Analyze the current baseline simulator to understand how DGL
pull()andapply_edges()propagate logic and fault values. (Done) by William and Xinyu - Write data structures to represent circuit graphs and gate metadata compatible with CUDA. (Done) by William and Xinyu
Week 2 (04/02-04/08):
- Implement the initial kernel for logic value propagation and fault observability rules. (Done) by William and Xinyu
- Start integrating the kernel into the Python pipeline using
torch.utils.cpp_extension. (Done)
Week 3 (04/09-04/15):
- Complete integration of the kernel into the simulation pipeline. (Done) by William and Xinyu
- Verify correctness by comparing outputs against the baseline. (Done) by William and Xinyu
Week 4-1 (04/16-04/18):
- Finish implementing kernels for
apply_edges(). (Done) by William and Xinyu
Week 4-2 (04/19--04/21):
- Conduct thorough performance analysis using different benchmark circuits with respect to the baseline model.(Done) by William and Xinyu
Week 5-1 (04/22-04/24):
- Experiment with different CUDA parameters (e.g., block size, shared memory usage, warp size) to find the best settings for different circuit sizes.(Done) by William and Xinyu
- Analyze bottlenecks and apply near-edge optimizations such as memory coalescing or instruction-level parallelism.(Done) by William and Xinyu
Week 5-2 (04/25-04/28):
- Complete the final report and update the project website.(Done) by William and Xinyu
- Design presentation posters and visual summaries of simulation results and speedups.(Done) by William and Xinyu