Concept Ablation in Diffusion Models
Diffusion models are a class of models used in machine learning and statistics for various tasks, such as image classification and natural language processing. These models operate by spreading information or "activations" through a network of interconnected nodes, representing concepts or features. In particular, Stable Diffusion (SD) is capable of being embedded with specialized art styles or subjects that can be collated into a library (such as the HuggingFace Stable Diffusion concepts library [1]), where the community trains SD to generate a new concept.
While the ability to create new concepts using SD is quite fascinating and useful, there are many instances where we do not want the SD model to generate a particular concept that it was trained on. For example, when deploying a SD model for the general public to use, we want to ensure that the model is not capable of generating nudity or gory images. However, these concepts were present in the training data to SD, so it is of great interest to inhibit SD from generating this concept. While complete re-training on a selective dataset is an option (an option that was implemented in Stable Diffusion 2), it is not quite viable every time a new concept that needs to be removed is observed. There are a few techniques that exist to perform this sort of inhibition [2][3].
In our experience of using these techniques, we noticed that the removal of a concept is seldom perfect. One example of this that we observed is displayed below:

The image on the left is generated by the model with the concept of a “french horn” removed from stable diffusion and the image on the right is the original stable diffusion model. While the french horn has been removed in the image on the left, there is hardly any indication that there is a band performing on stage or that the band is a jazz band. The focus has wildly shifted from the jazz band in order to avoid generating the concept. We also see a (creepy) head on the floor of the stage, indicating that other concepts may have also been inadvertently affected by the fine-tuning process that erased the concept of the french horn from the diffusion weights.
Another example of this happening is in the following model, which has been fine-tuned to remove the concept of "car" from the stable diffusion pretrained model. We see a succesful version of this occuring when we prompt the model to generate an image conditioned on "ferrari". However, when we try to generate an image conditoned on the prompt "tank", we see that this (vaguely) related concept has been adversely affected by the fine-tuning.


We further trained a model using (Gandikota et al.) method to erase the "grumpy cat" concept. On training for 150 epochs we found that the model did not handle multi word concept erasing well. In the below images the trained model to remove "grumpy cat" produced the following results for the corresponding prompts. It is also unclear what concept replaces the concept that is erased. For example, using the same concept as prompt produces a woman's picture with dark eyes.
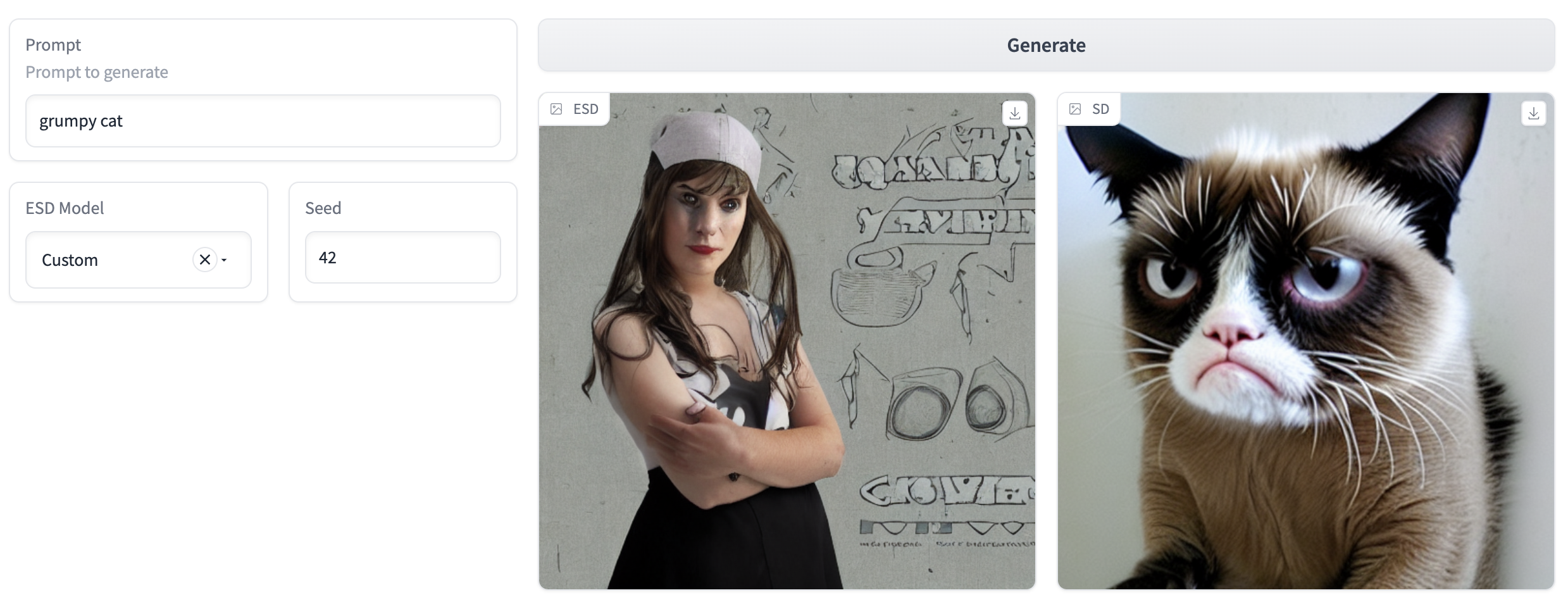
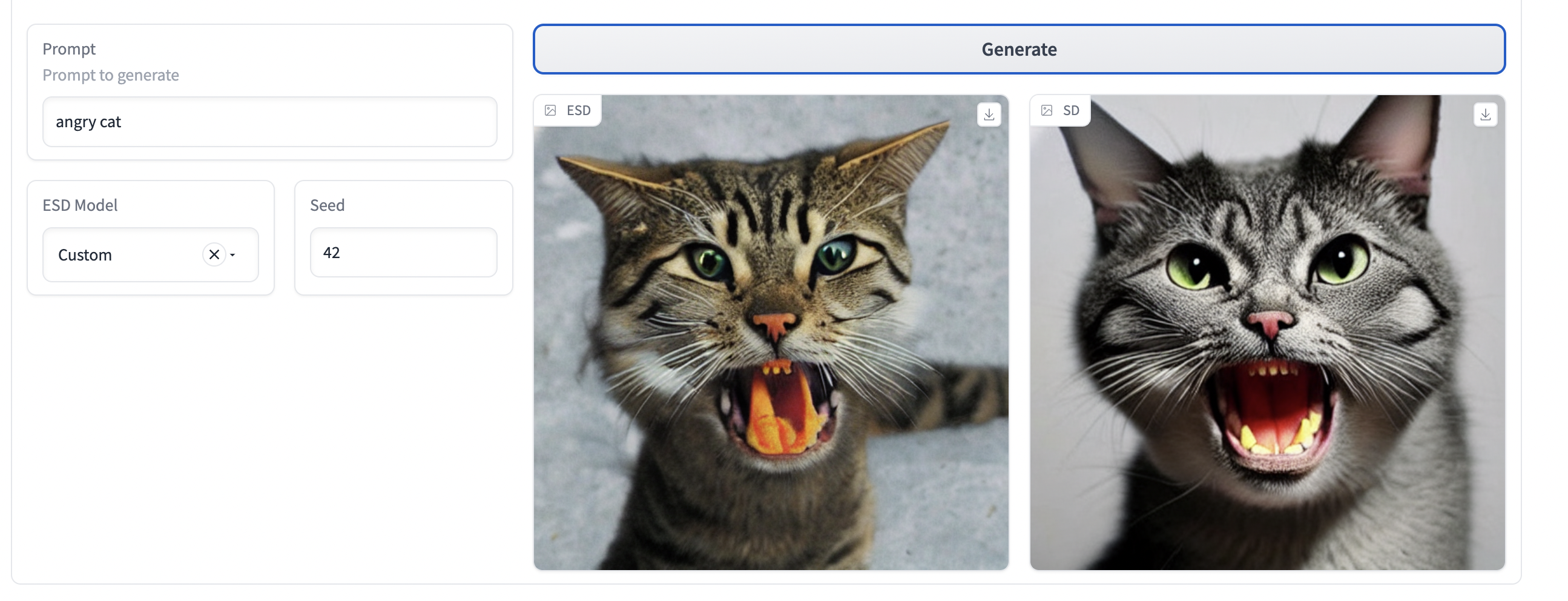
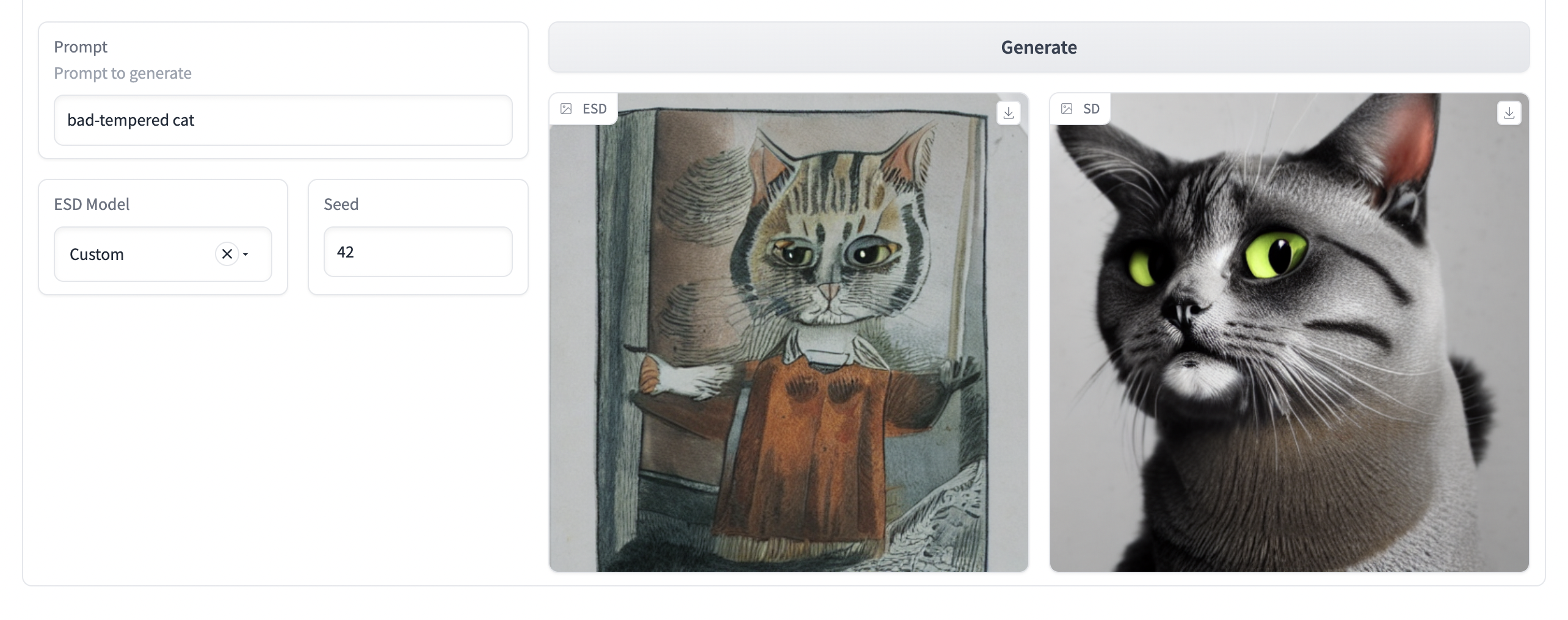
Erasing Concepts from Diffusion Models - Gandikota et al. (2023)
The paper proposes a fine-tuning method that can erase a visual concept from a pre-trained diffusion model, given only the name of the style and using negative guidance as a teacher. The method works by modifying the model's weights to reduce its sensitivity to the undesired concept while preserving its performance on other tasks.
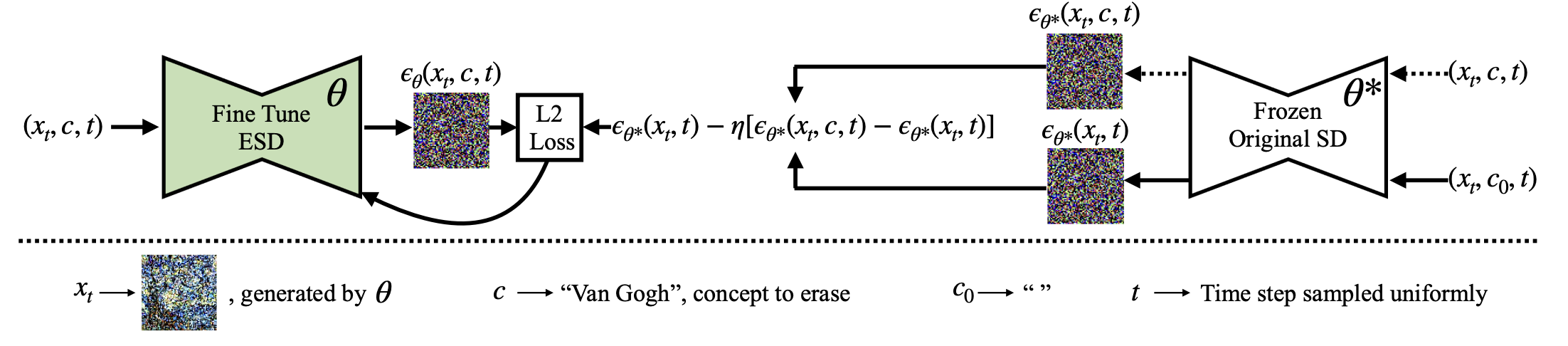
The fine-tuning process proposed in the paper involves modifying the weights of a pre-trained diffusion model to reduce its sensitivity to a specific visual concept. The process works as follows:
1. Freeze one set of parameters (θ*) in the diffusion model and train the other set of parameters (θ) to erase the concept. This is done by synthesizing training samples using the model's knowledge of the concept, thereby eliminating the need for data collection.
2. Sample partially denoised images x_t conditioned on c using θ, then perform inference on the frozen model θ* twice to predict the noise, once conditioned on c and the other unconditioned.
3. Combine these two predictions linearly to negate the predicted noise associated with the concept, and tune the new model towards that new objective.
The authors benchmarked their method against previous approaches that remove sexually explicit content and demonstrated its effectiveness, performing on par with Safe Latent Diffusion and censored training. They also conducted experiments erasing five modern artists from the network and conducted a user study to assess the human perception of the removed styles.
Ablating Concepts in Text-to-Image Diffusion Models - Kumari et al. (2023)
The paper proposes an efficient method of ablating concepts in the pretrained model, i.e., preventing the generation of a target concept. Specifically, the method learns to change the image distribution of a target concept to match an anchor concept. For example, if the target concept is a copyrighted Van Gogh painting, the method can learn to change the image distribution to match that of paintings in general. This way, when generating images, the model will not generate any images that resemble Van Gogh's copyrighted work. The paper also extends this method to prevent the generation of memorized images by changing the image distribution of a memorized image to match that of other similar images.
The method proposed in the paper for ablating concepts in text-to-image diffusion models involves several steps:
1. Selecting an anchor concept: This is a concept that is similar to the target concept but does not have any copyright or memorized image issues. For example, if the target concept is a copyrighted Van Gogh painting, the anchor concept could be paintings in general.
2. Fine-tuning the model: The authors fine-tune the pretrained text-to-image diffusion model on a dataset of images that are similar to the anchor concept. This helps to change the image distribution of the model so that it generates images that are more similar to the anchor concept.
3. Modifying the objective function: The authors modify the objective function of the model so that it encourages generated images to be dissimilar to the target concept. Specifically, they add a term to the objective function that penalizes generated images that are too similar to the target concept.
4. Iteratively ablate concepts: The authors then iteratively ablate concepts by repeating steps 1-3 for each target concept they want to remove from the model.
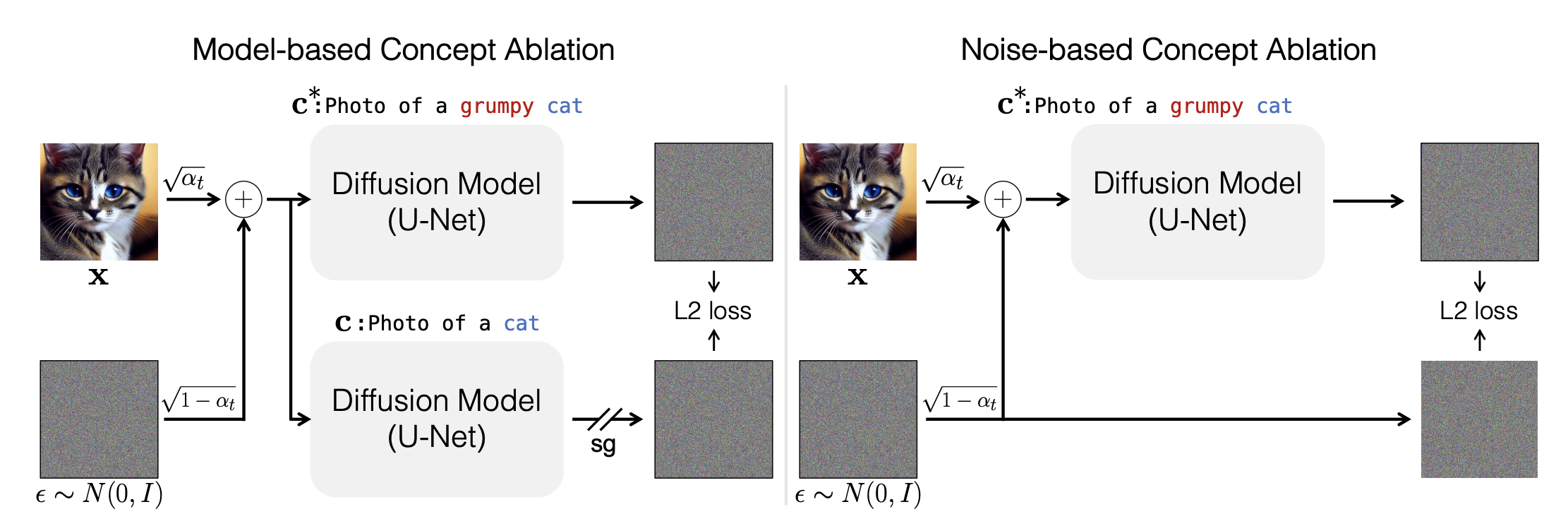
By following these steps, they were able to successfully remove copyrighted materials and memorized images from pretrained text-to-image diffusion models while still maintaining high-quality image generation for other concepts.
Gaussian Sampling on the text embedding
When erasing a concept from a diffusion model we want minimal impact on the surrounding concepts. In Gandikota et al. (2023) and Kumari et al. (2023) we found that surrounding concepts were defined by human defined prompts. We wanted to try a different approach using Gaussian Sampling to define "similar concepts".
To achieve this, we experimented using Gaussian Sampling to obatin similar prompts using the text embedding vector of the concept prompt. We found that in the CLIP embedding space a sample from Gaussian sample vector may not necessarily represent a valid prompt for the Stable Diffusion model. Hence, we did not acheive good results with this method.
Result of Concept Erased Stable Diffusion Model of Kumari et al. (2023)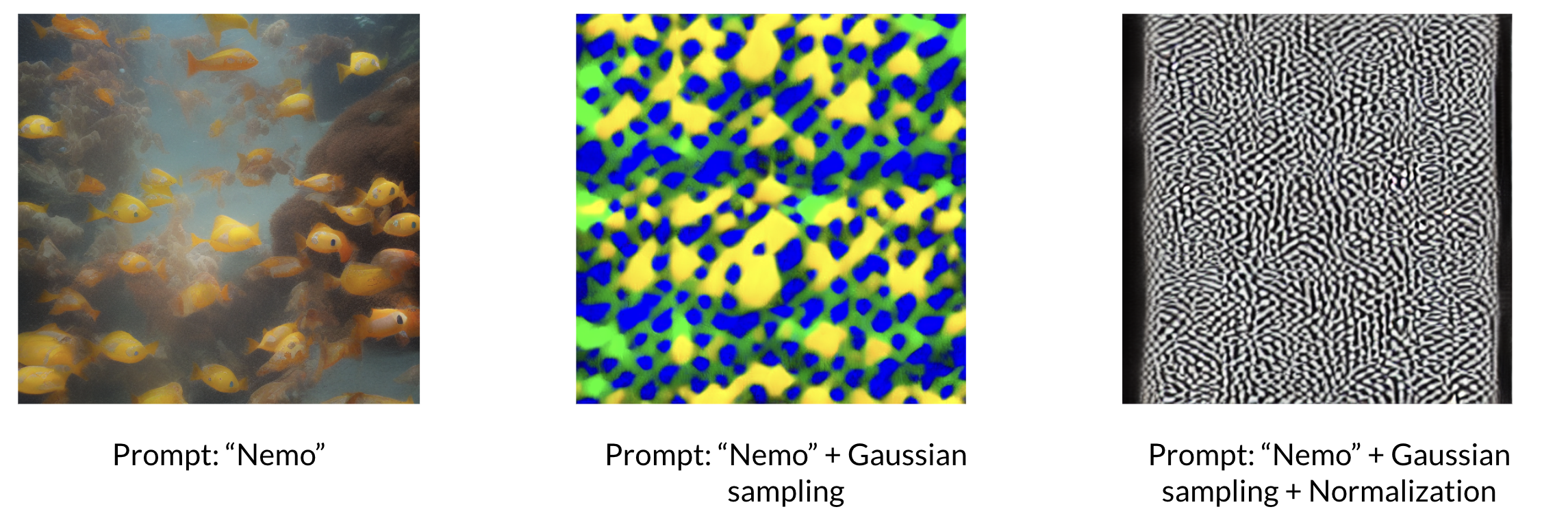
Different Loss functions for Concept Erasing
Further, to explore the effect of different loss functions on concept erasing, we experimented training the model proposed by Gandikota et al. (2023) and Kumari et al. (2023) with L1 Loss instead of L2 Loss.
We initially faced some issues training these models, which are listed as follows:
- Lack of multi GPU Machines
- Expensive GPU Machines provided on AWS
- Low GPU memory on multi GPU Machines
- Early stopping and inefficient learning with smaller batch and input sizes
- L2 Loss with (10, 4, 32, 32) DDIM Sampling Input and 100 prompts: stopped training at Epoch 4 due to max_steps reached.
Sampling Results with Prompts:
Cat

Grumpy Cat napping in the Sun

Cat is Grumpy

- L2 Loss with (1, 4, 64, 64) DDIM Sampling Input and 10 prompts: stopped training at Epoch 21 due to max_steps reached.
Sampling Results with Prompts:
Cat

Grumpy Cat napping in the Sun

Cat is Grumpy

- L1 Loss with (10, 4, 32, 32) DDIM Sampling Input and 100 prompts: stopped training at Epoch 4 due to max_steps reached.
Sampling Results with Prompts:
Cat

Grumpy Cat

Cat is Grumpy

Comparison of works for concept erasing
| Concept | Gandikota et al. | Kumari et. al. |
|---|---|---|
| Ablated Concept | 0.6568 | 0.6868 |
| Surrounding Concept | 0.5916 | 0.5843 |
| Concept | Gandikota et al. | Kumari et. al. |
|---|---|---|
| Ablated Concept | 0.4417 | 0.8160 |
| Surrounding Concept | 0.6490 | 0.3998 |
| Ablated Concept | Gandikota et al. | Kumari et. al. |
|---|---|---|
| Van Gogh | 21:23 | 6:41 |
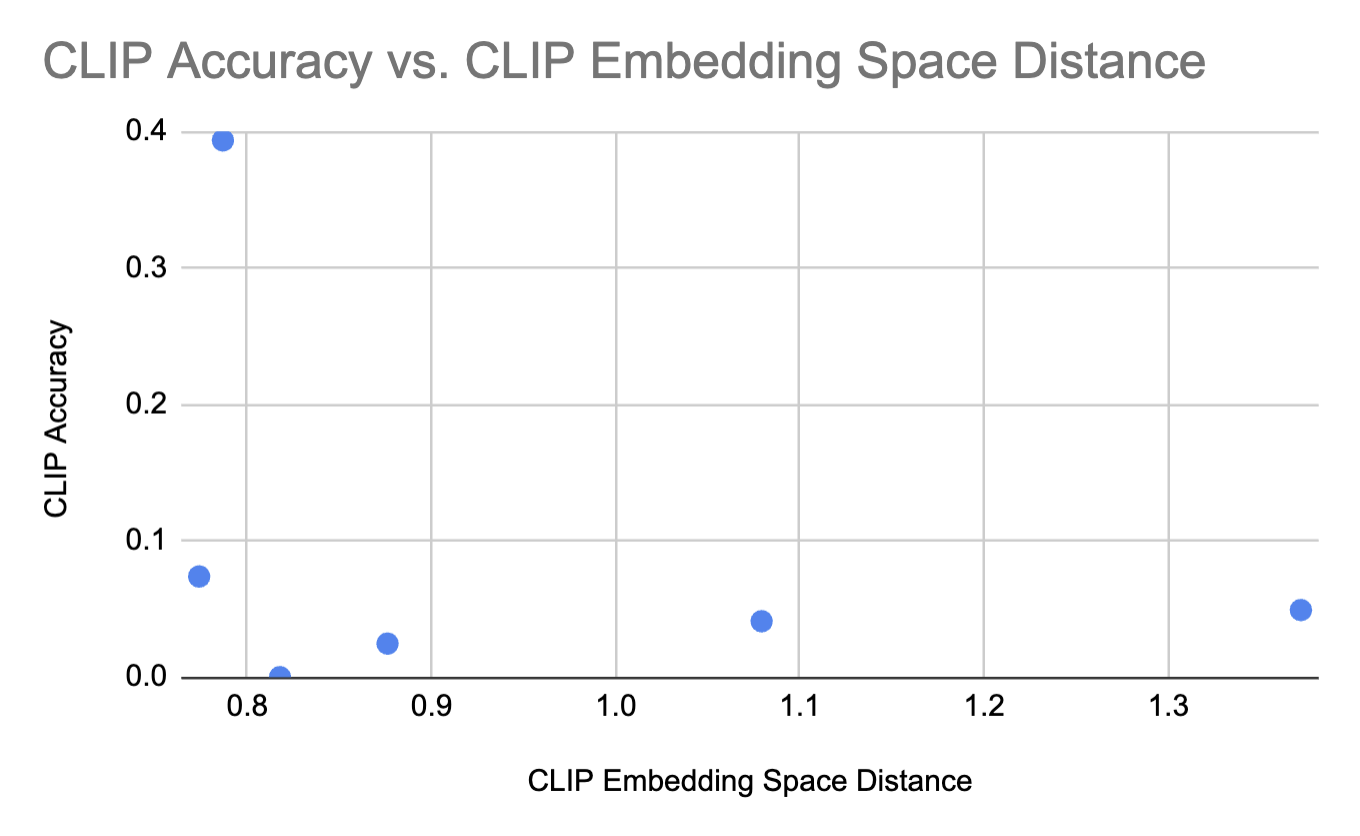
| Concept | Distance between Concept and Van Gogh in CLIP Embedding Space | CLIP Accuracy |
|---|---|---|
| painting | 0.8177 | 0.0 |
| monet | 0.7867 | 0.3934 |
| greg rutkowski | 1.0792 | 0.0410 |
| salvador dali | 0.7738 | 0.0738 |
| johannes vermeer | 0.8761 | 0.0246 |
| jeremy mann | 1.3720 | 0.0492 |
Discussion
For our experiments, we run concept ablation on two concepts - grumpy cat (instance example) and Van Gogh (style example). We compare the two models based on the running times, the CLIP scores for the erased concept and the surrounding concepts to the target concept, as well as an analysis on the variation of the CLIP accuracies based off the distance from the erased cocnept in the CLIP embedding space. From the results we can see that for Van Gogh the performances between the works of Gandikota et al and kumari et al are similar however that is not the case for Grumpy cats.One of the investigations we performed is on whether the distance between the embeddings of the erased concept and the surrounding concepts affect the level of interference. This can be seen from the clip scores for the surrounding concepts. From the table containing the distance between the distance between embedding scpae and CLIP accuracy that there is no correlation between the level of interference because the embedding distance is not inversely proportional to the CLIP accuracy for that surrounding concept. This is evident from the graph plotting the embedding space distance and the CLIP accuracies as well, like below:
In terms of the training time differences between the works of Gandikota et al. and Kumari et al. Both were trained to erase/ablate the concept of Van gogh and it is seen that the fist work takes roughly 21 min whereas the work of Kumari et al. only takes 7min to ablate the concept with similar CLIP scores. Thus this method by our experiments is faster.
References
[1] “SD-concepts-library (Stable Diffusion Concepts Library),” sd-concepts-library (Stable Diffusion concepts library). [Online]. Available: https://huggingface.co/sd-concepts-library. [Accessed: 27-Mar-2023].
[2] R. Gandikota, J. Materzynska, J. Fiotto-Kaufman, and D. Bau, ‘Erasing Concepts from Diffusion Models’, arXiv [cs.CV]. 2023.
[3] P. Schramowski, M. Brack, B. Deiseroth, and K. Kersting, ‘Safe Latent Diffusion: Mitigating Inappropriate Degeneration in Diffusion Models’, arXiv [cs.CV]. 2022.
[4] N. Kumari, B. Zhang, S.-Y. Wang, E. Shechtman, R. Zhang, and J.-Y. Zhu, ‘Ablating Concepts in Text-to-Image Diffusion Models’, arXiv [cs.CV]. 2023.