
Most works in pose-to-body translation space deal with single person activity. For example, Wang et al. 2018, Chan et al. 2019, and Balakrishnan et al. 2018 have demonstrated that it is possible to convert the single person pose maps to dance videos.
While these works have shown stunningly good synthesis outputs, the lack of any experiments on how good are GANs in dealing with multi-person pose synthesis is concerning. Unlike single person interactions, multi-person interactions have interesting occlusions that are caused not only because of camera settings but also because of the inter-person(s) interactions.
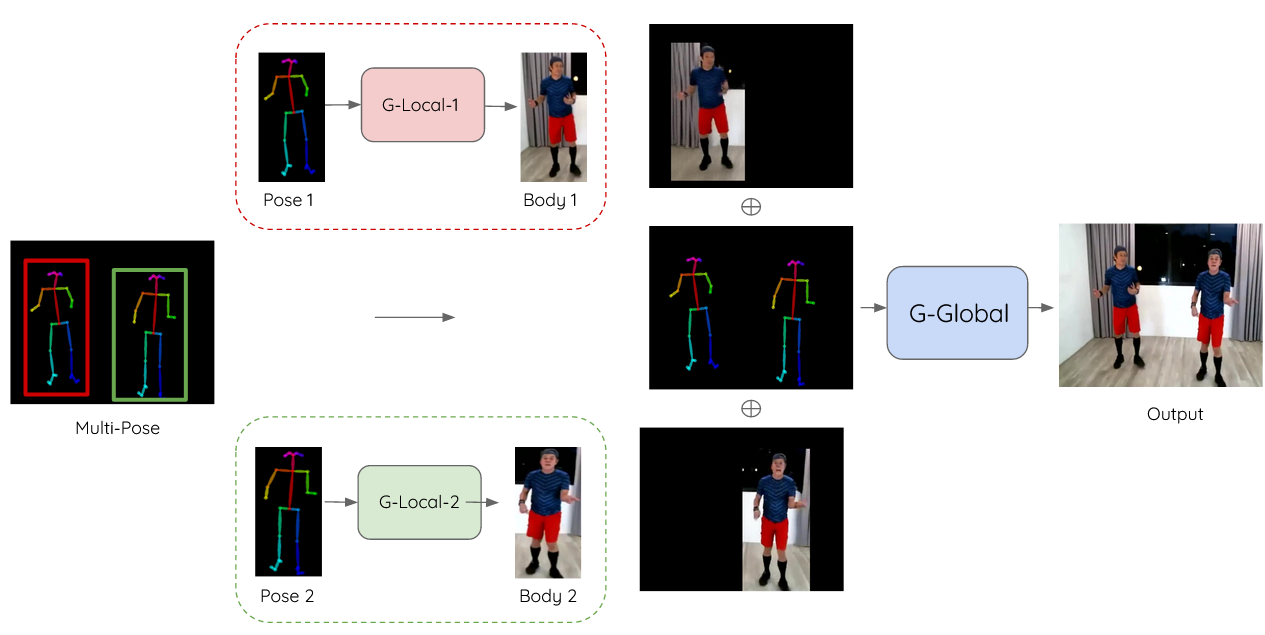
In this project we attempt a two-stage GAN approach to solve for the interaction problem in pose-to-body synthesis for multi-person setting. Our sample multi-pose to body output is presented below:

In addition to challenges in collecting dance videos with no camera motion and static background, we have seen difficulties in
Data
Human-Human interaction
We collected 10 couple videos from YouTube each 3 minutes long. We thus extracted about 3000 frames per video and used 2000 frames in training and 1000 frames in testing. We found that under human-human interaction pose estimators like OpenPose and HRNet failed. Here are some failure cases,
|
|
|
|
|---|

We propose a two stage model to solve for modeling human interactions in multi-person pose maps. The stages include
Local stage(G-Local)
Global Refinement(G-Global)
We discard the temporal dynamics of the frames in the videos. This is due to the large computation resources needed to even run the baseline experiments from methods like Wang et al. 2018. Hence explore only frame-level synthesis.
We use the pix2pixHD model from NVIDIA's opensource code towards our implementation of local generators. The code for our generator and other preprocessing is released here.
We first train the local generators with occlusion-free frames and incorporate the global generator. When training the global generator, we use the checkpoint from the best local generators to train with all the frames(including the frames with occlusion) from given video.
We used 4 NVIDIA's RTX2080ti GPUs to train the models.
We use the pix2pixHD implementation as our baseline and present the results on one of the two videos with most occlusion below. Throughout the rest of the work all our critical analysis is based on this video. Our baselines simply takes the entire pose image and maps it to the rgb image in one step.
 Input Multi-Pose |
 Baseline (Single Stage Translation) |
|---|
We present some results on pose-to-body translation in extreme poses under no occlusion
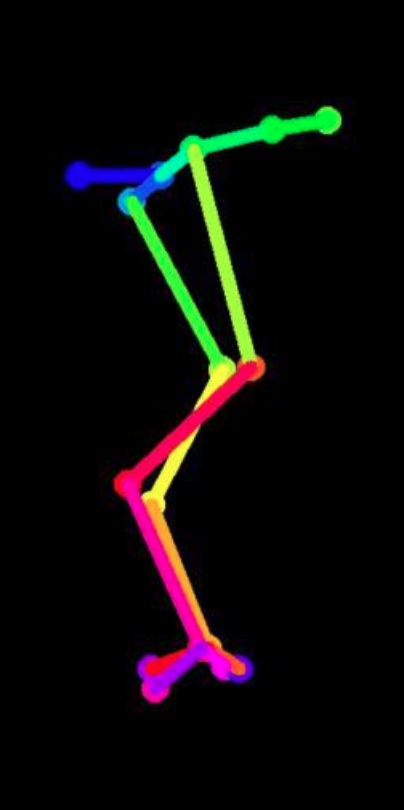 |
 |
 |
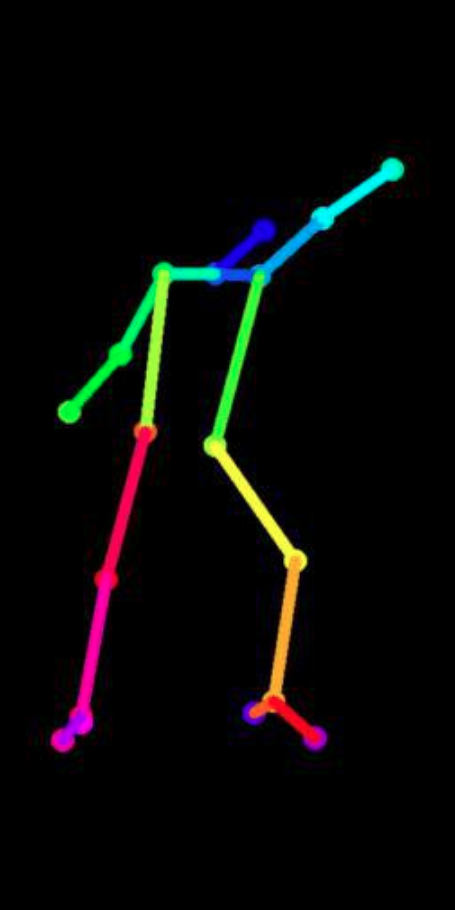 |
 |
 |
 |
 |
 |
In addition, we present the below output from the proposed model. While both look largely similary we notice major differences are in terms of background synthesis and interaction when the dancers swap their positions. Preceptually, we found that the baseline has more inconsistent artifacts over the proposed method. For example, the edge artifacts in the sky have a similar color in the proposed model output over the baseline.
Please refresh to time sync the gifs, make sure everything is on the window.|
Input Multi-Pose |
Baseline (Single Stage Translation) |
|---|---|
 Local Generator Output for Male Dancer |
 Local Generator Output for Female Dancer |

We show qualitatively how the training of the Global generator progresser through various epochs. We train for a total of 50 epochs.





All the videos used for this project are obtained from YouTube.
Recommend viewing the website on 21-inch display or higher for accessibility and better viewing experience.


