Overview
This project combines GAN inversion with closed-form factorization of semantic vectors to produce a working interface for image manipulation. We detail the process, implementation, and results of implementing and training an encoder for image editing, closed-form factorization of latent vectors, and combining the two to produce an image manipulation interface.
Part 1: Implementing and Training an Encoder for Editing
In homework 5, we implemented GAN inversion through a direct optimization problem in the latent space. While this worked pretty well, there were
severe failure cases where the solution to the optimization problem would be a suboptimal vector in latent space which would result in a
blurry, unclear image. Morevoer, directly optimizing the latent code is an expensive process as we have to retrain for every new image we wish to invert.
Designing a direct convolutional encoder for inversion would be much faster at inference time and it's less likely for the inverted output to be
non-interpretable. Designing an Encoder for StyleGAN Image Manipulation, a recent paper from 2021, takes this approach towards the problem of GAN inversion.
First, we desribe the general model and loss functions involved in training. We appreviate the approach as e4e which stands for encoder4editing.
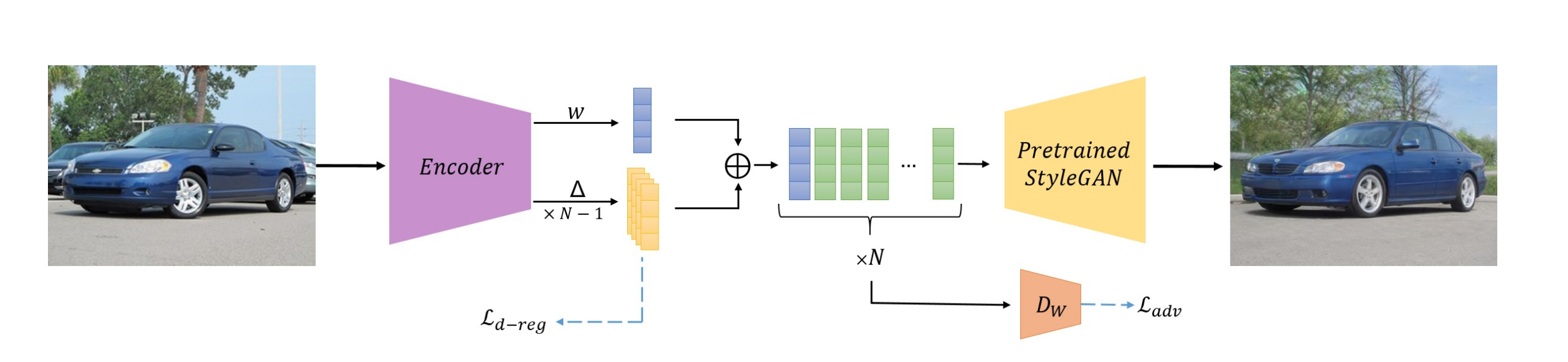 One of the main ideas behind the encoder is that given an input image, it outputs an initial vector in the latent space along with a series of deltas which represent
changes in the StyleGAN latent space. The final inverted latent can be produced by replicating the initial vector multiple times and adding the approriate
delta to each copy. Note that the total number of deltas will be one less than the number of style modulation layers in the pretrained StyleGAN. Designing the
encoder in this way ensures that the prediction for each style latent vector isn't independent of any of the others which constraints the optimization problem.
Additionally, the network is trained in a progressive manner so that it learns to output the initial latent, then the first delta, and so on. In this way,
the encoder is able to learn the inverted latent vectors corresponding to higher level features before it learns the finer level details.
One of the main ideas behind the encoder is that given an input image, it outputs an initial vector in the latent space along with a series of deltas which represent
changes in the StyleGAN latent space. The final inverted latent can be produced by replicating the initial vector multiple times and adding the approriate
delta to each copy. Note that the total number of deltas will be one less than the number of style modulation layers in the pretrained StyleGAN. Designing the
encoder in this way ensures that the prediction for each style latent vector isn't independent of any of the others which constraints the optimization problem.
Additionally, the network is trained in a progressive manner so that it learns to output the initial latent, then the first delta, and so on. In this way,
the encoder is able to learn the inverted latent vectors corresponding to higher level features before it learns the finer level details.
The actual architecture of the encoder involves the usage of gradual style blocks which downsample the input image into the approriate dimension. The gradual style
blocks themselves are composed of convolutional layers with kernel size 3 and pooling with multiple copies, leaky ReLUs for activation, and a fully connected layer
at the end. During training, we add a regularizing term to the deltas to ensure that the latent vectors lie within the approriate space. This is essentially identical
to the regularization trick used in Homework 5 for Scribble to Image.
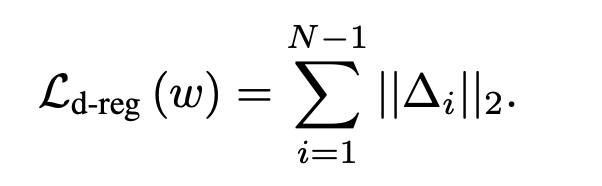 The second main trick used during training is to train a latent discriminator to discern latent codes from the encoder and
real latent codes from the pretrained StyleGAN's mapping function. This also encourages the inverted latent codes to be
similar to those from the true StyleGAN distribution. In practice, a rolling buffer of previously generated codes is also
used when training the adversarial discrminator. The architecture of the discriminator is simply an MLP with several fully connected
linear layers and leaky ReLU activation.
The second main trick used during training is to train a latent discriminator to discern latent codes from the encoder and
real latent codes from the pretrained StyleGAN's mapping function. This also encourages the inverted latent codes to be
similar to those from the true StyleGAN distribution. In practice, a rolling buffer of previously generated codes is also
used when training the adversarial discrminator. The architecture of the discriminator is simply an MLP with several fully connected
linear layers and leaky ReLU activation.
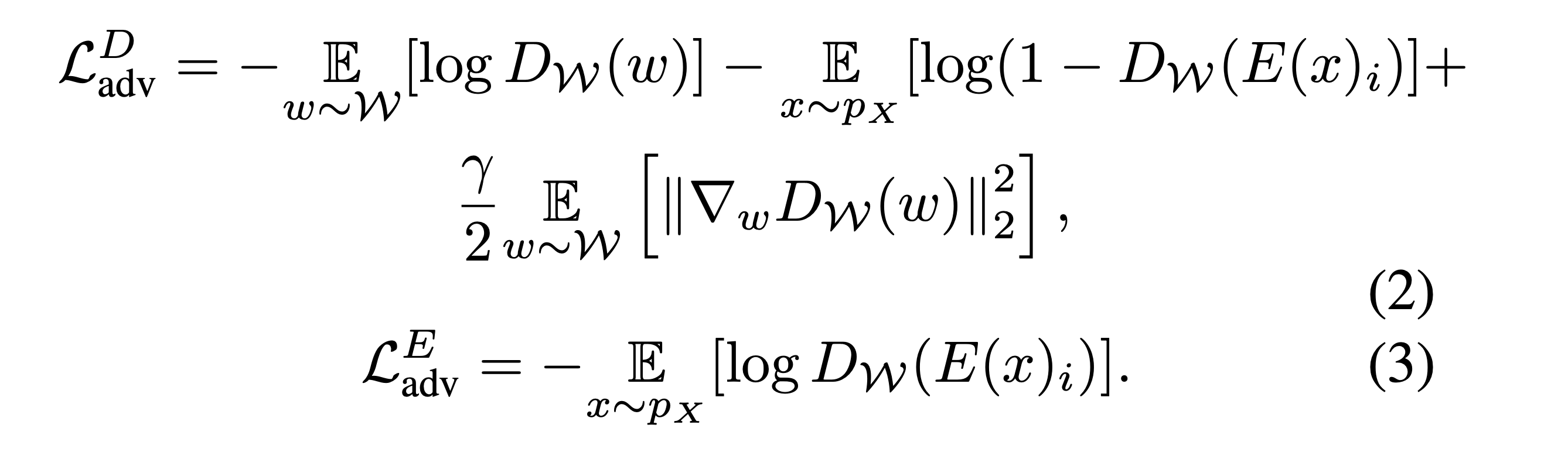 The combination of these two losses results in what the paper denotes the editability loss.
The combination of these two losses results in what the paper denotes the editability loss.
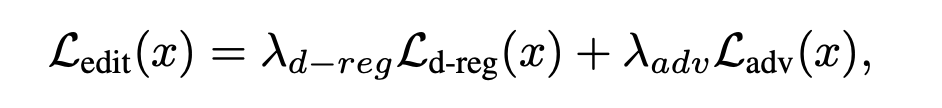 Now, the paper uses 3 separate losses on the generated images from the inverted codes. Two of these are quite familiar:
a pixel-wise L2 loss and a perceptual similarity loss. The third is a novel loss term the paper introduces which they call
a similarity loss. In the case of arbitrary domains, the similarity loss is a feature-wise comparison of the true image
and the generated image from the inverted code using a Resnet-50 trained in a contrastive manner (MOCOv2).
Now, the paper uses 3 separate losses on the generated images from the inverted codes. Two of these are quite familiar:
a pixel-wise L2 loss and a perceptual similarity loss. The third is a novel loss term the paper introduces which they call
a similarity loss. In the case of arbitrary domains, the similarity loss is a feature-wise comparison of the true image
and the generated image from the inverted code using a Resnet-50 trained in a contrastive manner (MOCOv2).
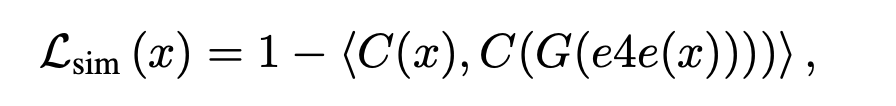 Due to the general nature of the Resnet-50 features, this self-supervised loss can be used for any domain. The authors note that when training
on the facial domain, they use a specific facial recognition network called ArcFace for computing the embeddings instead of the Resnet.
The combination of these three losses form the distortion loss which is shown below.
Due to the general nature of the Resnet-50 features, this self-supervised loss can be used for any domain. The authors note that when training
on the facial domain, they use a specific facial recognition network called ArcFace for computing the embeddings instead of the Resnet.
The combination of these three losses form the distortion loss which is shown below.
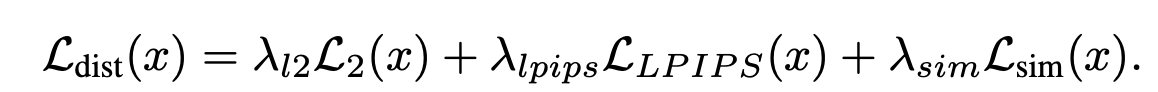 Finally, the total loss of the network is a linear combination of the editability and distortion losses.
Finally, the total loss of the network is a linear combination of the editability and distortion losses.
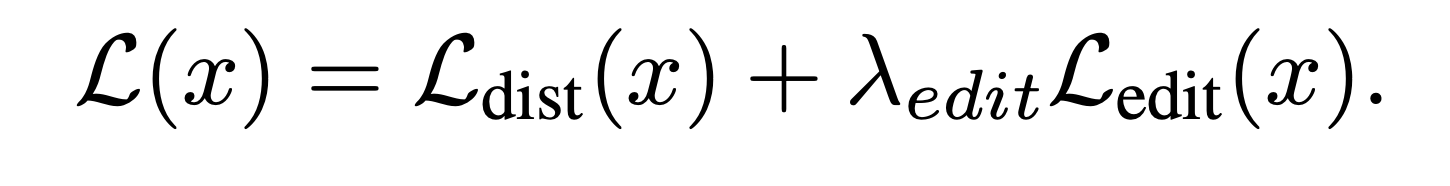 Now, the repository for the original paper provided a pretrained encoder trained on FFHQ, so I attempted to train my own e4e using a
pretrained StyleGAN2 on cats. Unfortunately, the results didn't turn out as well as the pretrained encoder. Thus, for the image editing
interface and results shown in Parts 2 and 3, we use the provided pretrained network.
Now, the repository for the original paper provided a pretrained encoder trained on FFHQ, so I attempted to train my own e4e using a
pretrained StyleGAN2 on cats. Unfortunately, the results didn't turn out as well as the pretrained encoder. Thus, for the image editing
interface and results shown in Parts 2 and 3, we use the provided pretrained network.
Like the paper, I trained on a 42 GB subset of LSUN. Training the cat encoder was a lengthy process as the entire repository was configured for training on a pretrained StyleGAN with specifically named parameters.
Ultimately, I ended up rewriting parts of the training loop and e4e model code to integrate with the StyleGAN2 generator
architecture used in the SeFa repository. The majority of the hyperparamters I used during training were similar to those
described in the paper but I had to use a smaller batch size due to memory constraints of training on a single P100 GPU. I was also only
able to train for approximately 60,000 gradient steps whereas the paper trains for a maximum of 200,000 steps where
only the initial latent is trained for the first 20,000 steps in a progressive manner. Validation results after
training for 60,000 steps are shown below.


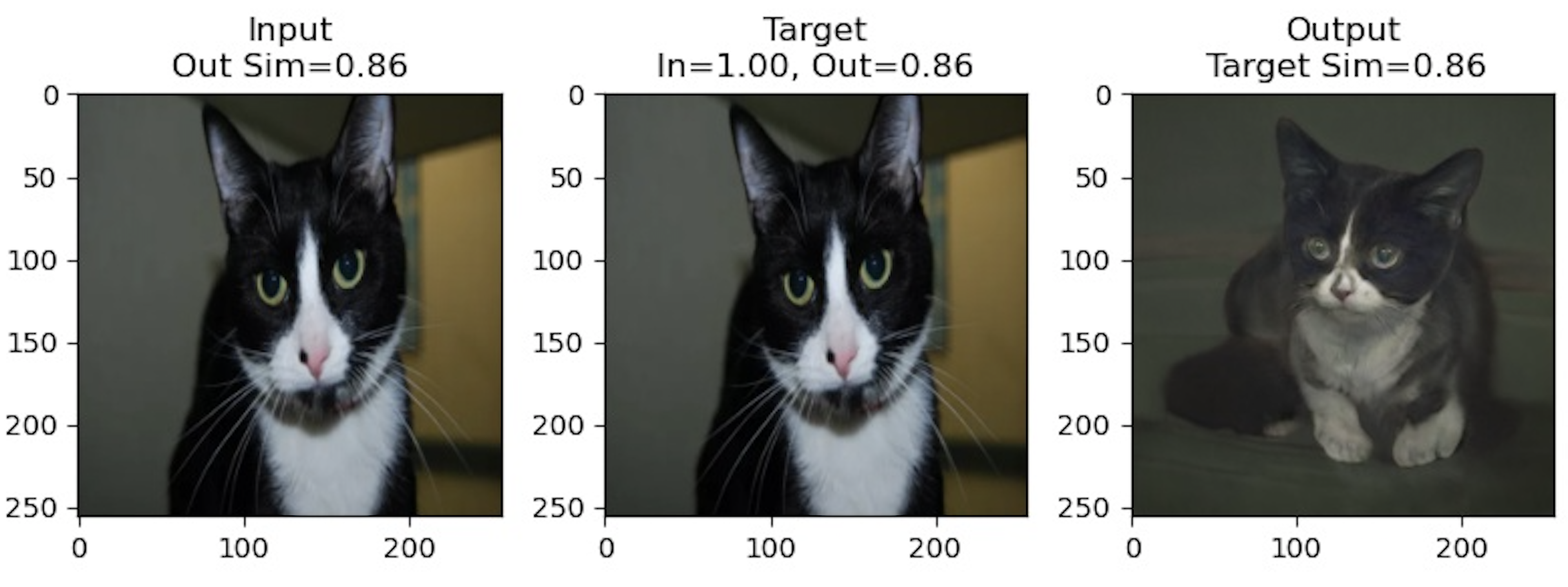
 Notably for these results, the latent produced by the encoder does a good job of encoding stylistic features like color, general
textures, and eye color, but largely fails to capture pose or shape. Instead, all of the generated cats seem to be in a similiar
crouching pose. In some other results shown below, the opposite seems to happen where the latent captures certain features like the
pose but the stylistic features of the cats are completely different.
Notably for these results, the latent produced by the encoder does a good job of encoding stylistic features like color, general
textures, and eye color, but largely fails to capture pose or shape. Instead, all of the generated cats seem to be in a similiar
crouching pose. In some other results shown below, the opposite seems to happen where the latent captures certain features like the
pose but the stylistic features of the cats are completely different.
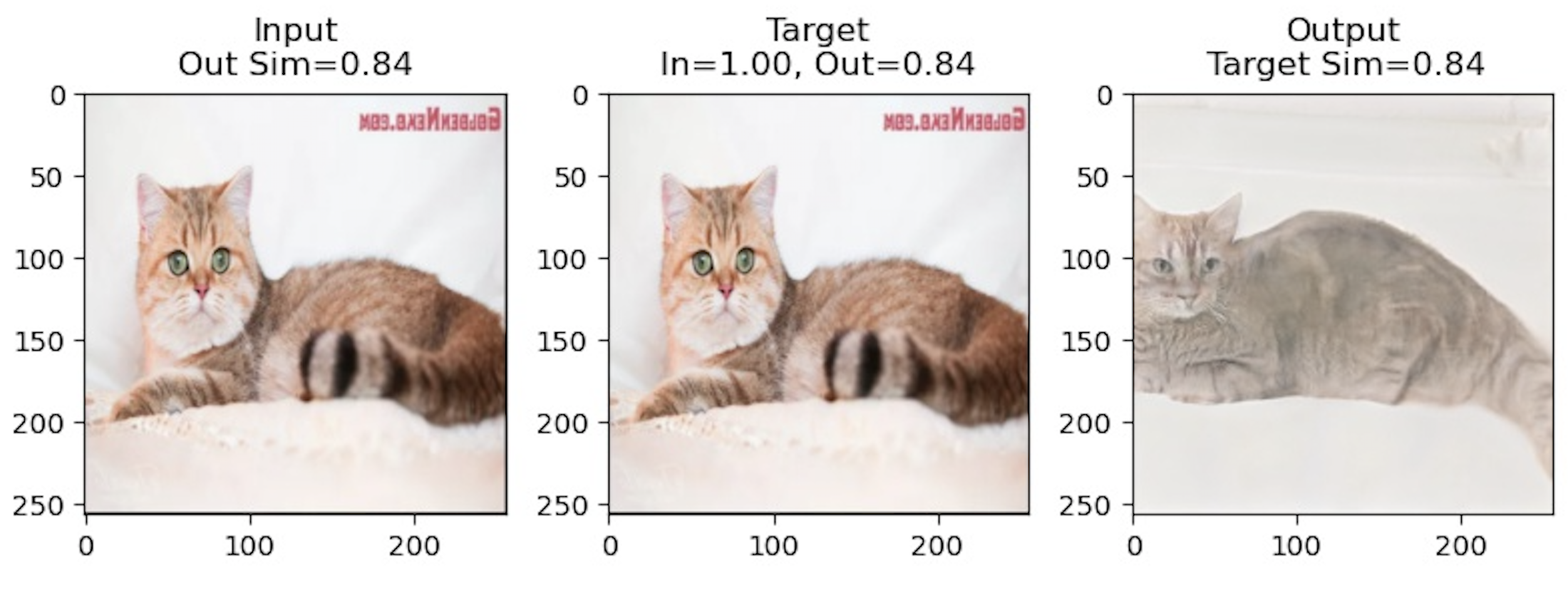

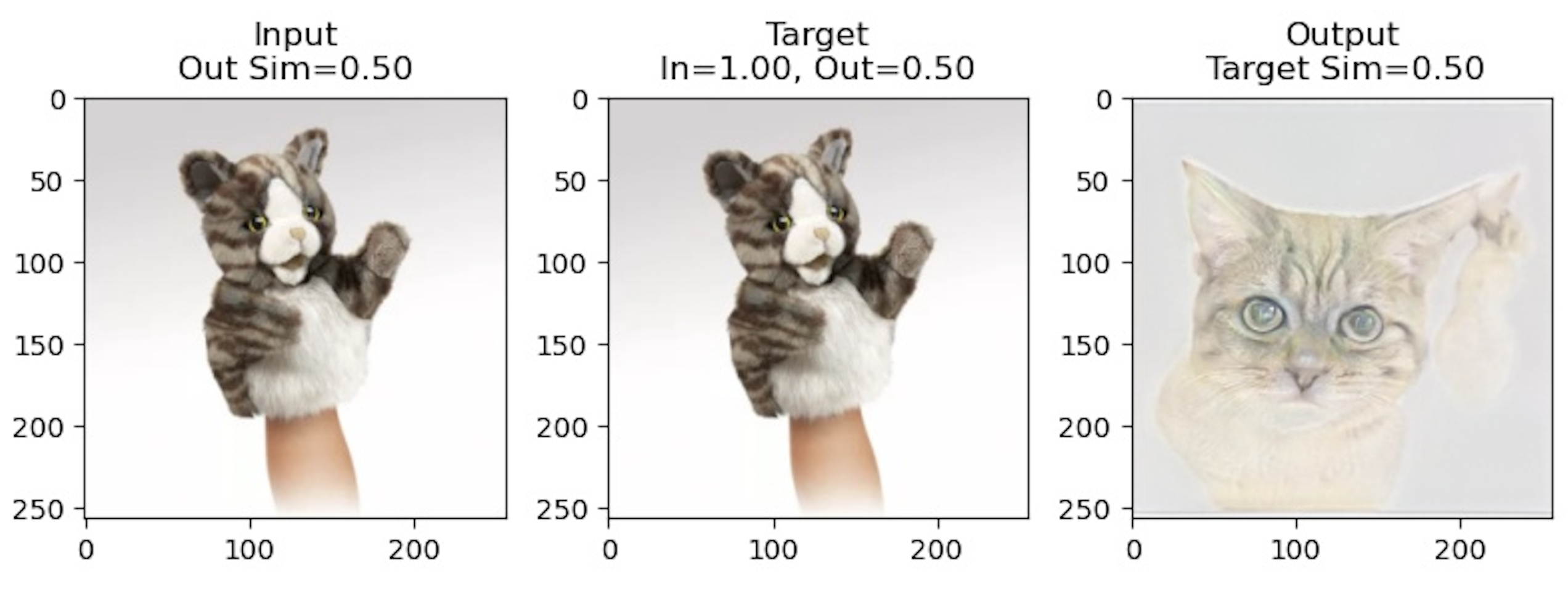
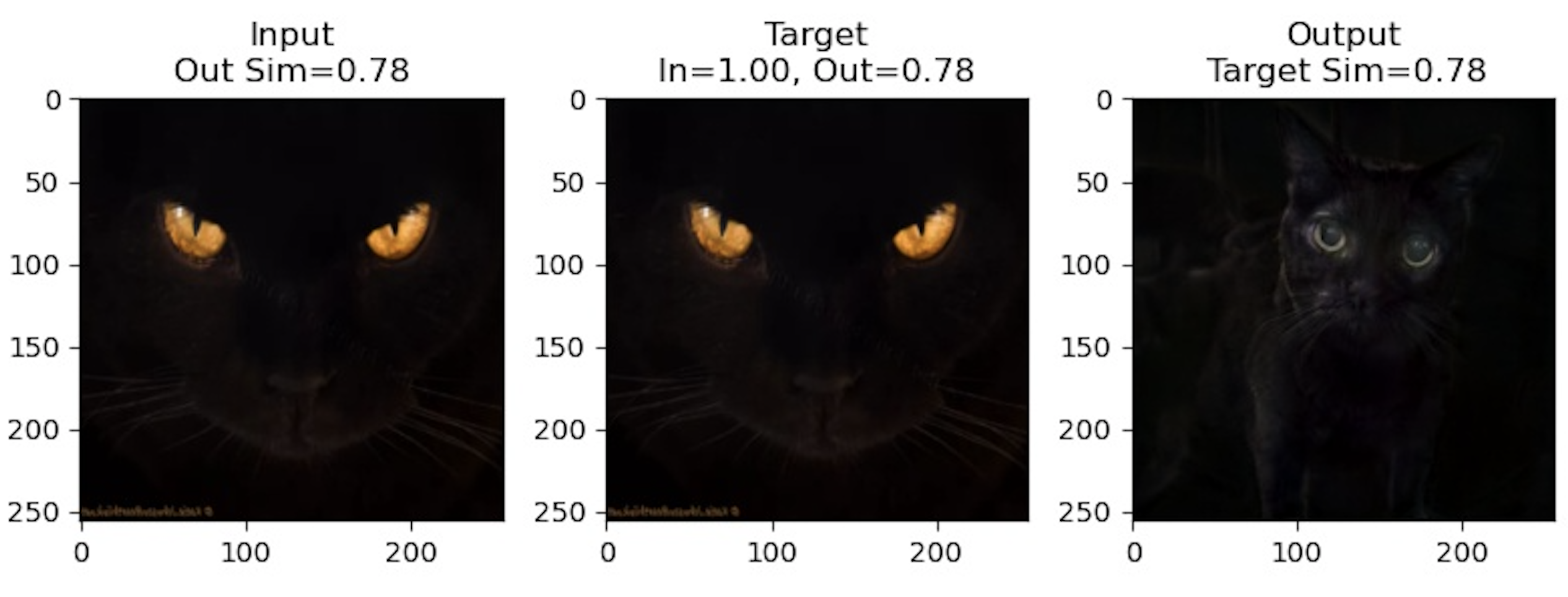 In the first row, we can see that the generated cat
imitates the same pose of lying down and in the third row, the generated cat even seems to be raising a
disconnected paw. The fourth picture captures the general color of the background and cat but the eye color and facial
structure of the cat are quite different. Overall, the inverted results were worse than what I had hoped, but I'm not sure
if it's because I didn't train the network for long enough or if there were issues in how I implemented the models.
In the first row, we can see that the generated cat
imitates the same pose of lying down and in the third row, the generated cat even seems to be raising a
disconnected paw. The fourth picture captures the general color of the background and cat but the eye color and facial
structure of the cat are quite different. Overall, the inverted results were worse than what I had hoped, but I'm not sure
if it's because I didn't train the network for long enough or if there were issues in how I implemented the models.
Part 2: Closed-Form Factorization of Latent Semantic Vectors
The problem of identifying latent dimensions in generative networks for image editing has recently become popular with the introduction of highly interpretable models like StyleGAN. Past supervised approaches attempt to solve this problem by learning a classifier in latent space using some pretrained attribute prediction network along with randomly sampling many latent codes. Conversely, SeFa, short for Semantic Factorization, proposes a fast, closed-form, unsupervised solution. This approach was recently introduced at CVPR 2021, and we leverage it to produce interpretable image edits in our interface.
The simplicity and speed of SeFa makes it an ideal choice for our use case. The idea behind it is motivated by looking at the first
operation performed on the raw latent vector at any layer. The authors note that we can view this as an arbitrary affine transformation
on the latent code. Additionaly, it's common to model image manipulation using vector arithmetic as moving a certain distance
along a semantic vector. Thus, if we combine these two concepts, we can show that the first operation on the raw latent vector at any layer
is instance independent:
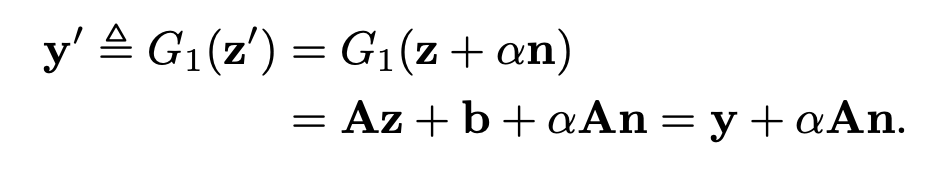 This means the output of the first operation is independent of whatever the inital latent code was. It's only a function of the weight matrix
and the semantic vector. This motivates the key idea behind SeFa which is to solve an optimization problem in latent space where we
aim to maximize the norm of the product of these two quantities.
This means the output of the first operation is independent of whatever the inital latent code was. It's only a function of the weight matrix
and the semantic vector. This motivates the key idea behind SeFa which is to solve an optimization problem in latent space where we
aim to maximize the norm of the product of these two quantities.
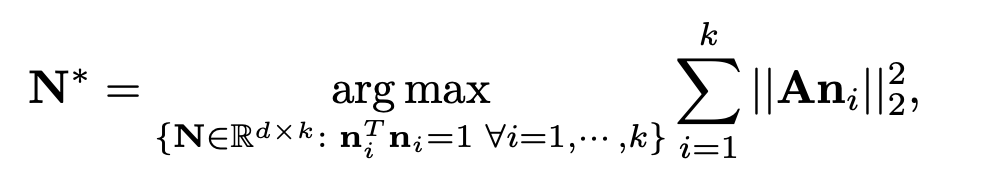 While this is a pretty simple formulation, intuitively if our projected latent vector has large norm, the output of the layer will change by a correspondingly
large amount. Conversely, if our projected latent has norm zero, than our latent has no effect and the first operation in the layer acts as an identity. This
optimization problem is well-known and we can derive the solution as follows:
While this is a pretty simple formulation, intuitively if our projected latent vector has large norm, the output of the layer will change by a correspondingly
large amount. Conversely, if our projected latent has norm zero, than our latent has no effect and the first operation in the layer acts as an identity. This
optimization problem is well-known and we can derive the solution as follows:
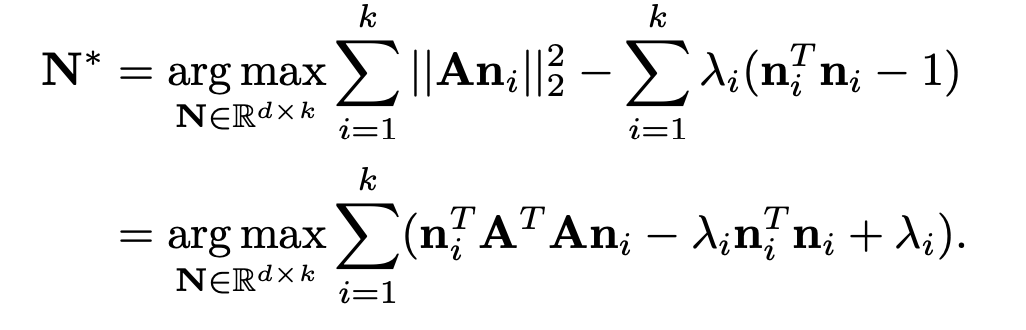 Differentiating shows that the solution is the top k eigenvectors of the transpose of A times A which we can quickly compute using PCA. Another benefit of this
approach is that it allows us to examine the interpretable latent vectors at any subset of layers. We can simply construct our weight matrix A as the concatentation
of the corresponding parameters at those layers. If we consider factorizing and moving along a latent vector across all layers, we see complex changes across
the facial structure, hair, eyes, and more. The example below shows the original inverted face on the left and a progression of moving along an "age" latent vector
on the right.
Differentiating shows that the solution is the top k eigenvectors of the transpose of A times A which we can quickly compute using PCA. Another benefit of this
approach is that it allows us to examine the interpretable latent vectors at any subset of layers. We can simply construct our weight matrix A as the concatentation
of the corresponding parameters at those layers. If we consider factorizing and moving along a latent vector across all layers, we see complex changes across
the facial structure, hair, eyes, and more. The example below shows the original inverted face on the left and a progression of moving along an "age" latent vector
on the right.









Part 3: Developing an Image Interface
The main inspiration for this project was the demo provided by the original SeFa repository where they showcase sampling random latents, generating the corresponding images,
and manipulating it in an unsupservised way. I thought it would be interesting to develop a similar interface where the same process can be done on any uploaded image, not just
an arbtirary or hand-picked latent vector. Thus, the natural way to accomplish this is to combine the inversion process from Part 1 and SeFa from Part 2. I used Streamlit
to build the app and the interface is shown below.
 The interface allows for the user to upload any image of a face, specify the range across layers they wish to factorize over, as well as the number of semantic vectors
to return. Then, the uploaded image will be inverted using e4e and SeFa will be applied to the corresponding weights of a pretrained StyleGAN generator. Modifying the
weights of the returned semantic vectors using the sliders allows the user to manipulate the image however they want. This is how the animations in Part 2
were generated. Although the bottleneck in processing a query is inverting image, this only happens once per new image. A demo
of using the interface is shown below.
The interface allows for the user to upload any image of a face, specify the range across layers they wish to factorize over, as well as the number of semantic vectors
to return. Then, the uploaded image will be inverted using e4e and SeFa will be applied to the corresponding weights of a pretrained StyleGAN generator. Modifying the
weights of the returned semantic vectors using the sliders allows the user to manipulate the image however they want. This is how the animations in Part 2
were generated. Although the bottleneck in processing a query is inverting image, this only happens once per new image. A demo
of using the interface is shown below.

The simplicity of the method means that any pretrained StyleGAN and inversion network can be swapped out and this interface will still work. Overall, I'm satisfied with the final product and in the future, I'd like to explore the results in other domains as well as modifying the interface to support methods besides SeFa.