Manifold Contrastive Learning for Unpaired Image-to-Image Translation
16726-Learning-Based Image Synthesis Final Project
| Shen Zheng Qiyu Chen |
| Carnegie Mellon University |
| {shenzhen,qiyuc}@andrew.cmu.edu |




| Shen Zheng Qiyu Chen |
| Carnegie Mellon University |
| {shenzhen,qiyuc}@andrew.cmu.edu |
The task of unpaired image-to-image translation involves converting an image from one domain to another without a corresponding set of paired images for training. This area of research has gained significant attention in recent years due to its potential applications in various fields, such as style transfer [6], domain adaptation [11], image synthesis [2], and data augmentation [4]. Since this problem is ill-posed and can result in multiple possible translations, the primary challenge for unpaired image-to-image translation is to identify an appropriate assumption or constraint to regularize the translation process.
CycleGAN [14] is a well-known work that contributed to image-to-image translation through the introduction of a cycle-consistency loss. The follow-up work UNIT [10] expanded on this by proposing a shared latent space assumption, where images from different domains are mapped to the same latent vector. MUNIT [5] and DRIT [9] further improved the process by disentangling images into domain-invariant content codes and domain-specific style codes, allowing for the translation of images across multiple domains with style code variation.




Despite the significant progress made by existing methods on various benchmark datasets, two major challenges still exist. The first challenge is the presence of unwanted artifacts and distortions in the translated images, which results in poor perceptual similarity with both the content and style images. Even if the generated images' quality is acceptable, they often exhibit the second challenge: the output images tend to resemble the source image more than the target image (i.e. source proximity). To illustrate the limitations of previous state-of-the-art methods, we provide visual examples in Fig. 2. In the next section, we propose our method which aims to overcome these limitations.
This section begins by introducing the preliminaries and notations used in our proposed method. We then utilize the detailed information present in the output matrices of the discriminator [8, 1] to develop two novel loss functions: the Triangular Probability Similarity (TPS) loss and the Target Over Source (TOS) loss. These loss functions aim to address the limitations of previous methods, as discussed in the previous section. Finally, we present the complete set of loss functions used for training our model.
Let us consider
and
as the width and height of the image, respectively. Besides, let's further suppose that
represents the source image,
represents the target image,
represents the translated image, and
represents the discriminator.
In the manifold of the discriminator output matrix, image-to-image translation can be seen as a transportation process of an image from the source domain to the target domain. The quality of the translated images, denoted as
,
can be evaluated by the amount of feature overlaps they share with both the source and target images, as well as the degree of unwanted artifacts present in them. As illustrated in Fig. 3, a ”good” translation should have a high feature overlap with the source and target images while minimizing the presence of artifacts, whereas a ”bad” translation will exhibit a lower feature overlap and more pronounced artifacts.
 loss")
Note that we propose the Triangular Probability Similarity (TPS) loss to help pull the translated images towards the target domain along the line segment connecting the source image
and the target image
.
This constraint promotes more feature overlaps between them, which reduces unwanted distortions and artifacts. By utilizing the Triangular Inequality Theorem, we can write the TPS loss as follows.
Although TPS reduces artifacts and distortions, it does not solve the source proximity issue. For instance, as seen in Fig. 4, two different generated images,
and
, have the same TPS value because they are on the same level set. However,
is a better option than
as it is closer to the target image, indicating stronger target proximity and weaker source proximity.
 Loss")
Drawing from the insight that TPS alone does not sufficiently address the source proximity issue, we introduce the Target Over Source (TOS) loss in order to further improve the translation quality. The TOS loss pulls the translated images towards the target images and pushes them away from the source images in the discriminator manifold, which reduces the source proximity and increases the target proximity. The TOS loss can be expressed mathematically as follows:
The overall loss functions used for training are listed below:
Implementation Details Our model and other baseline models were trained on a single RTX 3090 GPU using Py-Torch [7]. We utilized the Adam [7] optimizer with
= 0.5 and
= 0.99. The training process consisted of 400 epochs, and a batch size of 1 was employed. During the first 200 epochs, a fixed learning rate of 2e-4 was used, while the subsequent 200 epochs utilized a linear decay schedule to gradually reduce the learning rate to 2e-5. Image patches of size 256
256 were used for training.
We evaluated the proposed method on several benchmark datasets, including label2photo in cityscapes [3], horse2zebra, and cat2dog. Our approach was compared to other established methods, such as CycleGAN [14], CUT [12], and MoNCE [13]. To evaluate the performance, we used FID and conducted visual comparisons between the generated images.
We perform an ablation study on the proposed TPS and TOS modules by integrating them as a plug-and-play module into the state-of-the-art method MoNCE [13]. Specifically, MoNCE without TPS and TOS loss is equivalent to Ours without the two proposed modules. We then evaluate the performance of image-to-image translation qualitatively and quantitatively. As shown in Fig. 1, we observe that Ours (w/o TPS) exhibits peculiar artifacts around the upper part of the head and the neighboring region of the mouse, while Ours (w/o TOS) resembles a cat more than a dog (source proximity). In contrast, Ours with both proposed modules has fewer artifacts and distortions and is more similar to a dog (target proximity).
Table 1 presents a quantitative comparison of the performance of the proposed TPS and TOS methods with other state-of-the-art methods using FID as the evaluation metric. The results show that our method consistently outperforms the MoNCE method in terms of FID. For the horse2zebra and cat2dog datasets, our method achieves the lowest FID, while for the cityscapes (label2photo) dataset, our method with only TOS (without TPS) achieves the lowest FID.
| Methods | horse2zebra | cat2dog | label2photo |
|---|---|---|---|
| CycleGAN | 76.90 | 125.88 | 135.35 |
| CUT | 48.80 | 231.68 | 62.62 |
| MoNCE | 61.20 | 75.46 | 51.74 |
| Ours (w/o TOS) | 57.27 | 67.21 | 46.58 |
| Ours (w/o TPS) | 50.60 | 61.13 | 45.54 |
| Ours | 47.03 | 58.79 | 48.99 |
Cat2dog We provide a qualitative comparison for the cat2dog dataset in Fig. 5. We observe that the translated images generated by CycleGAN lack eyes, making them unrealistic. CUT's translated images exhibit strong source proximity, resembling the source (cat) more than the target (dog). MoNCE's translated images display strange distortions around the mouse. In comparison, our method produces high-quality images that match the semantic context of the target domain. In Fig. 6, we show another qualitative comparison of the cat2dog dataset. We find that CycleGAN and MoNCE's translated images contain peculiar artifacts and distortions around the dog's ears and eyes, which our method does not exhibit.








Horse2zebra Fig. 7 displays a qualitative comparison of the horsezebra datasets. It can be seen that CycleGAN, CUT, and MoNCE generate blurry artifacts around the zebra body and in the background scenes, while our proposed method outperforms them with significantly better performance.





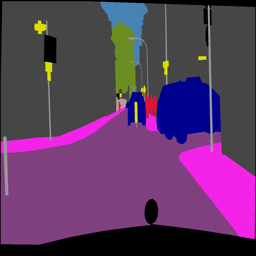
Cityscapes (label2photo) Qualitative comparisons for the cityscapes dataset (label2photo) are shown in Fig. 8 and Fig. 9. Our method produces high-quality images with excellent color balance, edge information, and image contrast, while exhibiting minimal artifacts and distortions. The performance of other methods, such as CycleGAN, CUT, and MoNCE, is surpassed by our approach in terms of visual quality.









Although our method effectively reduces artifacts and distortions and suppresses source proximity, it is not immune to failure cases (as shown in Fig. 10. In the first example, the horses are correctly translated to zebras, but the background water is mistakenly translated to land. In the second example, the person is erroneously given zebra stripes, while the horse behind it remains unaltered. Our model fails to distinguish the regions that require translation from those that do not. To address this, we plan to utilize TPS and TOS based on multi-layer output from the discriminator instead of just the final layer. This approach will allow our method to capture higher levels of abstraction and better utilize the semantic context of specific regions for image-to-image translation in the future.




In this project, we employ the output matrices of the GAN discriminator and introduce two novel loss functions to improve image-to-image translation. Specifically, we utilize the Triangular Probability Similarity (TPS) loss and the Target Over Source (TOS) loss in the discriminator manifold. The TPS loss pulls the translated image towards the line segment connecting the source and target images, reducing artifacts and distortions. The TOS loss pulls the translated image proportionally towards the target image, reducing source proximity and encouraging target proximity. Our experiments demonstrate that the proposed method outperforms the previous state-of-the-art both qualitatively and quantitatively.