Erase-Anything with Text Prompts
Sayali Deshpande [sayalidd]
Overview
The project proposes a pipeline for removing unwanted objects from images using text prompts. The pipeline consists of two components: CLIPSeg for image segmentation using text prompts and LaMa for image inpainting. The proposed method outperforms InstructPix2Pix on various object removal tasks and is effective in removing unwanted objects or parts from images.
Motivation
When editing images, users often want to remove unwanted objects or parts to enhance the image. Existing methods and tools typically require users to create a mask over each object that needs to be removed, which can be tedious if there are many objects to remove. Alternatively, text descriptions could be used to specify which objects to remove, which may be easier and faster in certain cases.
For example, removing crowds or groups of people from photos can be a common task when editing images. However, creating masks around each individual person can be a tedious and time-consuming process. Instead, specifying to remove all people through a text-based command can be a more efficient solution. An automated tool that can understand the command and remove all instances of people in the image without requiring the user to manually create individual masks could be realy helpful in such cases.


There are various other use cases where the ability to remove unwanted objects or parts of an image can be useful. For instance, it can be used to remove watermarks or timestamps from images to improve their appearance. Additionally, it can be used to remove unwanted or out of focus parts of an image, such as blurred or distracting backgrounds, to emphasize the main subject.




Baseline - InstructPix2Pix
InstructPix2Pix is an image editing method that operates using human instructions. With this approach, the model takes an input image and a corresponding text instruction, then edits the image based on the instruction to produce a final output. While this technique can be used for object removal with text prompts, it is not exclusively designed for this purpose and may not always produce optimal results.
We conducted some experiments with InstructPix2Pix and found that there is a considerable room for improvement. As the images below demonstrate, the model occasionally struggles to completely remove the target objects, and in some cases, fails to remove them altogether. Additionally, I observed instances where the model appeared to add objects to the image rather than removing them.
.jpeg)



.jpeg)
.png)
Proposed Method
We propose a pipeline consisting of two components: image segmentation using text prompts and image inpainting.
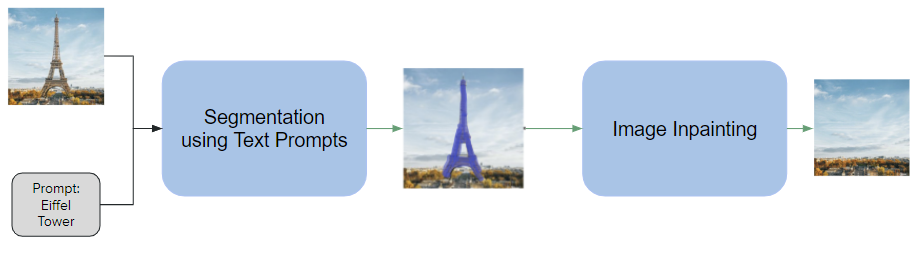
The first component takes an image and a text description of the object(s) to be removed as input, and generates a segmentation mask(s) around the target object(s). The second component takes the original image and segmentation mask as input and fills in the masked regions with plausible content.
Segmentation using Text Prompts - CLIPSeg
CLIPSeg is a flexible zero / one shot segmentation system that uses the CLIP model as a backbone. The system is built upon the CLIP model, which serves as its backbone. With CLIPSeg, it's possible to generate image segmentations using arbitrary prompts at test time. These prompts can take the form of either text or images. However, for the purposes of this project, our focus is on using text prompts exclusively.
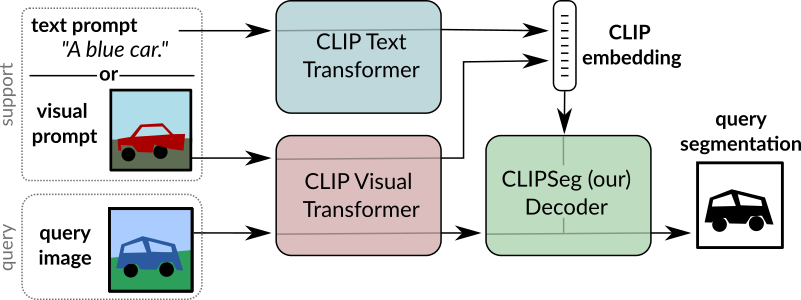
The CLIPSeg architecture builds on top of the visual transformer-based CLIP model (ViT-B/16) by incorporating a compact and resource-efficient transformer decoder. This decoder is specially trained on custom datasets to perform segmentation tasks, while the CLIP encoder remains fixed. This approach enhances the model's ability to identify relevant visual features and accurately segment images, resulting in improved performance on segmentation tasks.
Image Inpainting - Large Mask Inpainting (LaMa)
LaMa: Resolution-robust Large Mask Inpainting with Fourier Convolutions is a state-of-the-art image inpainting technique. The method involves a novel network architecture that incorporates fast Fourier convolutions, which have an image-wide receptive field, as well as a high-receptive-field perceptual loss. Additionally, LaMa leverages large training masks to help the model better understand the global structure of natural images. By combining these elements, LaMa can produce highly accurate inpainting results that outperform other existing methods.
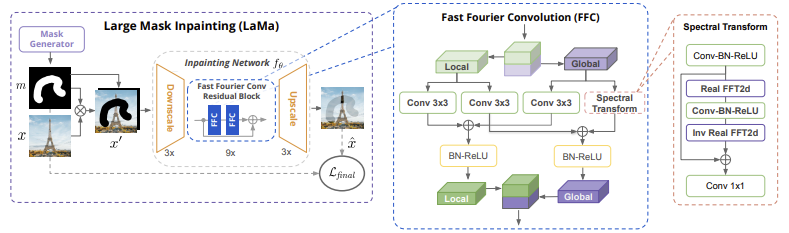
Results
The proposed method has shown to be effective in removing unwanted objects or parts from images, as demonstrated by the results shown below.










.png)
.png)
Failure Cases
.jpeg)
.png)
.png)
.png)
.png)
.png)
Conclusion and Future Work
In conclusion, we have presented a pipeline for object removal in images using text prompts and image segmentation with CLIPSeg, followed by image inpainting with LaMa. Our results show that the proposed method can effectively remove unwanted objects or parts from images, outperforming InstructPix2Pix.
However, there is still room for improvement, particularly in complex scenes with a high number of objects. Future work could involve exploring a combination of CLIP and the latest segment anything model for improving segmentation using text prompts. Additionally, experimenting with other state-of-the-art image inpainting methods such as Repaint, MAT, and ZITS could also be promising avenues for further research.
Overall, the proposed method has great potential for various use cases, including photo editing, object removal, and image enhancement, and we look forward to seeing how it can be further developed and improved in the future.