Generative Co-learning for Image Segmentation
Eric Youn and Robert Skinker
Overview of project: Generative models are currently commonly used for tasks such as image editting and manipulation. Instead, our project seeks to explore the use of generative models as a secondary task during training to improve performance on a main task in a process called co-learning. Specifically we chose image segmentation from near-infrared (NIR) image inputs as our primary task, and NIR-to-RGB conversion as the secondary generative task. Our main hypothesis is that there is information that is being held in the RGB space that a purely NIR pipeline would not capture, and we are using the generation task as a mechanism to force the model to learn an augmented feature space during training that would improve performance in the main task.
Introduction
Background: Co-learning is a process that is typically seen in multimodal (ie vision and text) settings. The primary task in co-learning is typically unimodal, but the model is trained on a secondary task using another modality, in conjunction to the main task, in order to enrich the unimodal features that are generated for the main task. Generative co-learning is just an application of co-learning that uses a generative model for the secondary training task, sometimes allowing for robust multi-modal fusion even though the input may be unimodal. We do not explore fusion in this work, and focus purely on applying lessons learned from class to our generative co-learning problem. Specifically, we explore different architectures and loss functions and analyze their effect on the primary task of segmentation.
Dataset Description: We used the RANUS dataset. This a dataset of urban scenes captured from a vehicle and consists of 20k aligned NIR and RGB images with segmentation masks of 10 classes. Here is an example of what the data looks like:



Basic Architecture: Our architecture can be split into two basic components: the segmentation and generative pipelines. Both pipelines share the same NIR image encoder. We used a pretrained ResNet-50 encoder trained on the COCO dataset and fine-tuned throughout our training process. For the segmentation pipeline, we chose a DeepLabV3 segmentation head, also pretrained on COCO and fine-tuned on our specific task. These two architectures remained fixed and did not change throughout our experiments. The segmentation pipeline is also the only component used during evaluation, as the generative head is only used during training. For the generative pipeline, first we use three transformation residual blocks followed by the generative head. We experimented with two architectures: an encoder-decoder network and a GAN.
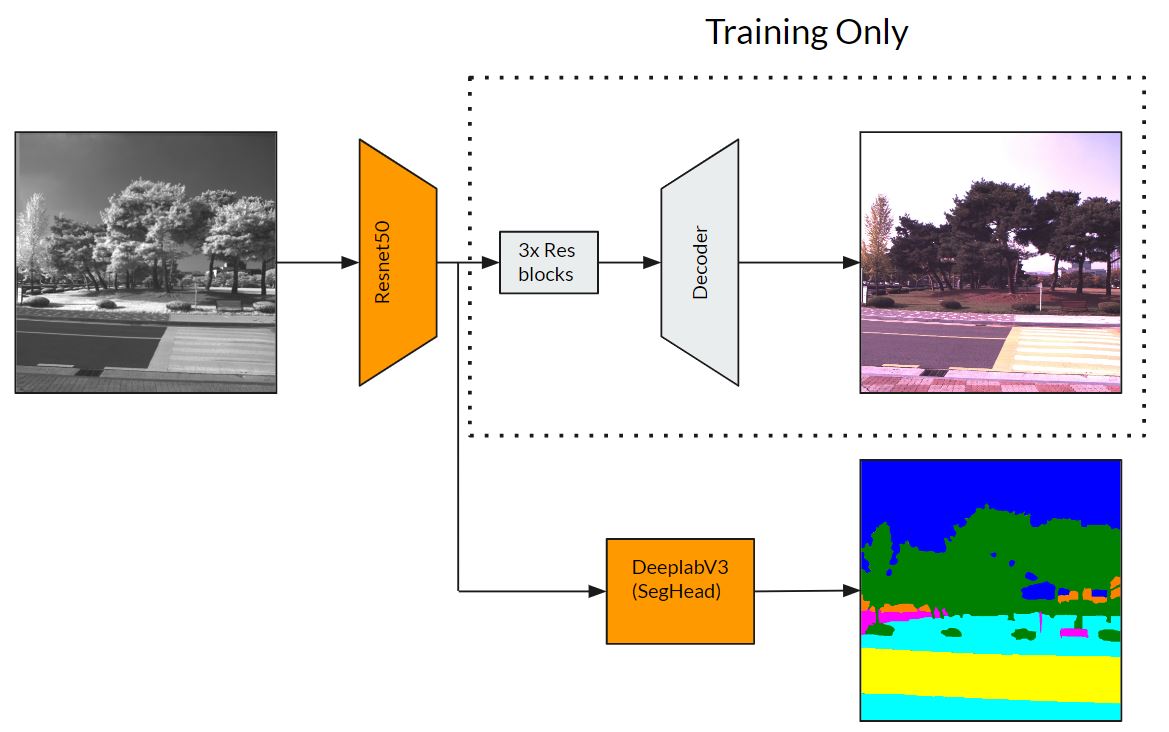
Experiments
We experiment with various architectures and loss functions and schemes to try and improve segmentation performance. Our metric for segmentation is mean intersection-over-union (mIOU).Baseline Model: DeepLabv3
Architecture: The baseline is just the segmentation pipeline detailed above and fine-tuned for our dataset. We used pixel-wise multi-class cross entropy loss for the segmentation task. This does not change throughout the duration of the experiments.
Results: The baseline model mIOU metrics were similar, but slightly below the reported value in the base paper (47.08 vs 45.56). This comparison is just a point of reference to put our performance in context. The paper does not give much details about their architecture or pipeline, so our purpose is not to make an apples-to-apples comparison but to simply ensure that our model can reach reasonably close performance to that reported in their paper. The results verify that our baseline does in fact react a value close to the reported value. We believe that our baseline model can be improved by using a better base encoder model such as ResNet101, or a more modern and robust base architecture such as a vision transformer or ConvNeXt. Nevertheless, we chose to continue with a ResNet-50 feature encoder and a DeepLabV3 segmentation head as it was a good balance of simplicity, computationally cheap, and reasonably performant compared to the paper.
| Paper | Baseline | |
| mIOU | 47.08 | 45.56 |
Encoder Decoder Experiments
In these experiments, we chose a simple encoder-decoder network to generate an RGB image from the NIR image input. We use the same features produced by the feature encoder (ResNet-50) as our encoder and saved some of the intermediate outputs to add skip connections to the corresponding layers in the decoder. This results in a U-Net-like encoder-decoder network with skip connections. We also used batch normalization with ReLU activations in both the encoder and decoder. We experiment with different loss functions and weightings for each loss component. Our baseline loss equation is:Where the total loss is a weighted combination of the segmentation loss and the RGB reconstruction loss. The segmentation loss remains the multiclass cross entropy loss described in the baseline. We use a beta value to weight each loss, and use several weighting schemes which we will explore further below.
Experiment 1: Loss Functions
| Paper | Baseline | L1 | L2 | |
| mIOU | 47.08 | 45.56 | 46.27 | 45.52 |



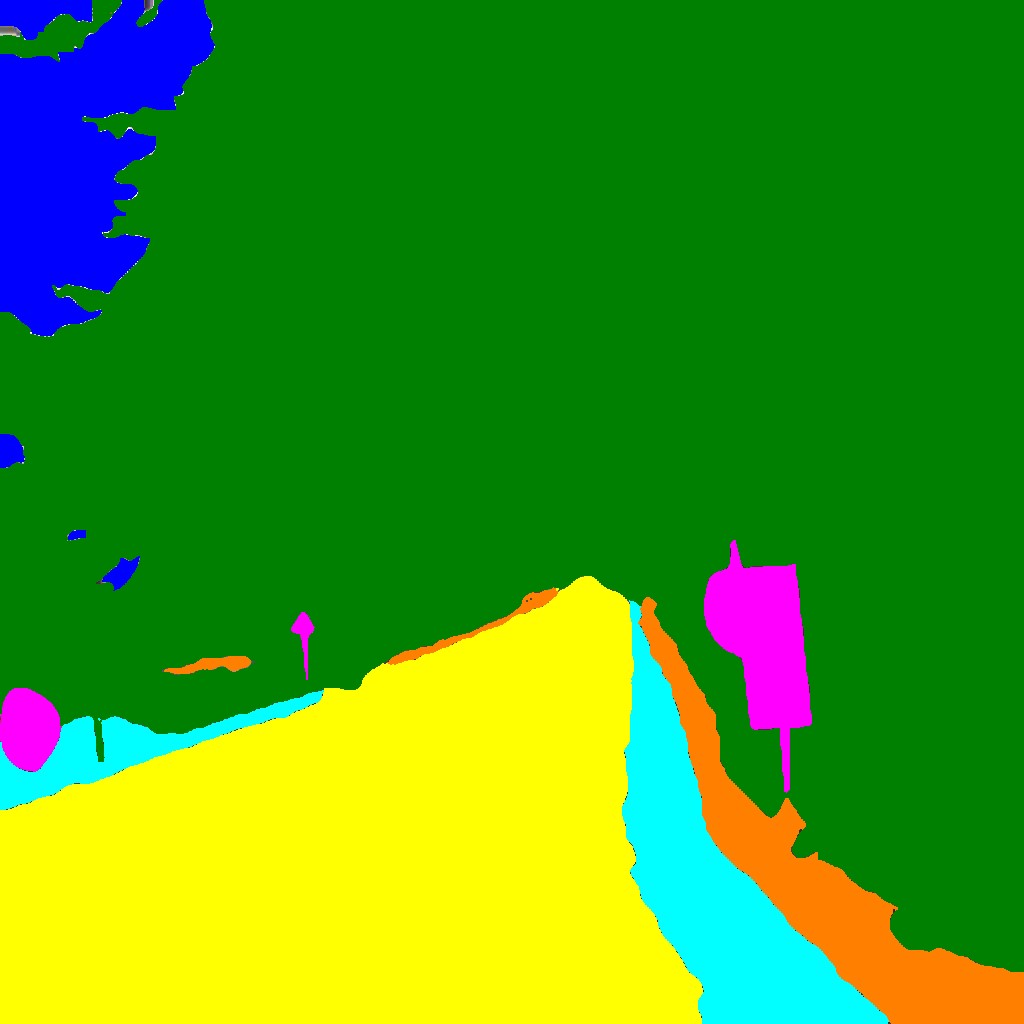

Results: We find that adding the generative co-learning task does improve performance over the baseline when using a L1 reconstruction loss. However, the difference is fairly marginal. Visually, the reconstructions do not do a great job at producing realistic colors, but the objects are quite sharp and well-defined. The washed out colors are not surprising we are purely using L1 and L2 norms. This may also be due us using batch normalization, leading to normalized and whitened outputs. Moreover, the input RGB images themselves may be problematic, as the colors are often muted and many images have a pinkish tint to them. Because of this, we find that many reconstructions also have a pinkish tint. The RGB reconstructions looks like an image that is right in between the ground truth NIR and RGB images. This effect may be a consequence of the skip connections, as the reconstruction is heavily grounded in the original NIR features.
Experiment 2: Beta Balancing
In this experiment, we change the value of beta linearly from [0,1] based on the epoch number. Our hypothesis is that our model may not have the capacity to jointly optimize the segmentation and generative losses as gradients from both tasks are being propogated back through the encoder. Therefore, it may be beneficial to focus only on the generative loss early on in the training process, then slowly rebalance the weights, eventually focusing only on the segmentation loss later on. We used a CosineAnnealingWarmRestarts scheduler to cyclically lower and then increase the learning rate every 10 epochs to mitigate learning rate issues during the rebalancing process.| Paper | Baseline | L1 (equal) | L2 (equal) | L1 (rebalanced) | L2 (rebalanced) | |
| mIOU | 47.08 | 45.56 | 46.27 | 45.52 | 43.03 | 44.76 |


Results: Quantitatively, our mIOU drops significantly from our rebalancing scheme. Overall, the results for both L1 and L2 firmly indicate that an equal weighting is better for segmentation performance. We believe that this is an issue of scaling as the segmentation loss values quickly drop to values lower than the generative loss, even in early epochs where the emphasis is on the generative task. Furthermore, this rebalancing scheme may have caused the model to land in a suboptimal local minimum that favors the generative task rather than the segmentation task. Visually, our reconstructions are arguably better, with sharper images and better contrast. This is quite surprising as the visualizations are using L2 loss, while the corresponding visualizations in Experiment 1 are using L1. However, this does further support our hypothesis that the model has converged to a solution that favors performance in the generative task, even with the dynamic rebalancing of the weights.
Conclusion: Overall, the encoder-decoder network does slightly improve mIOU performance when using a L1 generative loss with equal weighting of generative and segmentation losses. However, the improvement is quite minimal, indicating that the gradients propagated from the generative task were not useful for the primary segmentation task. The quality of the reconstructions does not seem to directly correlate to the impact on the segmentation task, as the models with losses dynamically rebalanced achieved a lower mIOU, but visually better reconstructions. Therefore, for the follow-on GAN experiments, we chose not to rebalance losses.
Generative Adversarial Network Experiments
Architecture: To implement a GAN,we used a similar architecture as the decoder for our generator, but removed the skip connections. We used a patch discriminator that provided outputs for every 64x64 patch of the input image. Rather than using batch normalization, we used instance normalization with LeakyReLU activations for both generator and discriminator networks. We used Vanilla GAN losses as our generative loss, but added the segmentation loss to the generator loss.
The GAN losses were implemented with binary cross entropy loss. Importantly, rather than minimizing the probability that the generator outputs are fake images, we maximize the probability that the generator outputs are recognized as real images in the discriminator. We did experiment with using a Wasserstein GAN Loss with Gradient Penalty, but found the training to be very unstable and were not able to complete any experiments that provided meaningful comparisons.
| Paper | Baseline | GAN | |
| mIOU | 47.08 | 45.56 | 47.58 |
Some of our outputs utilizing the GAN architecture are featured bellow:













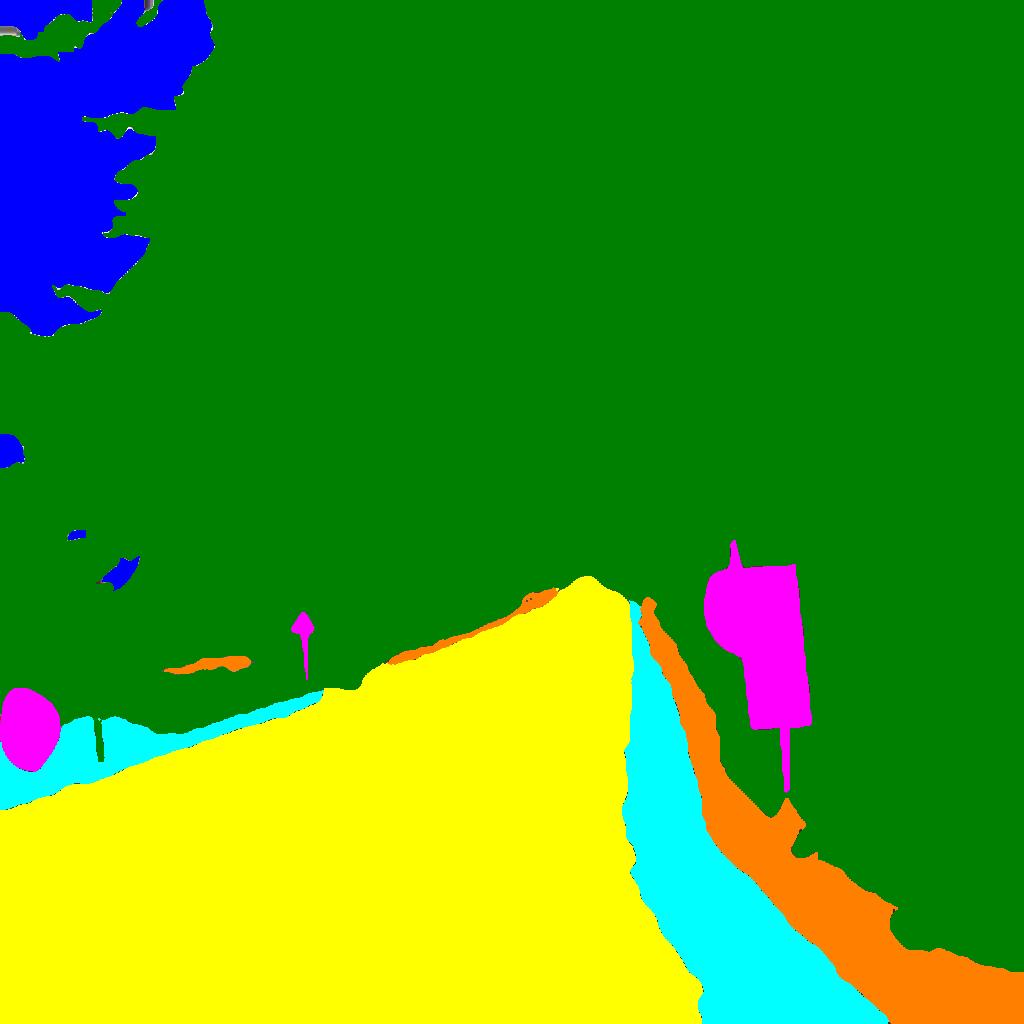






Results: Quantitatively, there is a marked improvement in segmentation performance when using a GAN as our generative model. However, visually we can see that our GAN does not produce a good image reconstruction at all. First, we can see checkerboard artifacts, indicating that our upsampling method is suboptimal. A bigger issue is that the GAN is not producing a colorized photo. Our RGB images only retain the general shape of foreground and background objects. This may be due to us removing the skip connections in the generator. This was done due to computational constraints, as there were several large layers to downsample the number of filters needed for skip connections. Furthermore, an additional L1 loss component to the generator loss as shown in pix2pix. Additionally, including the segmentation loss in the generative loss may be an issue, as the addition of the segmentation gradient may have destabilized the balance between the encoder, generator, and discriminator. Nevertheless, the resulting improvement in mIOU indicates that though the GAN may not producing good RGB images, it is actually providing a useful training signal that is improving the performance in the segmentation task. This further supports our finding that the performance in the generation task is not necessarily correlated to the segmentation performance.
Generative Adversarial Network Experiment Discussion: Though the RGB outputs were disappointing, the improvement in mIOU does indicate that our generative process does seem to be helping improve the segmentation pipeline. The performance in the generation task may not be directly correlated, but the results indicate that different architectures do play a significant role in the quality of the training signal propagated back to the encoder. However, so far, all of our reconstructions have not been great, so further work to improve the quality of the RGB reconstruction may disprove our initial findings on the correlation between the generative and segmentation tasks. However, our main purpose was to explore whether a generative co-learning process can be used to improve unimodal NIR segmentation performance, which our GAN models have shown. Further work to improve the GAN performance may lead to greater improvements.