Determine Total Volume of Pedal Crank
![]()
Determine
Total Volume of Pedal Crank
![]()
After the 3D model is created, volume of the part can be determined.
Main
Menu --> Analysis --> Model Analysis
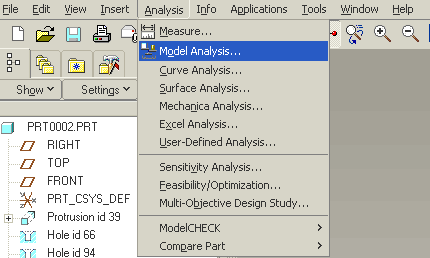
Then click on Compute.
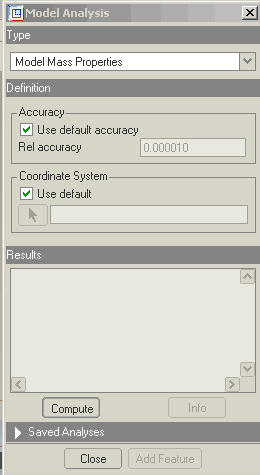
Then enter 0.098lbm/in^3 which is the density of aluminum in the density
box on the bottom dashboard.
![]()
The results should show up on the Model Analysis window.
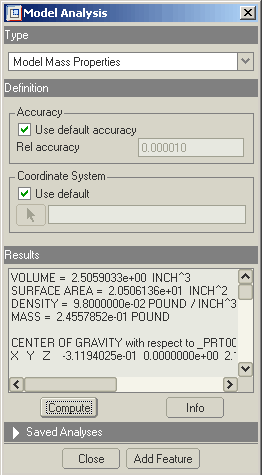
The total volume is 2.51in^3