_________________________________________________________
Final Project - Diversity Matters
Supporting Cultural Representation in Text-to-Image Generation
Zhixuan Liu (zhixuan2@andrew.cmu.edu)
Beverley-Claire Okogwu (bokogwu@andrew.cmu.edu)
Introduction
The importance of representation cannot be understated, especially in the current generated media. In fact, representation has a significant impact on the well-being of individuals. On one hand, positive representation can serve as a source of inspiration and identification for viewers who are able to see themselves reflected in the media they consume. However, negative representation can result in the reinforcement of harmful stereotypes, which can lead to misunderstandings and detrimental effects on individuals and cultures. Therefore, accurate representation in media is crucial to ensure that viewers develop a nuanced and respectful understanding of diverse cultures, free from harmful and inaccurate generalizations.
It has been observed that state-of-the-art text-to-image generation models, like Stable Diffusion, tend to produce images with Western features as their default output. These models also struggle to accurately depict minority cultures in a non-stereotypical and non-discriminatory manner. The root cause of this issue lies in the biased nature of the datasets used to train these models, such as the LAION-5B dataset, which primarily consists of images featuring Western scenes.
Our research is based on the premise that a culturally accurate dataset, even if it is small, can help to counteract the bias inherent in pre-trained models. As a result, we have put forward a novel method for gathering such a dataset. Furthermore, we have explored three distinct approaches for fine-tuning Stable Diffusion model using our culturally accurate dataset. In order to assess the effectiveness of our methods, we have used both automated metrics and human evaluations to evaluate the quality of the output generated.
| Text prompt | Image from generic Stable Diffusion | Image from generic Stable Diffusion |
|---|---|---|
| "A photo of a street" |  |
 |
| "A family is eating together" |  |
 |
| Text prompt | Image from Stable Diffusion with cultural | Image from Stable Diffusion with cultural |
|---|---|---|
| "A photo of a street, in Nigeria" |  |
 |
| "A family is eating together, in China" |  |
 |
Conflict of Interest [!!!]
This project is an expansion of our previous work, titled Towards Equitable Representation in Text-to-Image Synthesis Models with the Cross-Cultural Understanding Benchmark (CCUB) Dataset (arXiv) [1], to which Zhixuan and Beverley-Claire have made significant contributions. It is important to note that it is not a published paper and is not affiliated with any course or research project that Zhixuan and Bev are currently involved in this semester.
In this report, the methods and results presented are unique to the course 16726 final project, and were solely produced by Zhixuan and Beverley-Claire. We may incorporate certain results from our prior work as a baseline or for comparison purposes. However, the primary objective of this project is to address the limitations of previous approaches and develop new, innovative solutions.
Related Work
There are public datasets representing cross-culture text and images. MaRVL dataset [2] is an imaging reasoning dataset which is across 5 different cultures. However, the text data in Marvel dataset mainly describe a coarse semantic information and pay less attention to the cultural features of the corresponding images. Moreover, the text data contains multiple languages, which makes it more challenging for the language process. In comparison, the dollar street dataset [3] is more culturally aware. However, this dataset gives less diverse scenarios. Most of the images in this dataset provide indoor views with limited cultural features, which are not represented for a culture in general.
To make Stable Diffusion more culturally-aware, a comparable approach can be observed in the Japanese Stable Diffusion model, as discussed in a recent blog [4]. This model involves fine-tuning the Stable Diffusion U-Net and retraining the text encoder using a dataset consisting of 100 million images with Japanese captions sourced from the LAION-5B dataset. In our project, we intend to utilize this as a baseline approach and compare our findings to those of the Japanese Stable Diffusion model.
Cultural Dataset Cultivation
Limitation of Previous Work
In our previous work [1], we began by breaking down culture into nine representative categories, such as food, clothing, and architecture. For each culture categories, we recuited one person who personally belong to this culture to collect images and conduct annotations. To date, we have collected approximately 150 text-image pairs for each of the nine cultures. However, we have observed that the cultural dataset generated in this manner is not optimal.
Firstly, given the limited size of the dataset, relying on a single individual can introduce selection bias, which is particularly problematic when dealing with a diverse topic such as culture. Secondly, most cultural experts tend to source their data from online platforms such as Google, which may pose issues with copyright infringement. To address these limitations, we now propose a new protocol for dataset collection.
New Dataset Collection Protocal
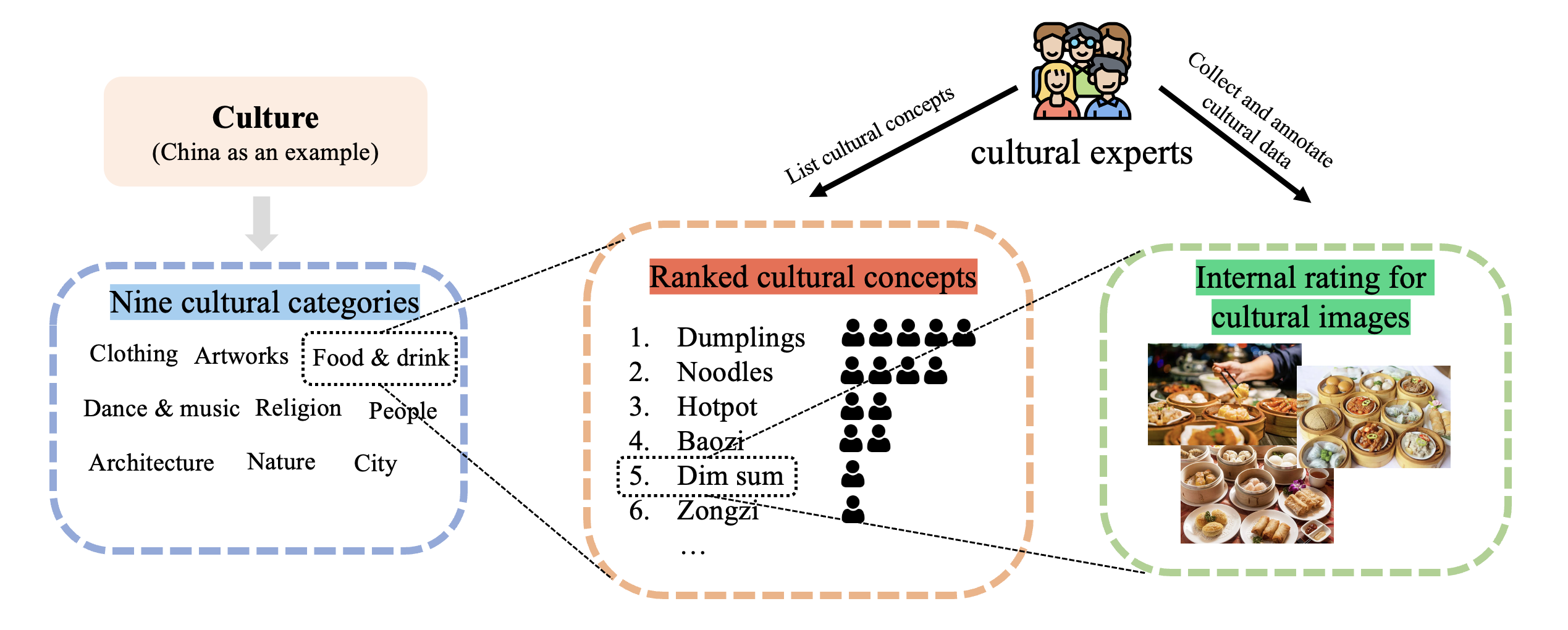
In order to collect and annotate images related to each culture, we plan to hire 5 individuals who are native to that culture. These individuals are referred to as cultural experts. The annotators will mostly be university students, with an equal distribution of genders. Additionally, we will include one elder person to review the cultural dataset in order to balance any age bias.
To obtain the most representative dataset for each culture, we employed a crowd-sourcing approach. Within each culture category (such as "food & drink" in China), we followed a similar procedure as described in reference [2]. Participants were asked to list 10-20 cultural concepts using wikipedia (such as "hotpot" and "dimsum") that are considered "common and popular" in that culture. This approach allowed us to avoid solely relying on heritage, traditions, and folklore. We then obtained a rank list for each culture category and selected the top 15 cultural concepts based on the level of commonality of that category. Next, we asked our 5 cultural experts to select one image for each cultural concept. The images were collected either from Creative Commons licensed imgaes for Google Search or their own photographs, this will aviod copyright issue when the dataset is opensourced. In total, we obtained 5 images for each cultural concept, and then conducted an internal vote where each cultural expert selected one of the best images, except for the image they themselves had collected. Finally, we used the top-voted (one-to-three) images and annotations to construct our cultural dataset.
Cultural Dataset (Chinese example)
Following the new dataset collection protocal, we collect the Chinese culturally-aware dataset. Some dataset examples are shown below, the first row is cultural experts' manual captions, the second row is BLIP [5] automatic captions, which doesn't contains cultural information.
| Cultural maunal caption | cars on the busy road, Chinese style buildings and cypress trees on the roadside | some women dressed in traditional Han Chinese long dresses and holding round hand fans | an old man and two girls making Chinese dumplings together | landmarks and skyscrapers in Shanghai | women in long white dresses playing Chinese classical instruments - guzheng, erhu, pipa |
|---|---|---|---|---|---|
| BLIP automatic caption | cars driving on the busy highway | some women dressed in traditional costume | a family getting food together | the city | a group of person girls in long dresses playing music |
| Cultural images |  |
 |
 |
 |
 |
Culturally-aware Text-to-image Generation
Overall pipeline
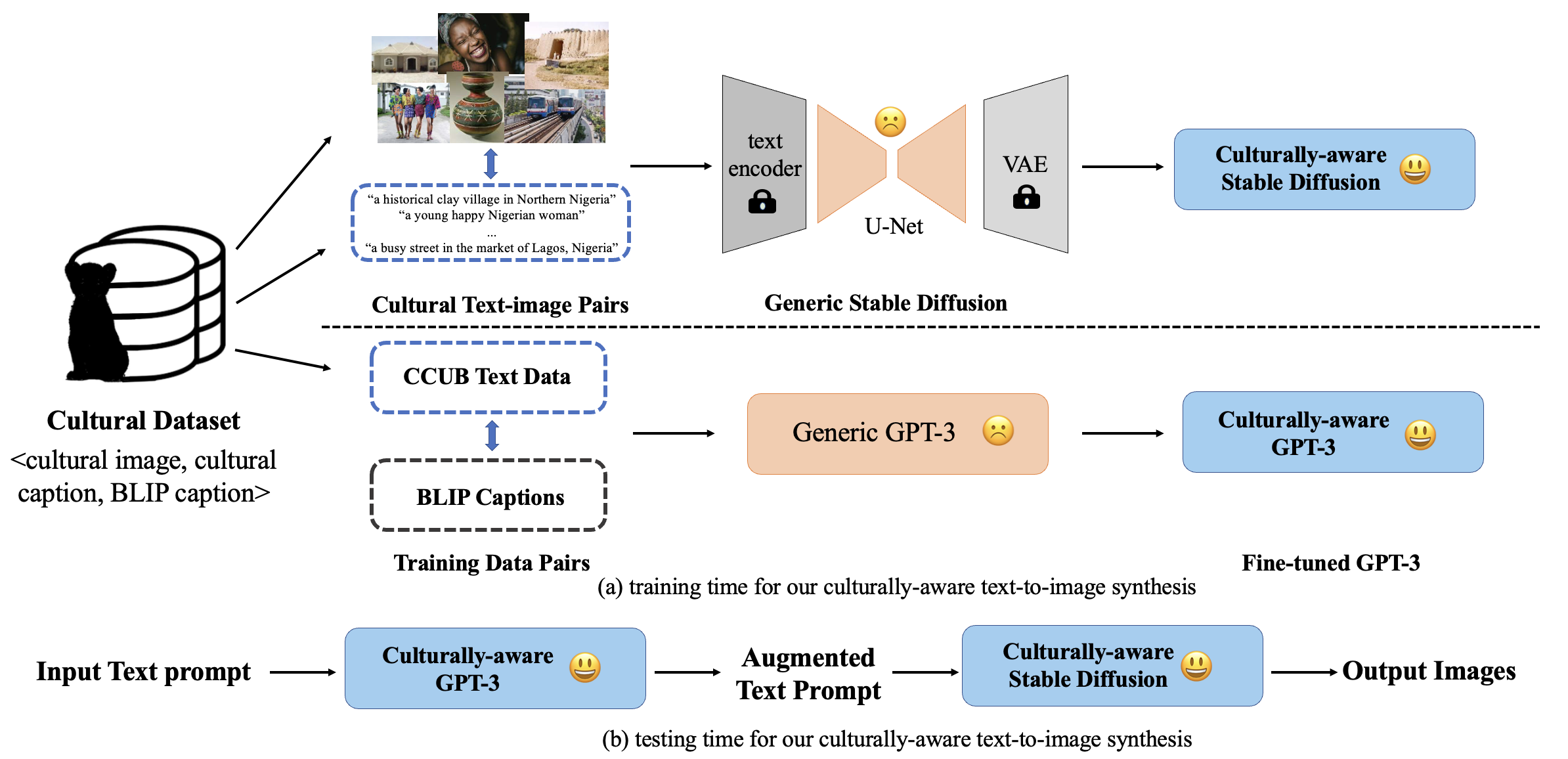
We propose a similar approach to the one presented in our previous work [1] shown in the overview figure below, to use our cultural dataset as a priming approach for both the language and vision parts of text-to-image generation. However, we have identified some shortcomings with the current pipeline, particularly with the Stable Diffusion fine-tuning part.
In this project, we will keep the GPT-3 fine-tuning approach as is and focus on developing a new approach to fine-tune the Stable Diffusion model using our cultural dataset.
Fine-tuning Stable Diffusion using Cultural Dataset - Approach I (our previous work)
Our goal is to adjust the output distribution of the Stable Diffusion model to align with the culturally-accurate dataset we have collected.
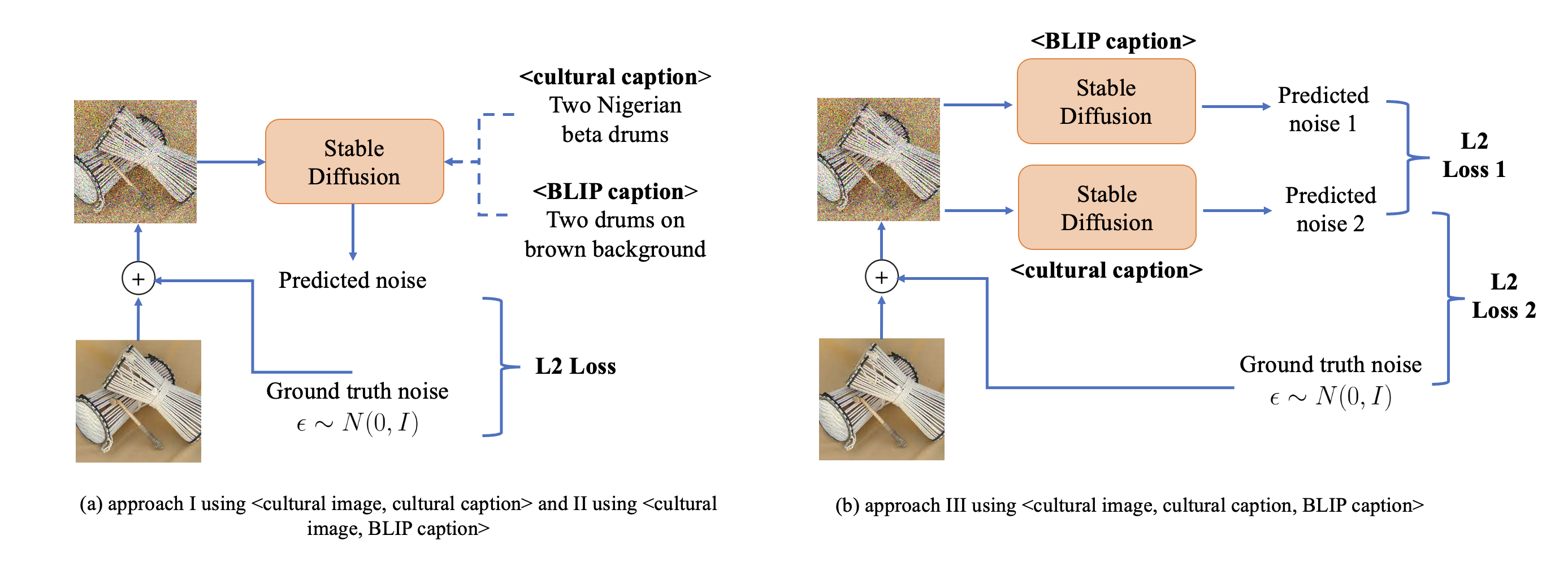
In our previous method [1], we employed a noise-based fine-tuning approach that utilized the cultural dataset (shown in the image (a) below). This approach, which we refer to as Approach I and use as our baseline, is similar to the Stable Diffusion training process but directly utilizes our <cultural image, cultural captions> pairs. During training, the CLIP text encoder and autoencoder (VAE) are frozen, and the U-Net of the Stable Diffusion model is further trained. The fine-tuning of the U-Net is equivalent to the training process of the original Latent Diffusion Models (LDMs), achieved by minimizing the LDM loss over several denoising time steps.
$$ L_{L D M}:=E_{z \sim \mathcal{E}(x), y, \epsilon \sim \mathcal{N}(0,1), t}\left[\left\|\epsilon-\epsilon_\theta\left(z_t, t, c\right)\right\|_2^2\right] $$where \(t\) is the time step; \(z_t\), the latent noise at time \(t\); \(c\), the text encoding of a text prompt \(y\), which are the cultural captions; \(\epsilon\), the noise sample; and \(\epsilon_\theta\), the noise estimating U-Net model.
We have found that this model is capable of generating culturally accurate images with great fidelity. However, we have also observed that the model is highly prone to overfitting due to the limited size of the dataset. As a result, the model tends to generate images that look very similar to each other when given a particular prompt. And we may also find a similar image in the training data.
| "A photo of a street, in China" |  |
 |
 |
 |
| "A family is eating together, in China" |  |
 |
 |
 |
Fine-tuning Stable Diffusion using Cultural Dataset - Approach II
Since we have observed the issue of overfitting, we believe it may be due to the uniqueness and level of detail in the cultural captions. This could cause the model to memorize certain key words in the text prompt, leading it to output similar images when presented with the same or similar text prompts. To address this issue, we propose Approach II, which uses <cultural image, BLIP captions> pairs as the training data instead of <cultural image, cultural captions> pairs. BLIP captions are more general in nature, such as "a city" or "a group of people", and contain fewer cultural details. This makes them more similar to the original training data for the Stable Diffusion model. Apart from this change, the other settings in Approach II are similar to Approach I. The impelementation of Approach II is shown in Figure 3 (a).
We have observed that Approach II has better diversity in generating images compared to Approach I. However, it is still susceptible to overfitting issues. Additionally, we have found it difficult to fully capture and understand cultural concepts through detailed descriptions alone. When given a simple prompt such as "musicians are practicing together, in China," the model tends to generate Chinese musicians playing Western instruments. To address this issue, if we specify the text prompt as "musicians are practicing Chinese traditional instruments pipa together, in China," the model may not understand what "pipa" means and may generate strange-looking objects. This is something that Approach I was able to achieve.
| "Musicians are practicing together, in China" + Approach II |
 |
 |
 |
| "Musicians are practicing Chinese traditional instruments pipa together, in China" + Approach II |
 |
 |
 |
| "Musicians are practicing Chinese traditional instruments pipa together, in China" + Approach I |
 |
 |
 |
Fine-tuning Stable Diffusion using Cultural Dataset - Approach III
Our Approach III is a model-based fine-tuning approach that leverages both cultural captions and BLIP captions. The method overview is shown in Figure 3 (b).
During the training process, the text encoder and autoencoder are still frozen. We only modify the UNet model of the pretrained Stable Diffusion. The loss function consists of two parts. The first part is similar to the Stable Diffusion training process and uses <cultural image, cultural captions>. The loss can be written as follows:
$$ L_{1}:=E_{z \sim \mathcal{E}(x), y\_cultural, \epsilon \sim \mathcal{N}(0,1), t}\left[\left\|\epsilon-\epsilon_\theta\left(z_t, t, c_{cultural}\right)\right\|_2^2\right] $$where \(t\) is the time step; \(z_t\), the latent noise at time \(t\); \(c_{cultural}\), the text encoding of a text prompt \(y_{cultural}\), which are the cultural captions; \(\epsilon\), the noise sample; and \(\epsilon_\theta\), the noise estimating U-Net model.
The second part of the loss function is used as regularization. We aim to generate images using the specific cultural captions that are general enough. One possible way is to make the image generated using cultural captions and BLIP captions similar. This may prevent the model from overfitting. So the second loss function can be written as the following:
$$ L_{2}:=E_{z \sim \mathcal{E}(x), y\_cultural,y\_blip,\epsilon \sim \mathcal{N}(0,1), t}\left[\left\|\epsilon_\theta\left(z_t, t, c_{blip}\right)-\epsilon_\theta\left(z_t, t, c_{cultural}\right)\right\|_2^2\right] $$The objective function for optimizing the UNet model is written as:
$$L_{LDM} = L_1 + L_2$$Qualitatively Results
Some qualitatively experiments for this approach as follows. We first show two images from our cultural dataset with its cultural captions.
| two men doing Chinese martial arts in front of Shaolin Temple | girls in cheongsam playing Chinese pipa and guzheng |
|---|---|
 |
 |
Then we use their cultural captions as input text prompts and tested for 3 approaches.
| Text prompt | Approach | Random image 1 | Random image 2 | Random image 3 | Random image 4 |
|---|---|---|---|---|---|
| two men doing Chinese martial arts in front of Shaolin Temple |
Approach I |  |
 |
 |
 |
| two men doing Chinese martial arts in front of Shaolin Temple |
Approach II |  |
 |
 |
 |
| two men doing Chinese martial arts in front of Shaolin Temple |
Approach III |  |
 |
 |
 |
| Text prompt | Approach | Random image 1 | Random image 2 | Random image 3 | Random image 4 |
|---|---|---|---|---|---|
| girls in cheongsam playing Chinese pipa and guzheng |
Approach I |  |
 |
 |
 |
| girls in cheongsam playing Chinese pipa and guzheng |
Approach II |  |
 |
 |
 |
| girls in cheongsam playing Chinese pipa and guzheng |
Approach III |  |
 |
 |
 |
Based on our current results, we have found that Approach III is better at overcoming the overfitting issue than the previous two approaches, and it is also better at understanding culture when given specific text descriptions. Therefore, in the following quantitative results, we will use Approach III as our final approach.
Quantitative Results
Baseline - Japanese Stable Diffusion
In our previous work [1], we only qualitatively compared our old Approach I with it. So here we conduct quantitative comparision between ours Approach III and Japanese Stable Diffusion. We observed that even fine-tuned on large data using Japanese language captions, it still prone to generate Western looking images by default. We conducted a survey using Amazon Mechanical Turk (AMT) and ask people which images are more cultural accurate, more accurately aligned with text prompt and less offensive. Me comparing our combined approach with Japanese SD. We recruited 10 participants who personally know Japanese culture well (due to some limitations, we could not find this many native people) to perform 331 comparisons. Ours was chosen as less offensive 68% of the time, and more text-image aligned 79% and culturally representative 76%. All results are statistically significant with a p-value of 0.01.
Baseline - Stable Diffusion and Ablation Study
The baseline demonstrates the performance of vanilla Stable Diffusion when using the cultural input as is. Adding the suffix "in [culture]" is a simple yet natural approach for those who are not familiar with the culture.
We conduct a comparison with the baseline as an ablation study of our pipeline: (1) performing only text augmentation (previous work done in [1]); (2) using only the fine-tuned Stable Diffusion model, fine-tuned by Approach III on the collected cultural data; and (3) performing both text augmentation and fine-tuned Stable Diffusion.
A. Automatic Matrices
We leverage the Inception Score (due to time limitations, we didn't choose the FID score, which requires thousands of generated images) to evaluate the quality of the generated images and use the CLIPScore [6] to evaluate the text-image alignment.
| Baseline | Prompt Aug. | Fine-tuned SD | Combined | |
|---|---|---|---|---|
| Inception Score ↑ | 3.43 | 3.32 | 3.31 | 3.28 |
| CLIPScore ↑ | 0.78 | 0.78 | 0.77 | 0.79 |
In the table shown above, our method exhibits comparable image quality (Inception Score) to the baseline and superior text-image alignment (CLIPScore), indicating that our approach does not compromise the original model's image generation capability.
B. Human Evaluation
Due to time limit, we only conduct human evaluation for baseline and ablation study on Chinese culture. We still use the AMT platform and ask similar questions as we compared with japanese-stable-diffusion. We recuited 26 Chinese native individuals and intotal they answered 1069 questions. The results are shown in the table below. The values are the percentage of times that evaluators chose our method over the baseline. All values in the table, except for [Prompt Aug. and Offensiveness] at 50%, significantly differ from 50% at a p-value of 0.01 based on a T-test.
| Text-Image Align ↑ | Cultural Align ↑ | Less Offensiveness ↓ | |
|---|---|---|---|
| Compared to Baseline | N/A | N/A | N/A |
| Prompt Aug. | 0.43 | 0.62 | 0.53 |
| Fine-tuned SD - Approach III | 0.71 | 0.71 | 0.34 |
| Combined | 0.55 | 0.82 | 0.40 |
We assessed inter-annotator agreement, considering comparisons between our method and baseline approaches evaluated by three or more evaluators. The table below shows the average standard deviation between evaluator responses. A value of 0 indicates complete agreement, while 0.5 indicates complete disagreement. Our evaluators generally demonstrated good agreement.
| Text-Image Align ↑ | Cultural Align ↑ | Less Offensiveness ↑ | |
|---|---|---|---|
| Compared to Baseline | N/A | N/A | N/A |
| Prompt Aug. | 0.34 | 0.35 | 0.37 |
| Fine-tuned SD - Approach III | 0.31 | 0.29 | 0.35 |
| Combined | 0.31 | 0.30 | 0.39 |
Baseline - GPT-3
In our previous work [1], we did not investigate the performance of a fine-tuned GPT-3 model. Therefore, we conducted new experiments to address this. We also created a Google form to allow participants to select their preferred augmented prompt. One prompt was generated using the vanilla GPT-3 model, while the other was generated using our approach. We received 525 responses from 18 native individuals on three criteria: cultural representation (67%), offensiveness (66%), and text alignment (72%). The percentages represent the preference for our approach. The results indicate that fine-tuning GPT-3 model on our collected cultural dataset can effectively adds cultural context to a given prompt without compromising its original content and format.
Conclusions
Throughout this project, we identified the limitations of our previous work [1]. To overcome these shortcomings, we developed a new dataset collection protocol and utilized it to gather a culturally-accurate dataset. We then fine-tuned both the GPT-3 and Stable Diffusion models using this dataset. However, we encountered overfitting issues and a lack of generalizability with the original fine-tuning approach. To address these problems, we proposed two new approaches.
Through qualitative and quantitative evaluation, we found that our method shows promise and has the potential to benefit society. Overall, this project represents a significant improvement over our previous work and contributes to the development of more culturally-sensitive text-to-image generation models.
Failure Cases and More Results
There are some failure cases in this model. When you use a simple prompt without cultural appendix or any cultural information, the generated image will still be in western looking. Things will become difference when adding cultural appendix.
| "A family is eating together" |  |
 |
 |
| "A family is eating together, in China" |  |
 |
 |
More promissing results are shown below:
| "A photo of buildings, in China" | "A photo of buildings, in China" | "A photo of buildings, in China" |
|---|---|---|
 |
 |
 |
| "An avocado chair, in China" | "Students are studying in the classroom, in China" | "A fisherman, in China" |
 |
 |
 |
References
[1] https://arxiv.org/abs/2301.12073
[2] https://marvl-challenge.github.io/
[3] https://www.gapminder.org/dollar-street
[4] https://github.com/rinnakk/japanese-stable-diffusion
[5] https://github.com/salesforce/BLIP
[6] https://arxiv.org/abs/2301.12073