Software Quality in Unbounded Networks
Lecture - November 3, 1998
Lecture Notes Taken by: Adam Landman
Outline:
Finish performance issues
Talk about how we measure performance and what the implications are in networks
We can measure time (response, CPU cycles, communications, etc) and storage by an expression of the form:
C0 + C1N + C2N2 + ... + CmNm
where the C’s are constant
and N is a variable essential to the computation (i.e. nodes on the Internet)
Often, we look at the last non-zero coefficient and say the cost is proportional to
this N term.
For example, if the expression has C3, C4, ... Cm =0,
then C2 is the highest non-zero coefficient and we say the expression is O(N2).
How do we keep cost down?
It is sometimes difficult, if not impossible, to achieve O(N).
We therefore look for something in between O(N) and O(N2), usually O(N log N)
The table below, shows that N2 increases much larger than N. We also notice that N log N
tends to behave like N (and therefore is the preferred solution, if N cannot be achieved).
N |
N log N |
N2 |
log2 N |
1 |
1 |
1 |
1 |
10 |
40 |
100 |
3 – 4 |
20 |
100 |
400 |
4 – 5 |
30 |
150 |
900 |
5 |
100 |
700 |
10,000 |
7 |
10,000 |
120,000 |
108 |
12 |
232 ~ 109 |
<1011 |
264 ~ 1018 |
32 |
Why are we really concerned about N2?
Consider distributed computations, such as routing, searching, and chat rooms
What if you are only maintaining a local node, do you still care?
You care about costs imposed on you to be considered part of the Internet
You need a router
What if the router is O(N2),
unbounded by the number of nodes in the Internet
Currently, size of routing tables is N log N
Many
sites further manage costs by dividing by a large C (therefore cut out some information
– not
routing
to some locations)
This
can be achieved by looking at address prefixes, which symbolize geography
How do we compute times of sending messages on the Internet?
Number of messages O(p * messages/person)
where p = number of people and is O(N) and messages/person is a
constant
therefore Number of messages = O(N)
Average Path Length = O( log N)
This can be intuitively derived by considering the Internet as a tree.
Even if you add additional connections, the Internet is still best represented by a tree,
but bounded as a constant.
Cost of Routing
Processing at each node depends on the size of message (constant)
Time for hop from node to node is also a constant
We hope that processing is also a constant / message
Therefore, we will assume cost of routing to be a constant/message
We can then express
Total Cost = Number of Message * Path Length * Communication Costs *
Message Size
Total Cost = O(N log N)
Therefore cost achievable in a single node
= O(N log N) / N = O( log N) cost per node
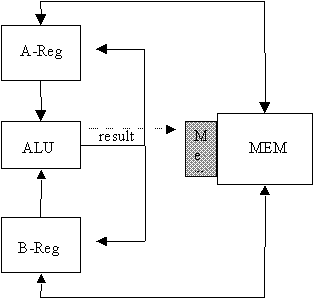
Returning to Architectures
The basic CPU architecture is shown below:
Several different instructions architectures are used on top of this base CPU architecture, including:
Example 1: Computation on a RISC Machine:
X ß Y[ I+3 ] * (Z – 2)
| Step | Instruction |
| 1 | Mem[I] à Reg A |
| 2 | 3 à Reg B |
| 3 | A + B à A |
| 4 | Mem[Y] à B |
| 5 | A + B à A (address Y[ I + 3]) |
| 6 | Mem[A] à A (value of Y[I + 3]) |
| 7 | Mem[Z] à B |
| 8 | A à T (temporary location / other register) |
| 9 | 2 à A |
| 10 | B– A à B |
| 11 | T à A |
| 12 | A * B à A |
| 13 | A à Mem[X] |
Summary of RISC computation:
Program Fetches 13 * 32 bits
Data Fetches 5D + 2T
Example 2: Computation on 3 Address Machines:
Note: A 3 Address machine uses 48 bit instructions, consisting of 12 bit operator, 12 bit X operand, 12 bit Y operand, and 12 bit Z operand.
X ß Y[ I+3 ] * (Z – 2)
| Step | Instruction |
| 1 | I + 3 à T1 |
| 2 | Y[T1] à T1 |
| 3 | Z – 2 à T2 |
| 4 | T1 * T2 à Results |
Summary of 3A Computation:
Program Fetches 4 * 48 bits
Data Fetches 11D
Homework: Same Computation on a General Registry Machine
Note: A general registry machine uses a 32-bit address, with an 8-bit operator (OP), 4-bit register (Reg), another 4-bit register (I), and a 16-bit address (Add). A typical instruction might look like:
R1 OP Mem[ Add + I ]