Examples of NAF predicted spatial audio (Unmute)
Our approach can achieve plausible spatial audio prediction for an agent moving in a room. Emitter location shown by red dot, agent location shown by green dot, agent trajectory shown in blue dots.
Abstract
Our environment is filled with rich and dynamic acoustic information. When we walk into a cathedral, the reverberations as much as appearance inform us of the sanctuary's wide open space. Similarly, as an object moves around us, we expect the sound emitted to also exhibit this movement. While recent advances in learned implicit functions have led to increasingly higher quality representations of the visual world, there have not been commensurate advances in learning spatial auditory representations. To address this gap, we introduce Neural Acoustic Fields (NAFs), an implicit representation that captures how sounds propagate in a physical scene.

(a): Top down view of a room. (b): Walkable regions shown in grey. (c)-(f): Spatial acoustic field generated by an emitter placed at the red dot.
By modeling acoustic propagation in a scene as a linear time-invariant system, NAFs learn to
continuously map all emitter and listener location pairs to a neural impulse response function that can
then be applied to arbitrary sounds.
We demonstrate that the continuous nature of NAFs enables us to render spatial acoustics for a listener
at an arbitrary location, and can predict sound propagation at novel locations. We further show that the
representation learned by NAFs can help improve visual learning with sparse views. Finally we show that
a representation informative of scene structure emerges during the learning of NAFs.
Method
The spatial reverberation in an environment can be treated as an impulse response. The impulse response can be treated as a function defined on the emitter location (x,y), listener location (x',y'), frequency, time, orientation, and left/right index. As local geometry has a strong effect on anisotropic reflections, we condition our network on a grid of local features shared by the emitter and listener.
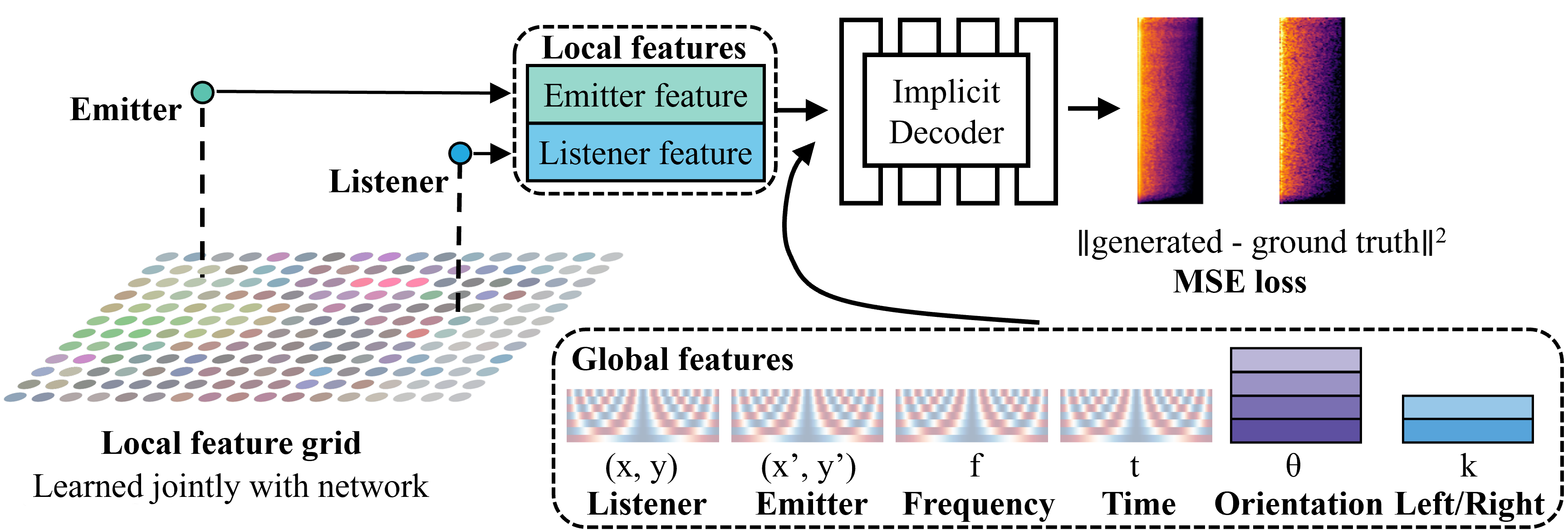
Left: A set of local features that we learn jointly with the network. These features are differentiably queried using the listener & emitter positions. Right: The listener, emitter, frequency, and time are converted using a sinusoidal embedding. The orientation and left/right are queried from a learned lookup table. Please refer to our paper for more details.
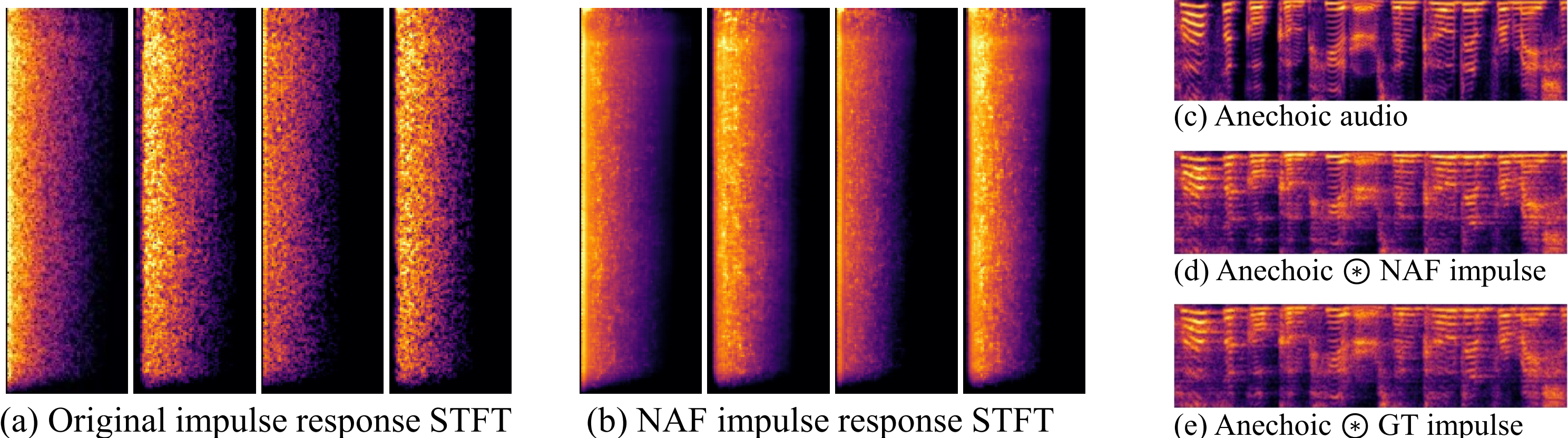
After training, we can present novel listener/emitter locations and query the predicted impulse response. Once queried, spatial audio can be generated by temporal convolution between the anechoic audio waveform and the impulse response.
High quality representations of spatial audio
Given the same set of training samples, our NAFs can represent the spatial acoustic field at higher fidelity than traditional audio encoding methods (opus/AAC) at a fraction of the storage cost.

Compact Storage Footprint
In contrast to traditional methods that require access to the entire training set for inference at continuous locations. Our method can compactly represent the entire acoustic field in the weights of a neural network. To predict the spatial reverberation at an arbitrary location, we can simply use a forward pass of our network.

The above figure shows the average storage required across 6 different rooms. Less is always better.
Visualization of learned features
Here we visualize the features represented by our neural acoustic fields. For each location, we take the feature from the last layer and use TSNE to visualize the features in RGB coordinates. Our features are smoothly varying across space, and show that our networks learn features that are spatially informative.
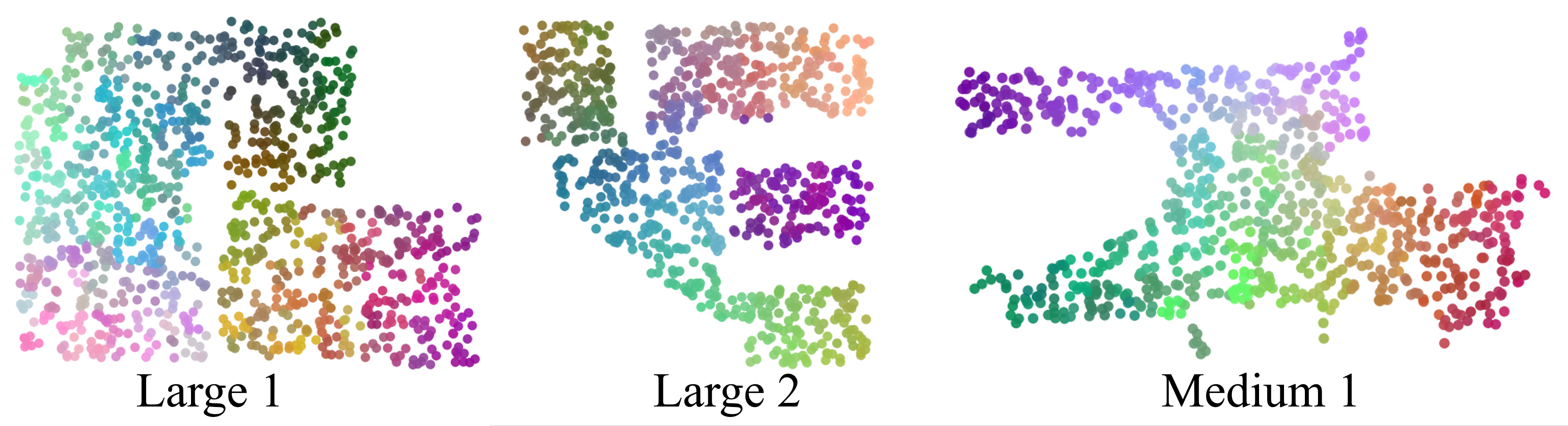
Linear decoding of room structure
Training a linear model on a set of features generated by our NAF, we can perform decoding of the room structure.
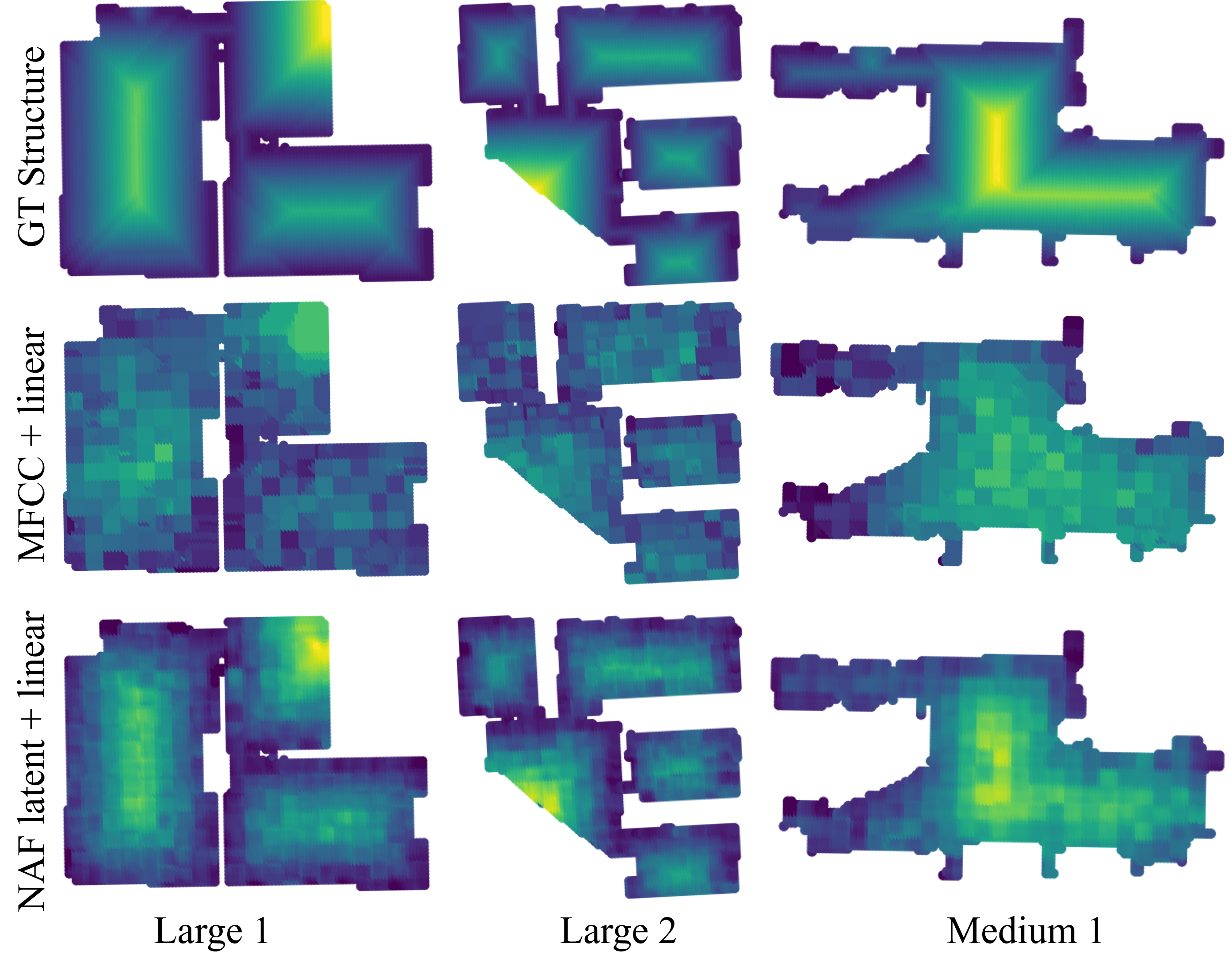
Room structure is represented as distance to nearest wall. After training the respective linear models, We
can better decode room structure using NAFs features than using MFCC (mel frequency cepstral coefficients).
We would like to thank Professor Leila Wehbe for her suggestions on feature visualization and feedback on the paper. We would like to thank the authors of SoundSpaces and the authors of Replica for making this dataset possible. Andrew is supported by a graduate fellowship from the Tianqiao and Chrissy Chen Institute.