1 Abstract
We implemented a parameterizable, cycle-accurate simulator of a general-purpose GPU. Our model contains parallel thread execution, global memory, and thread scheduler policies, as well as branch divergence and a number of additional influential parameters. This allowed us to study the runtime profile of a GPU's hardware features in a cycle-by-cycle way and to pay close attention to the hardware features most influential. We benchmarked the effect of each GPU hyperparameter on the overall runtime and resource usage of matrix-matrix multiplication and convolution, implementing Gaussian blurring.
2 Background
Modern SoCs rely heavily on GPUs to offload data parallel workloads for faster computation. While CPU architecture has a rich open-source design space, GPU architecture has unfortunately been primarily a proprietary topic with fewer open source tools available. Due to the limitations on performance counters implemented in production designs, it is not always possible to conduct fine-grained studies of various elements of a GPU's design to help intuit information about the vendor's design decisions or the effect that a certain design decision could have on performance.
When creating new micro-architectural features, it is necessary to create simulated models of those features to benchmark how they interact with the rest of the product. Unfortunately, hardware-level implementations are substantially more costly to develop and execute benchmarks far slower than simulations. While emulators provide functional models of the result of executing a program, they do not provide a cycle-accurate model of how hardware would actually execute a program. This makes instrumentation that tracks metrics related to the performance of the u-arch impossible.
GPGPUs, such as those exposed via the CUDA architecture, have large blocks of cheaply created threads that are physically scheduled in smaller execution contexts within a specific multiprocessor. Each thread of the execution context maps to a specific hardware thread in the multiprocessor which maintains its own program state but is ideally controlled in a SIMT paradigm where a single instruction is applied simultaneously to multiple threads that run in parallel to improve the throughput of a given computation.
3 Implemented Features
The primary challenge was implementing sufficient features to conduct an interesting design space exploration. Not having sufficient instructions or other parameters would make it difficult to simulate realistic workloads. There is always the opportunity to add more features to this model to make it more realistic with modern GPGPUs available on the market, but doing so may not be time efficient because those instructions are rarely used or certain schedulers can be inefficient to implement in hardware.
As such, we developed a simulator of a single-cycle RISCV32I processor, then expanded the instruction set architecture to fit more specific GPU needs.
3.1 Support for Execution of Basic Operations
We implemented full support for the RV32I instruction set architecture. This includes basic ALU operations, branches, loads, and stores. We used a riscv decode crate to decode all RV32I instructions. Originally, we proposed to create a much more limited set of available instructions to save time on implementation. However, this slightly more complicated initial approach gave us much more granularity in debugging and ensuring correctness. We gained the ability to check both memory and register state at all times in the program to ensure that we were running as expected.
This also gave us much more freedom when it came to benchmarks and testing. We were able to write C programs, compile them down to RISCV assembly, and run them and check correctness.
3.2 Custom Instructions
We added four custom instructions:
- Bdim: Get the width of the block in threads and place it in the destination register.
- Syntax:
Bdim rd, whererdis between 0 and 31. - Required to calculate block level offsets.
- Syntax:
- Gdim: Get the number of blocks and place it in the destination register.
- Syntax:
Gdim rd, whererdis between 0 and 31. - Required to calculate global offsets.
- Syntax:
- Tid: Get the thread ID of the current thread and place it in the destination register. This is relative to the block, not the global number of threads.
- Syntax:
Tid rd, whererdis between 0 and 31. - Required to calculate offsets and indices.
- Syntax:
- Bid: Get the block ID of the current block and place it in the destination register.
- Syntax:
Bid rd, whererdis between 0 and 31. - Required to calculate offsets and indices.
- Syntax:
All of these instructions are required to write correct GPU programs to properly divide work amongst threads and to ensure no repeated work. Because our grid and block dimensions are modifiable, all four of these custom instructions were required. Custom instructions were implemented as inline assembly in C functions. They are decoded as custom instructions and then executed.
3.3 Parameters
- Number of blocks (N): Specifies grid dimensions, allowing more division of threads and work.
- Number of warps per block (W): Specifies how a block is divided into runnable units.
- Number of threads per warp (T): Specifies the width of a warp, allowing us to modify how wide the functional units are and how many threads are spawned.
- Number of functional units (F): Specifies how many parallel execution units are present. Note that each functional unit is capable of running a full warp per cycle.
- Memory delay (M): Specifies how long a thread waits for a load or a store to complete. All memory operations commit at the end of the wait, not at the beginning.
- Scheduler (S): Specifies which type of scheduler is used. More detail is provided in section 3.4.
3.4 Schedulers
We implemented three schedulers to explore the design space of different scheduling methods more effectively. Each scheduler returned a set of runnable warps up to the maximum number of functional units, and those warps were run. Runnability was determined by the thread not waiting for a memory access to return and not being halted.
In the same way that caches largely do not use real LRU policies, instead opting for approximations, none of these schedulers are directly capable of being efficiently implemented in real hardware. Instead, they are models of ideal execution for hardware, and an approximation of the performance that could be achieved with similar scheduling policies in hardware. We chose policies for ease of implementation and potential speedup.
3.4.1 Lowest Index
This was our naive implementation of a scheduler, selected for the simplicity of implementation. This picks the lowest available index using [block, warp] as the selection metric. It does this until all functional units have work to do that cycle or until all warps have been tried. This is a greedy algorithm that does not operate well with dependencies between threads.
3.4.2 Loose Round Robin (LRR)
This was our next attempt at a scheduler, one that distributes work more evenly. Loose round robin distributes work evenly by looping through every warp in round robin format, and issuing that warp if the warp is ready to run. This scheduling policy ensures that no warps stall infinitely, but can result in a warp being skipped over many times with no added priority after the skips. It is not efficient at overlapping memory latency, but in our model this was not a major factor because we simulated having as much memory bandwidth as was required.
3.4.3 Least Recently Used (LRU)
Least recently used selects the warp or warps that were both least recently run and runnable to be the next to run. This ensures that no warps starve infinitely and can resolve the problem of a skipped warp falling very behind by ensuring that it does progress once unstalled. This scheduler also does not properly batch memory requests, but does a better job of keeping threads relatively together. We expected this to provide benefits over LRR, but the data showed that this performed effectively the same as LRR in practice.
3.5 Branch Divergence
Branch divergence is handled by allowing all threads in a warp to execute their current PC before allowing all threads to advance their PCs to their next instructions. This models how real GPUs function with SIMT, and prevents us from using an overly optimistic model of GPU runtime.
Branch divergence is handled using a mask of all threads in a warp that have not been updated for one timestep per thread. A timestep is not one cycle; instead, a timestep increments when all threads in a warp have moved forward one instruction. Each cycle, a thread is selected and all threads with the same PC are run, then the mask is set to indicate that those threads have run during the time step. Once all threads in a timestep have run, the mask is reset.
While not the most accurate model for branch divergence in a GPU, this accurately conveys the issue with branch divergence for the purposes of simulation, while being relatively simple to write. In this way, we execute SIMT instructions throughout a warp and can accurately convey the slowdown experienced by branch divergence without the complexity of handling branch divergence scheduling.
3.6 Support for Performance Counters
We used performance counters in our sensitivity studies. These counters gave us key context about how modifying our parameters affected the speed and efficiency of our GPU. We used the counters to collect data about different configurations to give insight about which parameters were more influential on our benchmarks.
3.6.1 Total number of cycles
The first major counter we used was for the total number of cycles. This gives us key speedup numbers as we modify our parameters and allows us to measure how long a given benchmark would take. This is the least granular counter, but one that gives a lot of insight into how well a given set of parameters is working. However, this counter does not have very much granularity into why a set of parameters is not as effective.
3.6.2 Warp Activity
We track how many cycles no warps were issued and how many cycles at least one warp was awake. This gives us a more detailed understanding of how effectively our configuration latency hides memory accesses, because the only reason no warps would be running is if all warps have a pending memory access. This also helps to track functional unit usage to see if all available functional units are frequently used. A low average functional unit usage compared to the amount of functional units is a good metric that the available hardware is not being utilized properly and may not be worth the additional power or area cost.
3.6.3 Warp Utilization
We track how many threads were run per cycle. Branch divergence can have a major impact on the speed of a program, and tracking utilization provides key insights into whether the performance of a program is limited by branch divergence. A warp is runnable even if branch divergence has led to each thread in the warp being at a different PC, so this provides another metric for functional unit utilization.
3.7 Future Work
Thread Synchronization: We did not explore synchronization operations such as barriers or reductions. These are not strictly necessary if true data parallelism can be achieved. However, this may not be a realistic goal in many cases, despite a workload being a good candidate for parallelization on a GPU. This is a rich design space that would be interesting to consider because sync points raise the possibility that certain execution groups could become blocked, leading to fragmented instruction issues. There also arises the possibility of starvation due to poor scheduler decisions to deschedule an execution group for a lengthy period of time due to the presence of a barrier.
Several Multiprocessors: We have considered a single multiprocessor due to simplicity of implementation, but this is not sufficient to capture all of the parallelism that a highly parallel workload could expose. This would be an interesting direction for further exploration due to the possible need to move execution groups between each of the multiprocessors depending on the overall workload balance of the system such as a high percentage of threads stalled for memory.
4 Results
4.1 Benchmarks
We utilised two benchmarks for purpose of performance analysis: integer matrix multiply and integer convolution, implementing Gaussian blur. Our primary goal of these workloads was to stress-test the memory subsystem and the system's ability to handle branch divergence.
The matrices for both test cases were stored in the program image at launch time to save the need to generate any values. The size of the matrix used for the multiply test case was 64x64 entries and the size of the matrix used for convolution was 128x128 entries. This gives a sufficiently large program size to achieve several million instructions being executed, which allows us to gain a proper sense of how each of the parameters affects the entire lifetime of a kernel.
4.2 Results
We conducted a detailed sensitivity study to better understand the effect that each of the hyperparameters of our design, memory delay, number of blocks, number of warps per block, number of threads per warp, and number of functional units, has on our design. The goal of this tool is to enable us to scope optimal values given the resources that are available. When sweeping a specific variable, we held all of the other variables at the highest value that we swept for that variable because this allows us to minimise the effect that other variables have on our results. By doing this, we more effectively isolate a specific change in configuration and the resulting effect on performance.
4.2.1 Memory Delay
We hypothesised that memory delay would have a significant impact on the overall runtime of the program. Because we did not implement a cache, the arithmetic intensity of both of the kernels is extremely low as each row and column of the matrix is fetched numerous times. While the GPU does have the ability to hide some of the memory latency by scheduling other warps to run while a memory stall is occurring, this is not unlimited especially as the latency becomes higher and approaches the number of warps that are in-flight in the system. Furthermore, fragmentation is a key concern: if any threads in a warp are not actively waiting for a request they will be stuck while other threads are waiting. This means that many runnable threads might be blocked from making forward progress despite that thread not having any specific dependencies that are not resolved.
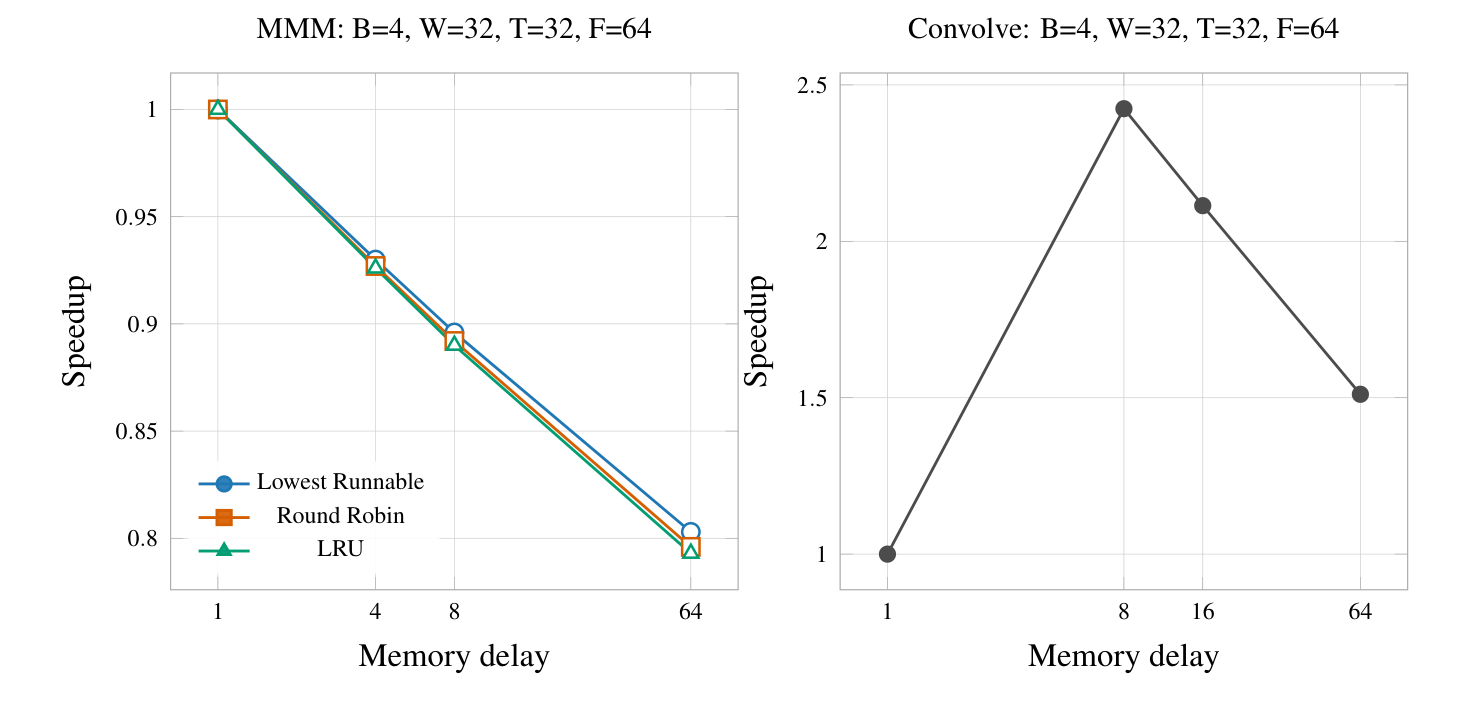
In looking at the results, our hypotheses are satisfied. This trend is particularly clear in the MMM benchmark where there is a clearly decreasing trend in speedup as the memory delay is increased. We expected that the magnitude of the slowdown would be more significant than was visualised in this data. This optimistic result is likely due to the fact that the configuration tested had a large number of warps and blocks available. By having plenty of other sources of independent work available, the scheduler is able to successfully hide many memory stalls. The speedup that is achieved by Convolve when going from a memory delay of 1 to a memory delay of 8 is not well supported by our predictions. This is likely a result of a longer memory delay forcing the scheduler to pick new blocks and allow them to make forward progress. Past a memory delay of 8, the speedup trend is in line with our predictions and the experimental results from MMM.
4.2.2 Number of Blocks
Blocks are a concern of both the hardware and the software. We wrote our benchmarks to be flexible to the number of blocks that were available using the gdim instruction. A change in the number of blocks could motivate a more effective algorithm with a different work decomposition technique, however we did not consider this when conducting our sensitivity study. This is an interesting consideration from a hardware-software co-design perspective because software is affected by the maximal block dimension permissible and hardware must be scoped to support a sufficiently large number of blocks to attain performance.
We hypothesised that adding blocks would have a significant effect on the runtime of the benchmarks because blocks expose a significant source of parallelism. Unlike threads within warps, which are required to run in lock-step, blocks provide entirely independent work to do. This means that while an entire warp is stalled on a pending memory request, there is other available work that the core can accomplish to keep its functional units busy.
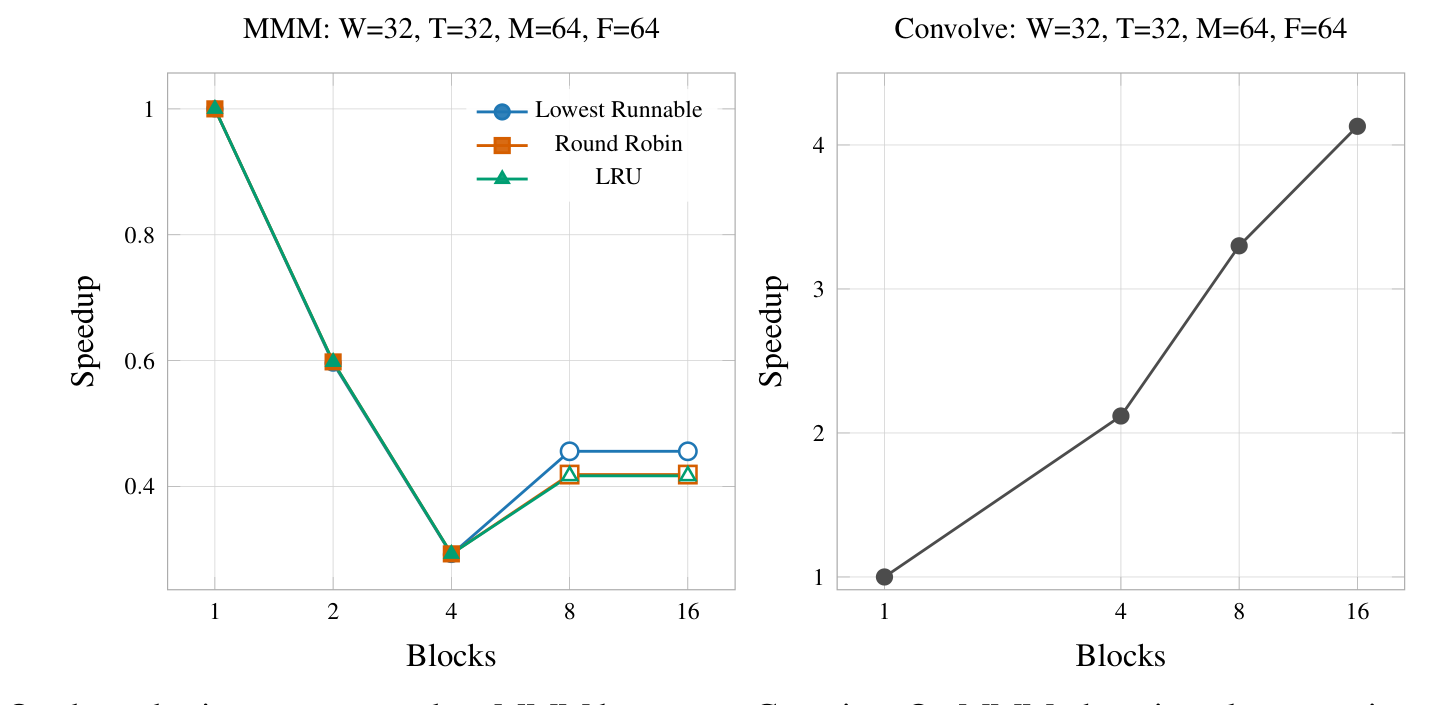
Our hypothesis was supported on MMM but not on Gaussian. On MMM, there is a clear negative correlation between the number of blocks and speedup. However, between 4 and 8 blocks there is a slight bump in performance. This is probably the result of fewer stall cycles wasted where all warps are forced to be waiting for memory. The speedup on convolve is most likely as a result of a greater number of memory stalls compared to MMM due to the lower arithmetic intensity. Because there are more memory stalls, the magnitude of improvement from exposing more parallelism is quite significant.
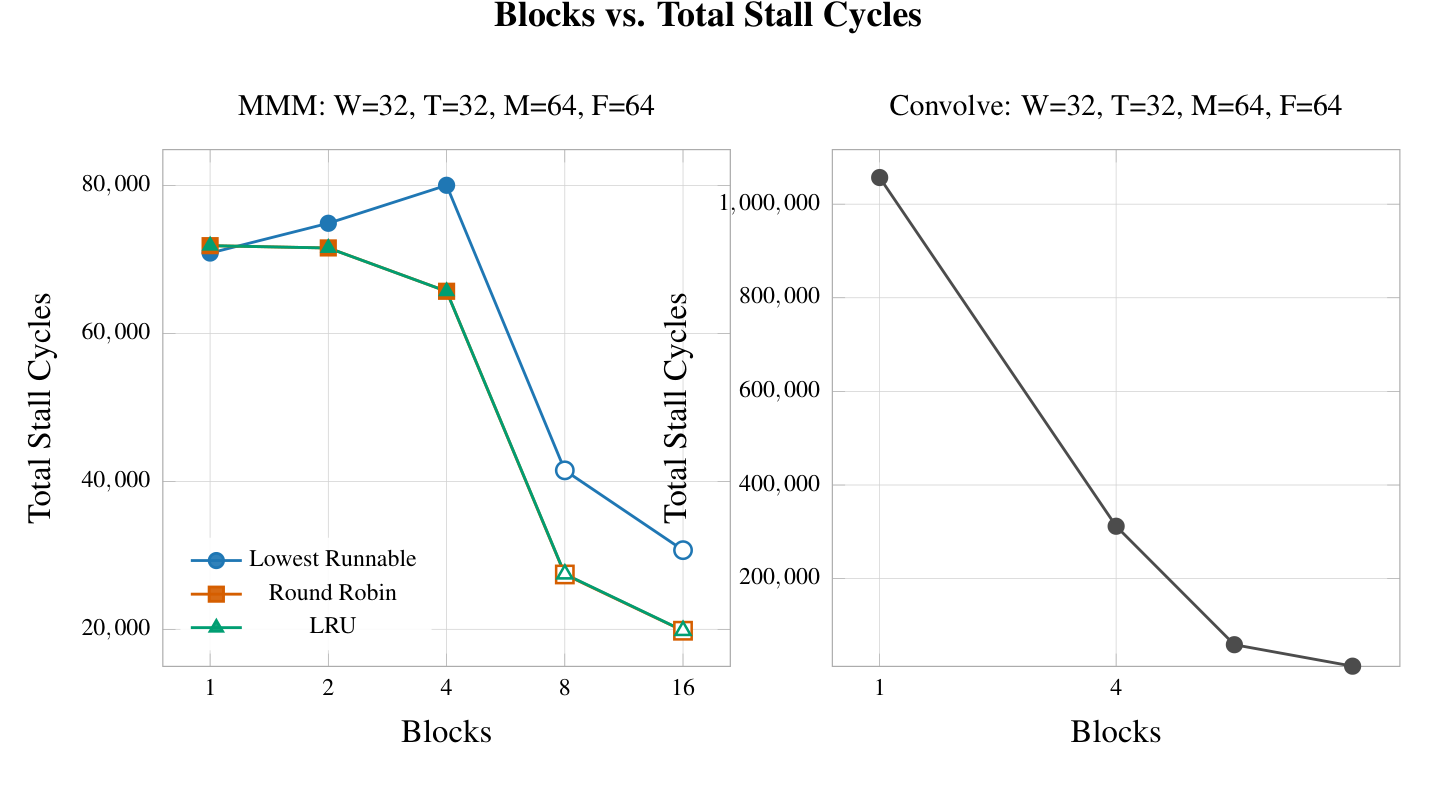
To get a better sense of the change in performance by adding blocks, we quantified the number of cycles without any warps being dispatched to functional units, which happens in the case of a memory stall. Reading the results, it is quite clear that convolution saw a speedup from additional blocks due to the fact that there were fewer cycles without any warps being dispatched. When reading the results for MMM, it was quite interesting to see that for small block counts there is actually an increase in cycles without any dispatches. This is likely due to the lowest runnable scheduler struggling to find work to do because too many potential candidates were waiting for memory. Our earlier hypothesis that moving from 4 to 8 blocks enables more efficient memory latency hiding is again supported by the rapid decline in cycles without issues.
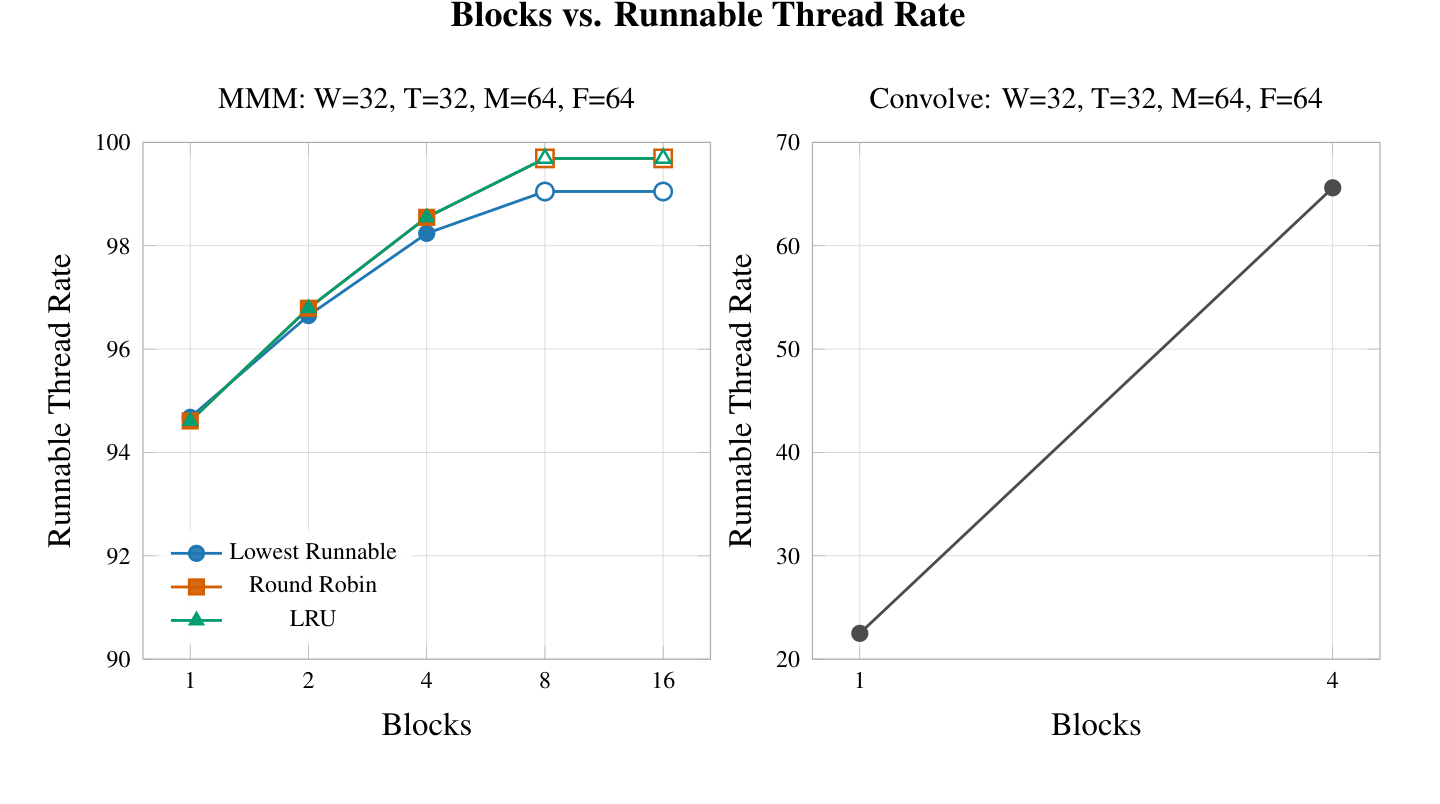
A related metric that we tracked to for cycles without dispatches was the percentage of total possible thread dispatches that were filled with threads. This is a good proxy to understand both branch divergence and memory stalls. In this case, memory stalls are a significant concern due to the memory latency being fixed at 64 cycles. MMM's ability to fill up thread dispatches scaled proportional to the number of blocks is quite reasonable and is in line with the other results that we have presented on the increased parallelism exposed by adding more threads. In this case, convolution saw a significant improvement in utilisation rate likely due to the fact that it is a more memory bound test case.
Despite some encouraging trends in occupancy, MMM still fails to achieve an interesting speedup by adding blocks because blocks only serve to create greater fragmentation in the scheduler and also mean that each block is handling a smaller chunk of the matrix. This exposes more opportunities for branch divergence and other non-idealities to occur. Blocks are a key part of many modern GPGPU architectures because of the high hardware cost of maintaining fewer blocks: larger thread control metadata and memory interfaces would be necessary to realise a design with fewer blocks in hardware.
4.2.3 Number of Warps per Block
Adding more warps to a block exposes more parallelism within that specific block. By increasing the number of warps, the maximum dimension of the block is increased. This is not of significant interest in this particular simulator because all blocks can be mapped to any of the functional units, but does allow us to get a sense of the tradeoff between using larger blocks to save hardware and the associated downside in the form of each block requiring a larger memory overhead to keep each thread context.
Our hypothesis was that increasing the number of warps per block would slow down the runtime. When there are more warps per block, work is concentrated within fewer blocks which makes scheduling a greater challenge. This mirrors the trend that is seen in many systems because adding more warps places more pressure on the same amount of hardware to execute more unique instruction streams.
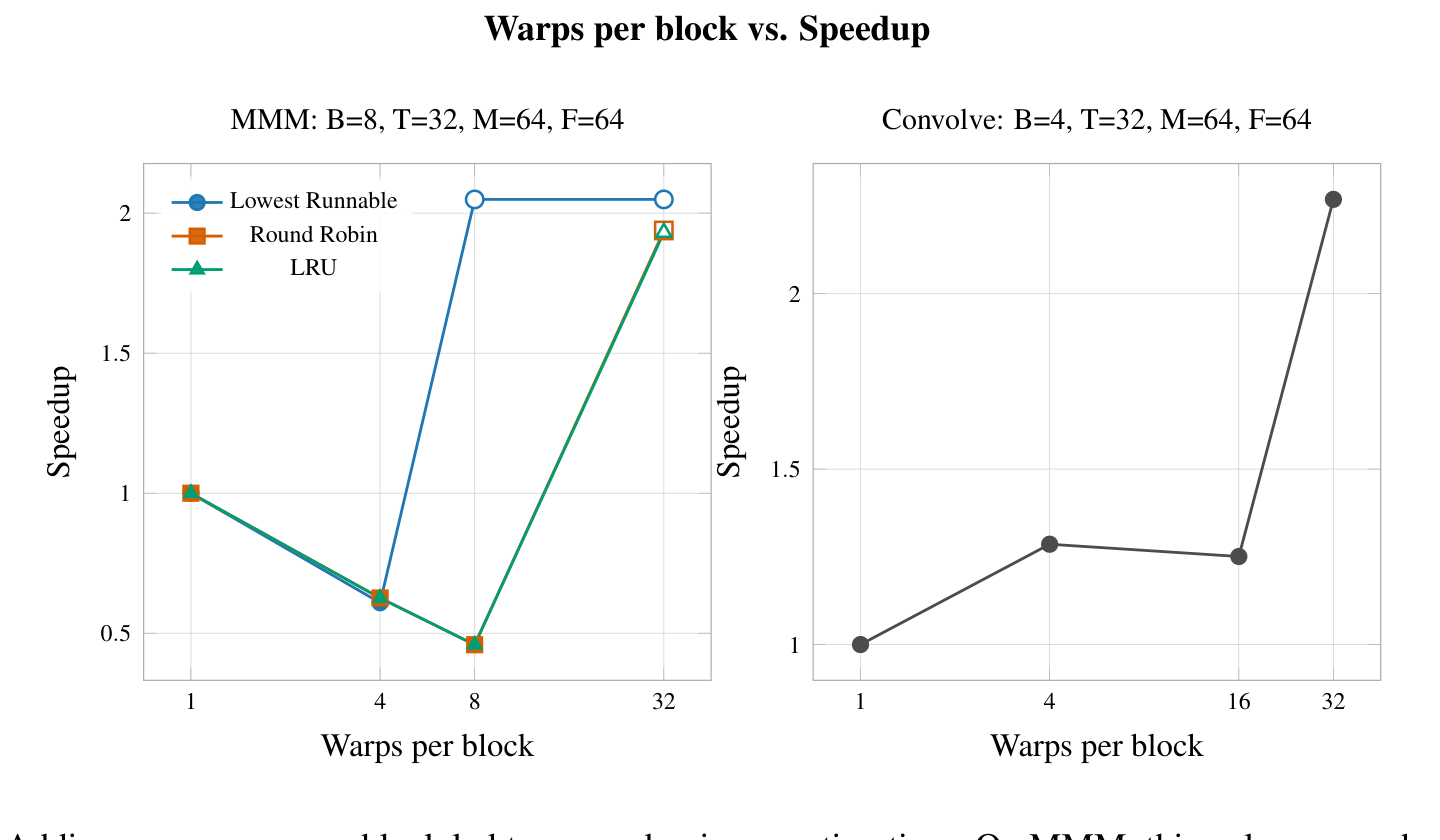
Adding more warps per block led to a speedup in execution time. On MMM, this only occurred once adding enough warps but on convolution this effect was more immediate. An interesting jump that we noted was that lowest runnable achieved a speedup greater than 1 faster than the other schedulers in MMM. This is probably because lowest runnable is more effective when there are more sources of work that can be scheduled from. On the other hand, round robin distributes work suboptimally at 4 threads because it tries to schedule up too many unique warps instead of allowing a single warp to make as much forward progress as possible. Similar reasoning applies to LRU too.
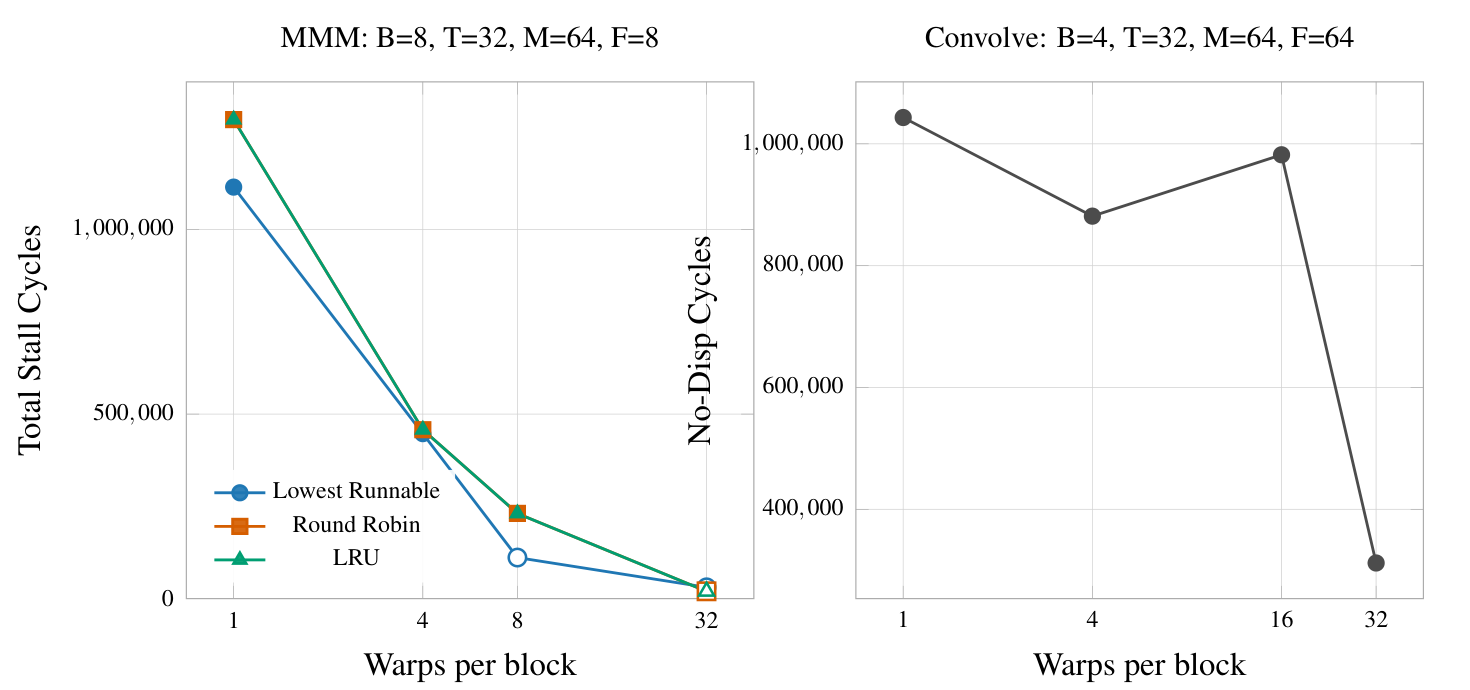
Adding more warps contributed to a speedup greater than 1 in part because there were fewer cycles where all functional units were entirely empty. In MMM, this gracefully rolled off and an interesting speedup was achieved once the number of total stall cycles fell below 250,000 because this allows the GPU to keep new instructions in-flight and avoid idling. On convolution, there was a sharp drop-off between 16 and 32 warps per block. This goes to show that the extra parallelism achieved by adding more warps translates to fewer stall cycles, and, in turn, an interesting speedup.
4.2.4 Number of Threads Per Warp
Adding more threads per warp allows the scheduler to schedule a much greater amount of work in one event because each thread is able to execute its instructions in parallel. In the normal case, this is great for utilisation because more work is getting done in parallel. We also model memory as supporting ideal cooperative fetches because all threads in a warp are permitted to fetch from an arbitrary address on every cycle. This means that more threads are able to get memory requests in-flight per unit time. Unfortunately, branch divergence becomes a significant challenge. As the number of threads increases, it becomes more likely that some threads may resolve down different paths of a branch. In this event, our model requires that all threads advance their PCs before a new group of instructions can be fetched.
Our hypothesis was that increasing the threads per warp would balance out in the middle of our sweep, around 8 threads. Below this, there is more performance available by running more work in parallel. However, adding too much work is likely to cause branch divergence. Because we implemented the simplest correct solution for branch divergence, this will become a significant concern.
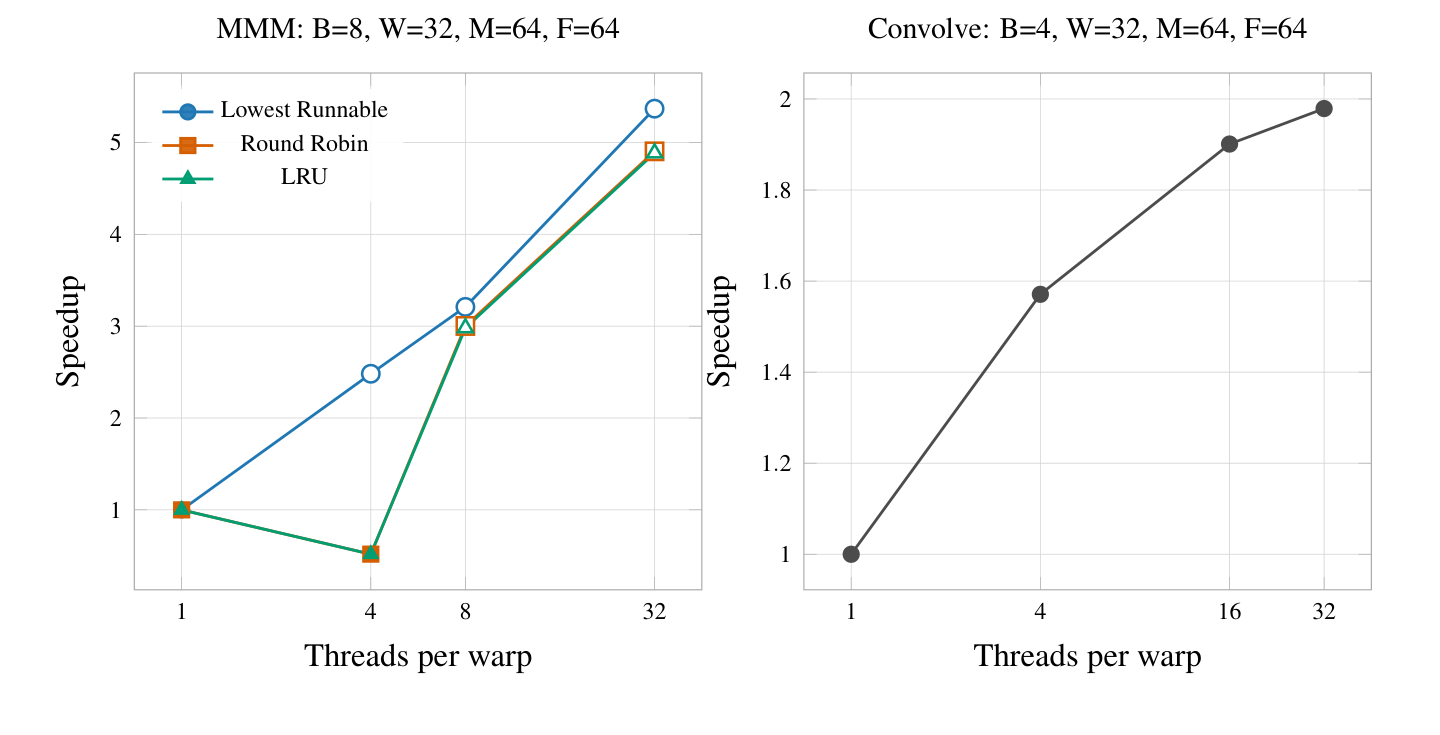
Analysing the results, some speedup scaling continues past 8 threads and is still noted at 32 threads. The speedup is not ideal because of the presence of branch divergence and memory stalls. When adding more threads, there are more opportunities for branch divergence to occur which limits the speedup that can be realised. Memory stalls can also lead to fragmentation if only a few threads are accessing memory and the other threads are blocked waiting for those threads to receive their memory responses.
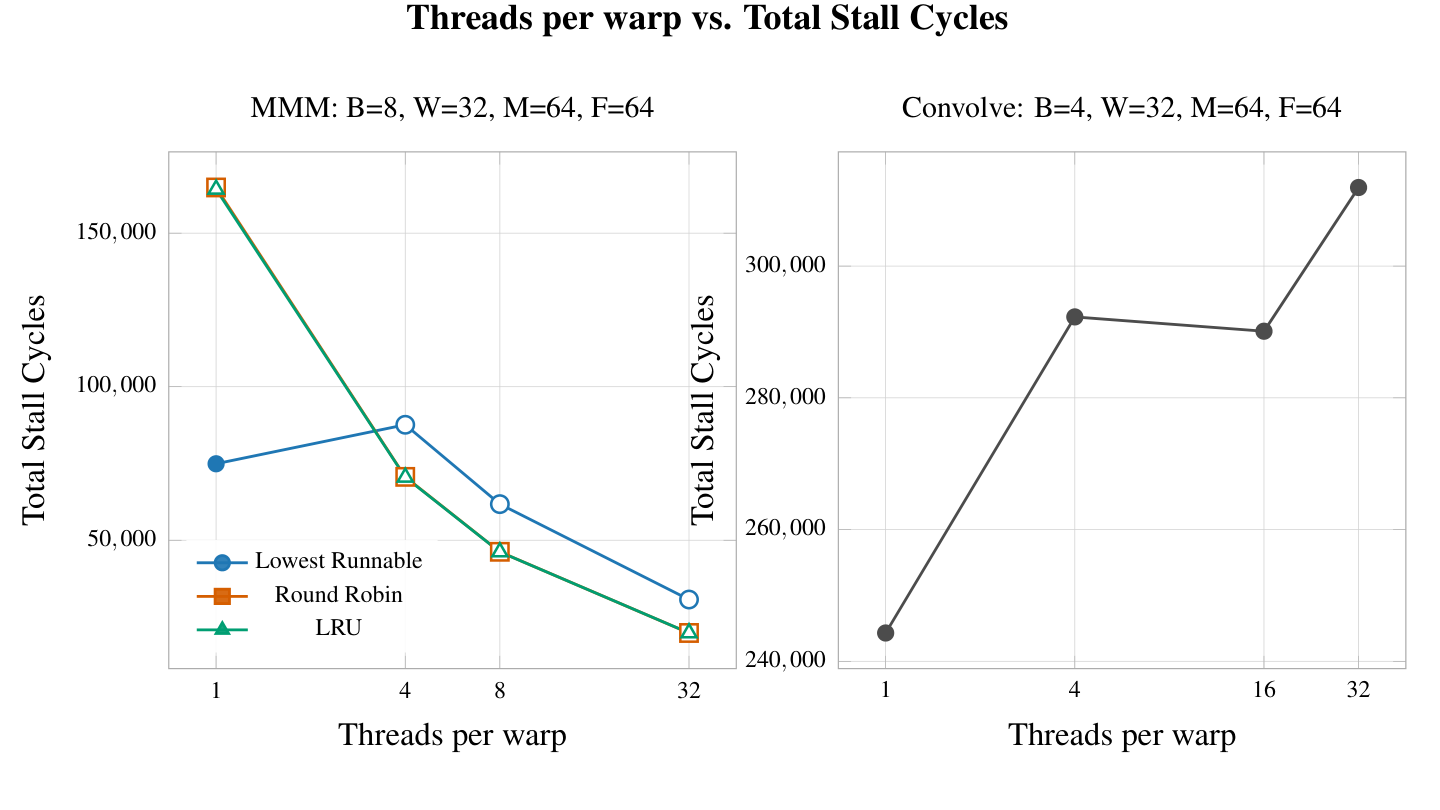
The results from convolution show that increasing the number of threads per warp immediately lead to an increase in the number of cycles without any work dispatched to functional units. This makes perfect sense because of fragmentation present in fetch windows and explains why ideal speedup is not achieved. In MMM, the number of stall cycles actually decreases when adding more threads but the magnitude is quite small at any rate so this is unlikely to have much of an effect in the overall runtime.
4.2.5 Number of Functional Units
Adding functional units enables parallelism to be achieved between warps because each functional unit can execute 1 warp. In our simulation, all functional units can execute all warps: there is no restriction that a functional unit only execute code from a specific block. This makes simulation far simpler and is an adequate approximation given the fairly modest program sizes that we benchmarked.
Our hypothesis was that adding functional units should be strictly beneficial for performance. Given that overall we have seen very high occupancy rates, we assumed that there would be enough independent work to keep the additional functional units fed. Another benefit of the functional units is higher memory bandwidth: all threads that are executed on a particular cycle are allowed to go to memory, and adding functional units has the effect of running more threads.
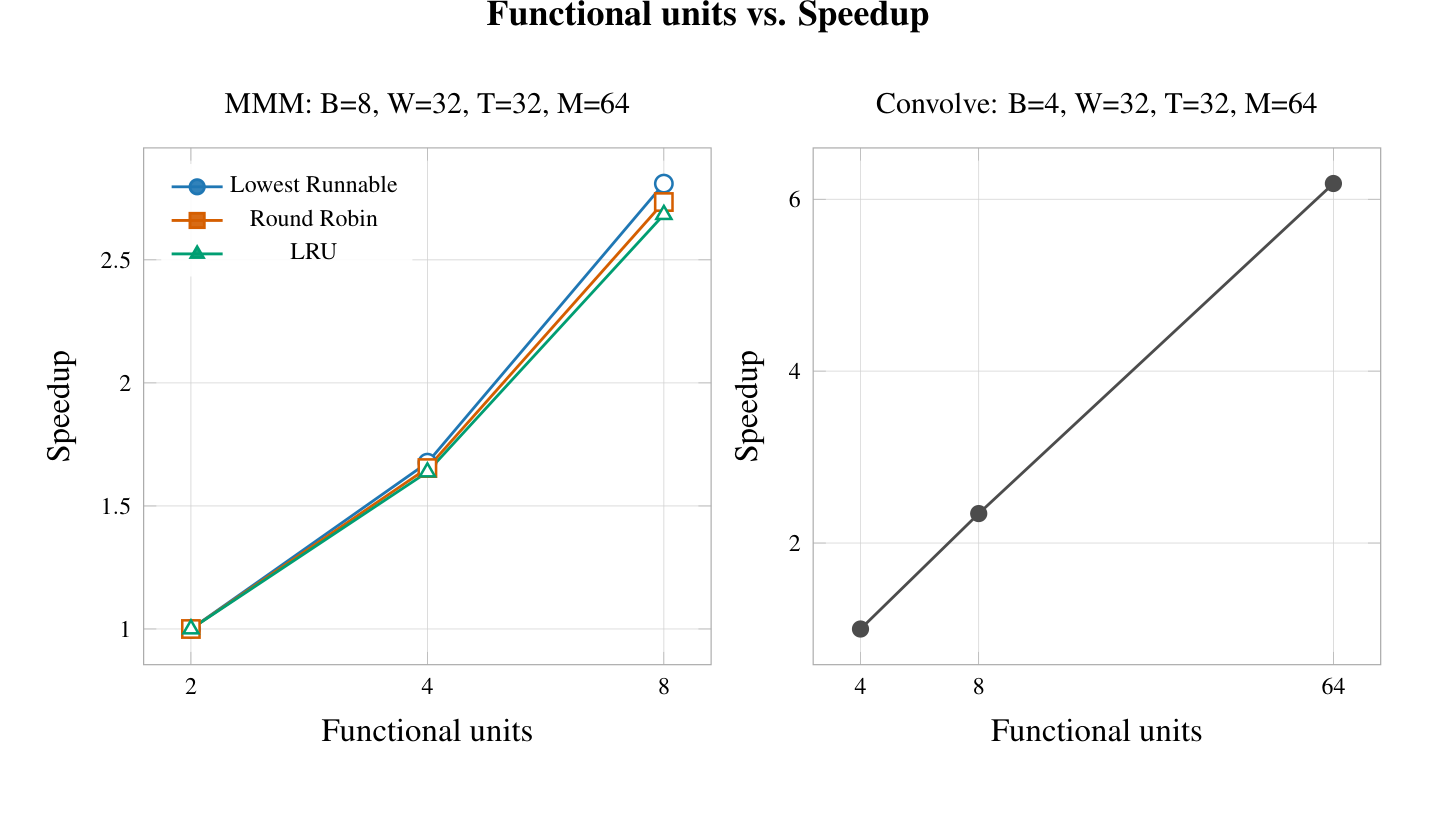
The speedup that was achieved was not ideal. This is most likely because adding more functional units does not necessarily mean that more computational resources will actually be used on any given cycle. Given that both of these tests are very heavily memory bounded, and the memory latency is high, it is possible that simply fetching out of a few functional units gives a sufficient amount of bandwidth to fulfill all the requests that can realistically be generated by all threads without any further progress to unlock more work.
5 Conclusion
We successfully implemented a cycle-accurate model of a GPGPU with sufficient instruction support to execute interesting kernels like matrix-matrix multiplication and convolution. Throughout this process, we paid close attention to instrument the code with performance counters to make overall analysis and runtime data gathering interesting.
Our simulation exposed many non-idealities that affect GPU design like branch divergence and memory latency. Also, owing to the code being a software simulation versus actual silicon there is no way to establish a notion of the actual wall-clock time for any of these designs given the potentially high cost of realising some of them in silicon.
Our biggest take-away was that memory bandwidth is one of the most significant concerns in design. Though memory latency and bandwidth are not typically interchangeable, they are closely related in our specific design and tests. While a typical GPU might hide longer latency by swapping in other threads, we did not expose enough parallelism in the benchmark kernels to allow hiding to occur effectively. Hence, what is typically a bandwidth concern in GPUs was also a latency concern in our specific design.
Branch divergence was another significant issue, limiting the realised speedup of multiple threads and multiple functional units because it means that the real amount of work achieved by the processor on any cycle is potentially far lower than optimal. This was especially noticeable in our convolution workload due to the presence of tight inner loops.
In summary, our design accurately captures the essential trends and limitations of GPU hardware design. Future work should focus on increased realism in the branching and memory logic to allow more optimistic speedups of workloads. More attention should also be paid to creating a large, more diverse set of benchmarks that better isolate the effect of each variable.
6 Work Distribution
All work was distributed evenly. Both Feya and Elisa contributed 50% to the project. Feya was responsible for scheduling, custom instructions and expanding the core from a single cycle CPU model. Elisa was responsible for branch divergence, decoding and benchmarks. All other work was done together.
7 References
S. G. Pandey and S. Gopalakrishnan, "Improving GPGPU Performance Using Efficient Scheduling," 2019 International Conference on Intelligent Sustainable Systems (ICISS), Palladam, India, 2019, pp. 570-577, doi: 10.1109/ISS1.2019.8908051.