

This assignment aims at providing us with hands-on experience coding and training GANs. In this first part, I will implement most components of a Deep Convolutional GAN (DCGAN), while comparing no data augmentation, data augmentation for training discriminators, and Differentiable Augmentation for both discriminator and generator. In the second part, I will implement the CycleGAN for image-to-image translation task.
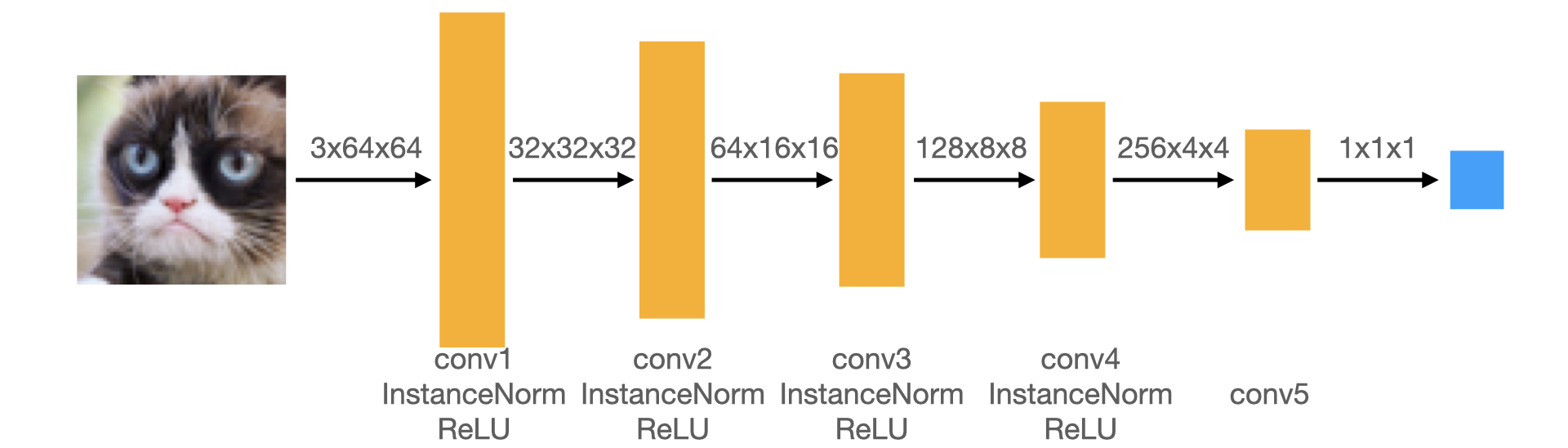
The discriminator mainly consists of Convolutional layers followed by InstanceNormalization.
Padding Calculation: for each convolutional layer above, we need to downsample the spatial resolution by a factor of 2, given kernel size K = 4 and stride S = 2. Let H be the size of one side of the image, P be the padding. Then the padding for the first four layers is calculated as:
floor((2H + 2P - 4)/2) + 1 = H
H + P - 2 + 1 = H
P = 1
Similarly, the padding for the last layer (which converts spatial size H from 4 to 1) is:
floor((4 + 2P - 4)/2) + 1 = 1
P + 1 = 1
P = 0
The DCGenerator consists of a sequence of upsample+convolutional layers, except for the first layer where we only have spatial size of 1x1. In this case, it does not make any sense to do normal convolution with kernal size and stride being at least 1. Instead, I use ConvTranspose2d to do fractional convoltion in order to upsample the first layer.
- basic: DCGAN with no data augmentation:
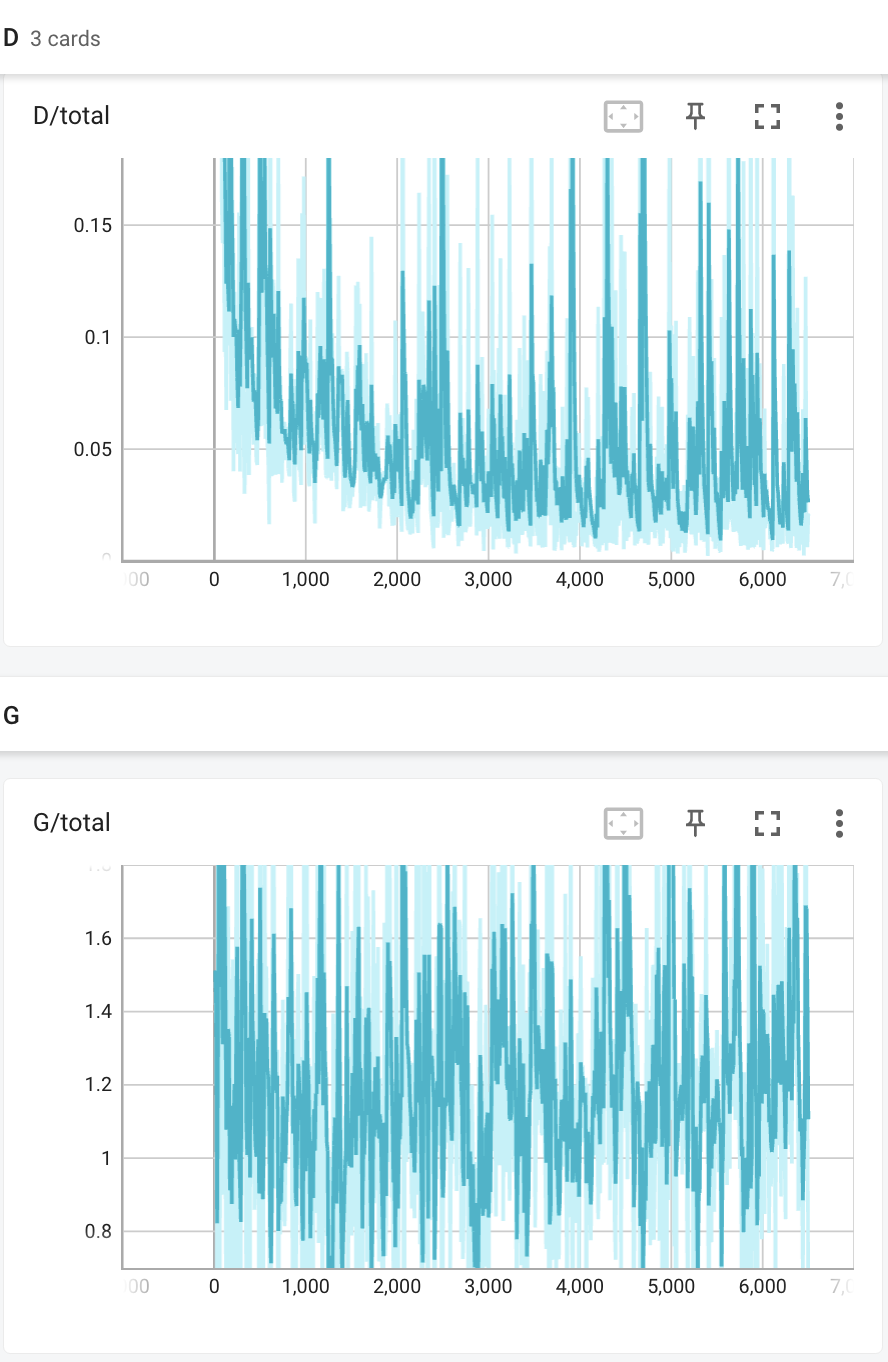


|Discriminator and generator train loss | Iter 200 | Iter 6400 |
The generator loss does not really improve and the samping images almost collapse into one blurry image
- deluxe: DCGAN with real data augmentation for discriminator only:
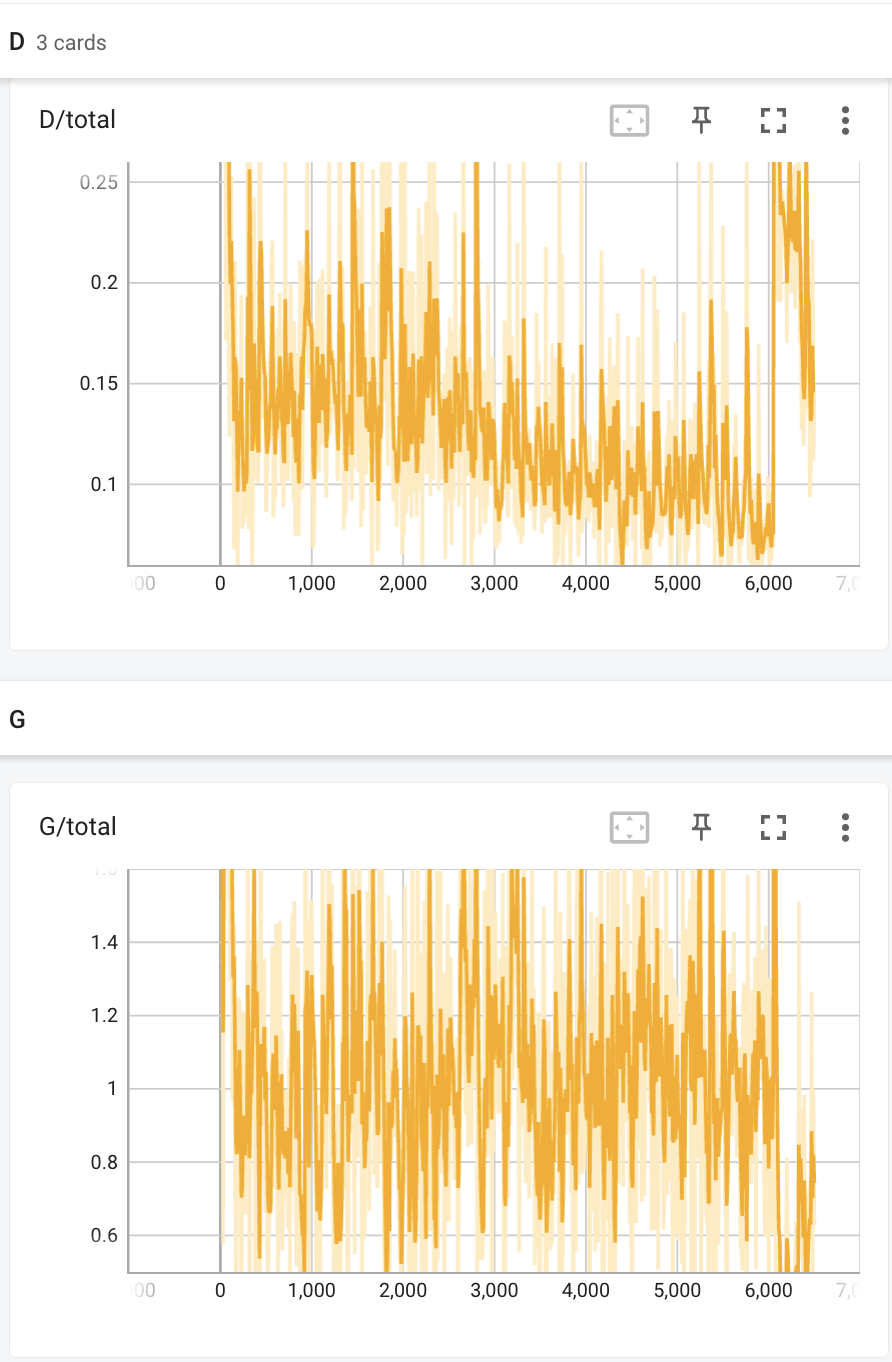


|Discriminator and generator train loss | Iter 200 | Iter 6400 |
The generator loss starts improving in the end and the samping images get the overall structure right.
- DiffAug: DCGAN with real+fake data augmentation for discriminator and generator:
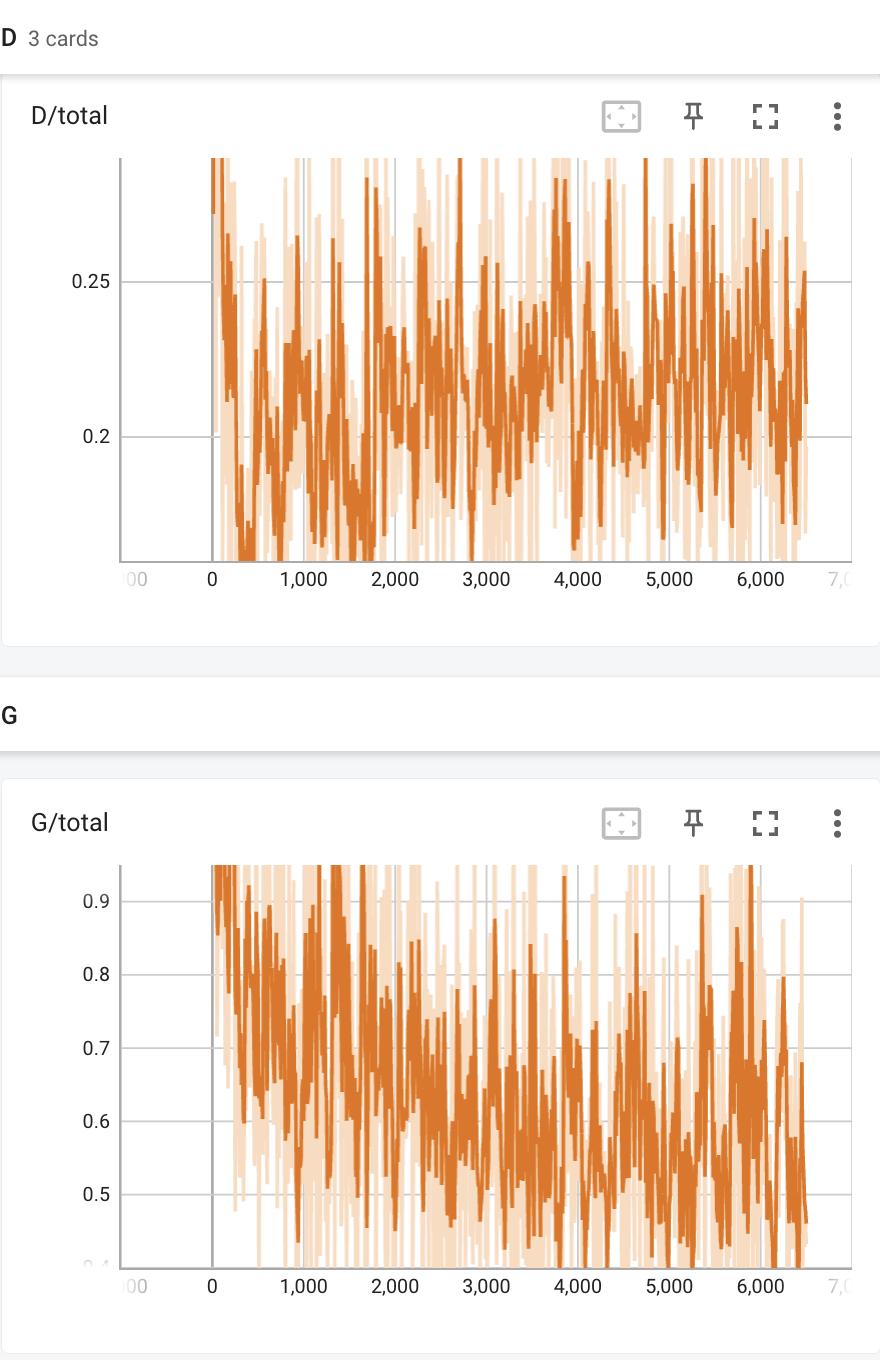


|Discriminator and generator train loss | Iter 200 | Iter 6400 |
Using DiffAug, the generator loss decreases a lot, and the samping images get more details and diversity
- deluxe + DiffAug: DCGAN with real+fake data augmentation for discriminator and generator, with a stronger augmentation for real data:
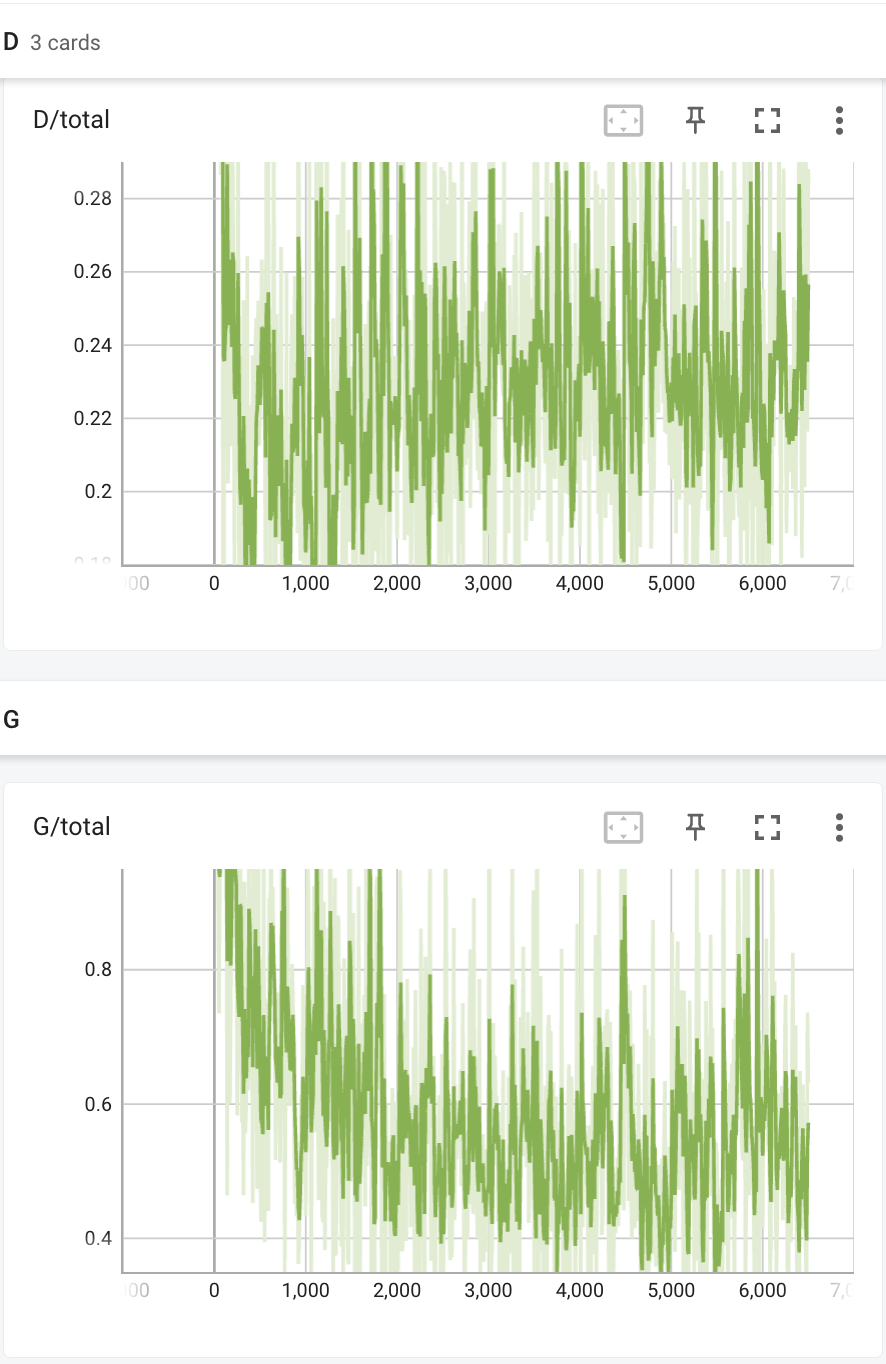


|Discriminator and generator train loss | Iter 200 | Iter 6400 |
Adding more augmentation for real data seems to not have large change compared to just DiffAug
For this kind of two-player minmax loss, it is natural for both loss curves to fluctuate heavily, since when one is improving, the other is becoming worse. But ideally, if GAN manages to train, then the distribution of the real data should be quite similar to that of the generated data, making the discriminator almost impossible to distinguish between them. That is to say, after some initial decrease for both generator and discriminator loss, the discriminator loss should stay low stably, corresponding to 50-50 chance for each prediction. For the generator, after being trained to generate something that looks realistic, its loss curve becomes saturated and cannot get very helpful gradients from the confused discriminator.
After training with deluxe and DiffAug augmentation, the discriminator cannot easily just memorize all the real images, forcing it to learn from different aspests of the images. This helps maintain the diversity of the image in early state. Towards the end of training, there is still some degree of diversity and images are becoming pretty natural, in a way that you cannot tell it is from some random noise. Most get the overall structure right, but still have some problems on some local high-frequency details.

The CycleGAN conditional generator consists 2 convolutional layers to extract the image features, 3 Residual Block to transform the features, and 2 up-convolutional layers to decodes the transformed features.
Other than the vanilla deep convolutional discriminator, we use a PatchDiscriminator from pix2pix, which classifies each patch of the images, allowing CycleGAN to model local structures/styles better. To do this, the PatchDiscriminator produces spatial outputs (e.g., 4x4) instead of a scalar (1x1) by removing the last layer from vanilla DCDiscriminator.
Note that all experiments use the deluxe version and differentiable augmentation techniques described above. Each image is from the source domain to the fake images in the target domain.




















The usage of cycle consistency loss results in much more realistic generated images. This is because in order to be cycle consistent, the first generator needs to preserve all the necessary information needed to generate the original image. Specifically, such information includes background content and foreground overall structure. As a result, adding cycle consistency loss helps generate images with more realistic background content and foreground structure.
Example of cycle consistency loss preserving background content:


Example of cycle consistency loss preserving foreground structure (may be bad if you actually want to change the foreground content):


Theoretically, the usage of PatchGAN/PatchDiscriminator helps the generator generator images with diverse and fine-graine details, since it provides scores, as well as supervision signals, for each local area instead of the global low-frequency structure of the image. Its focus on fine-grained details can help it generate better high-frequency details.
However, in my experiments with cycle-consistency loss and DiffAug enabled all the time, I do not find much visual difference in the quality of the final generated images. Some reasons for this include: the image resolution is too small and the number of patches (4) is too small. Testing with more patches on larger images can give a better idea of the effect of PatchDiscriminator.
I used the imageio to generate GIF images using all the generated images from the trained CycleGAN from Cat Experiment 1. The iteration number is shown on the top left corner.

Train a CycleGAN model with cycle-consistency loss, DiffAug, and PatchDiscriminator as described above on 256x256 images of grumpy cats. I think the image quality is limited by the current shallow architecture.


Here I generate images from the pre-trained stable diffusion model at https://stablediffusionweb.com/ using the prompt "grumpy cat."




And here are examples generated from Diffusers:
Prompt: A grumpy cat

Prompt: A real grumpy cat that looks very happy and excited