Real-Time Style Transfer for VR Experiences

Left and right eye stereoscopic style transfer
Project Summary
In this project, I look at implementing a fast real-time style transfer network within Unity for VR experiences. The idea originated from seeing work published by Unity that involves applying real-time style transfer for traditional video games that are rendered to a flat 2D output. Unity offers a library called Barracuda for running inference on neural networks allowing this to be possible. As a result, I thought it would be a novel application and effort to borrow these methods for rendering to a VR headset, an effort I did not see published on the internet.
The likely reason why style transfer has not explored VR options is due to a number of reasons. Firstly, VR requires a higher FPS than 2D-rendered games for a comfortable experience and as a result, requires the rendering of two images per eye and hence requires running the network twice per frame, which can be performance heavy. Secondly, visual artifacts are a lot more apparent to a VR user meaning that temporal consistency is important for the style transfer, which is a challenge to this method. Lastly, there needs to be spatial consistency between the style textures applied to the stereoscopic images such that they align to be perceived as one uniform image.
Working solely and within the short span of this project, my goals are to get a better understanding of this niche problem by first implementing a style transfer environment in VR, which will also help me develop an understanding of the aforementioned problems. Then, I will explore ways to improve the quality of style transfer output by looking at methods of training the style transfer network.
This project also hopes to have fun with the idea, exploring what this could mean for creating novel immersive experiences and interactions in the future.
Background
For implementing style transfer in Unity, Unity itself posted a blog post promoting its inference engine's ability to run style transfer in-engine. Another developer by the name of Christian Mills also posts on his blog and open-sources his projects regarding Barracuda and Unity. Mills' implementation of style transfer is what I will build on for my VR implementation.


Christian Mills running style transfer within Unity
There are also two works I found on this topic of style transfer given a stereoscopic image. Firstly, is style transfer for 360° images, which are viewed in VR. Secondly, a promising paper published called Stereoscopic Neural Style Transfer starts to address the issue of spatial consistency between the two rendered eye images. They developed an architecture for a tertiary loss in addition to the Style and Content Loss called the Disparity Loss. This helps condition the network to stylize a stereoscopic pair of images in ideally the same way. They find positive findings in their results, applying their style transfer to stereoscopic videos.
To train the fast style transfer networks, I am using an implementation based on the original paper Perceptual Losses for Real-Time Style Transfer and Super-Resolution. An implementation of this paper is found on the official PyTorch example repository.
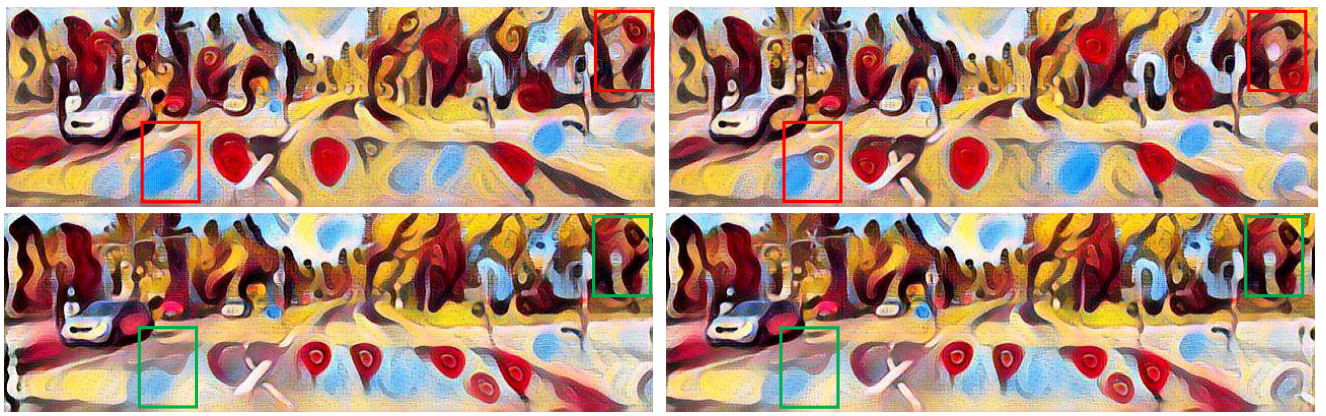
Baseline style transfer (top) vs style transfer with novel Disparity Loss (bottom) showing greater consistency between left-right stereo pairs
Methods
Test VR Environment
In order to test style transfer in VR, a generic 3D environment was built with some variation of color, shape, pattern, and pre-built assets.

Unity environment built to test out VR style transfer
To speculate further about applying style transfer to a VR experience, multiple style transfer networks are trained such that the user can cycle through different style images to augment their experience. On the right-hand controller, the trigger enables the cycling of styles, and the inner grip allows for turning style transfer on and off. This also helps when comparing different models and styles against each other. There’s also a UI feature where the image of the style image used to train that model is attached to the palm of the VR user's right hand so that the user knows what the current style is or can affect their experience.

VR palm displaying the current style image associated with the active network
Fast Style Transfer
Drawing from the architecture of the real-time style transfer network, we can train our own image to transform the network to be implemented in Unity. This network takes an RGB image as input and is defined by three initial convolutional layers, five residual blocks, and then three upsampling convolutional layers.
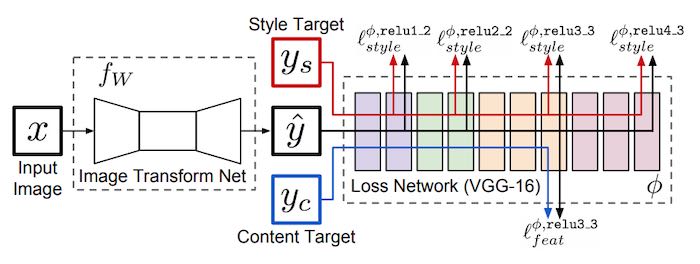
Architecture from the original fast style transfer paper
For the loss model, I use the VGG-19 model instead of the VGG-16 from the original paper. This pre-trained network will be useful for extracting the features when evaluating the content and style of the image.
The size of the layers in the model is parameterized by a filter tuple, which by default is (32, 64, 128). The issue with a network this size is that running inference in real-time for VR is not performant. A smaller network size of (8, 16, 32) seemingly works well enough for Unity inference on my current setup.
For training, I am using Adam optimization with a learning rate of 0.001. The loss for both style and content features is evaluated with mean squared error (MSE). For the inputs for training the network, I am using the COCO 2014 dataset, a collection of 82,783 images.
For weighting the Style and Content Loss the default weights used are:
- Content Weight = 1e5
- Style Weight = 1e10
The following style images are used:




Style Transfer to VR
In general, to make style transfer work in Unity, we need to write a custom C# script that handles the stylization with an ONNX file using the Barracuda library and a shader script that can process input and output images on the GPU.

Training to inference into Unity
Our shader script is a compute shader that has the simple functionality of processing the current camera input into a viable format for the style network. Simply, the style network process RGB images that range from [0,255], while Unity processes images in the range of [0,1]. Hence we need to write functions in the compute shader that multiply image values by 255 and inversely divide by 255, which is for converting the network output back to Unity.
Our style transfer script is a C# script attached to the primary VR camera and references the compute shader. To keep it simple, Barracuda makes it easy to natively reference ONNX files and create inference engines on the GPU that runs these models. Per frame, the currently rendered image is copied, stylized by the style network, then replaces the original image to be sent to the render display.
In order to render the VR headset display, I am using the Oculus XR plugin for Unity with the XR rig’s stereo rendering mode set to multi-pass. What this does is render each eye separately. This enables the sole VR camera to act as two cameras, one for each eye hence stylizing two images per frame.
Pseudo-Stereo Loss
When using the base style transfer network on stereoscopic pairs, especially noticeable in styles with more textural output, the two eyes in VR observe images whose styles do not spatially align. In the case of highly textural styles, you notice your eyes being tired within seconds of viewing. Less textural images and the experience can actually not be drastically noticeable, but still, tiring of the eyes occurs just over a longer span of a few minutes.
Stereo view with a network trained with the base style model
In order to account for this, I propose my own adjustment to calculating the losses for updating the image transform network that is loosely based on the ideas of the Stereoscopic Neural Style Transfer paper. In short, their idea included a Disparity Loss and another network that predicts the disparity of two stereo images. What this loss accounts for is the pixel-wise difference between the stylized stereo images in overlapping regions determined by the predicted disparity of the images.
Their code and results are unfortunately not open-source, meaning it would be an undertaking to implement for this project. Also, the base image transformer is a lightweight and simple single-image feed-forward network that allows for implementation in Unity to be a lot more straightforward.
In addition to the Content and Style Loss, I will call this addition the Pseudo-Stereo Loss, which is calculated with the original two style transfer losses with the VGG19 network. It is 'pseudo' because it is only there to act as an overly-simplistic warping of a single image from the COCO dataset, whereas in contrast to the Disparity Loss, is trained with synthetic stereoscopic pairs from the FlyingThings3D dataset. This is implemented using the Perspective transform from the Torchvision library, stretching the left-most edge to create the warped left image and the right-most edge for the warped right image. This is parameterized as a 10% increase to the given height of the input image.



Example transform applied to a single image to simulate a stereo pair of images
The Pseudo-Stereo Loss is quite simple, it takes the warped pair of images and stylizes them separately as input into the transform network. Their features are extracted with the VGG19 network and their MSE is calculated between their features, very similar to calculating the Content Loss. This loss is weighted and added as a tertiary sum to the total loss used to update the network. I try different weights to explore tuning the Pseudo-Stereo Loss, basing the weight on that of the Content Loss.
Lastly, it should be noted that having to calculate the Pseudo-Stereo Loss requires the same amount of computation as the Content and Style Loss combined. This has led to training time taking around twice as long.
Results
Stereoscopic Comparison
To test the Pseudo-Stereo loss, I take a look at the visual comparison between that of a number of different trained models on this particular style because, from this network, it had a particularly strong amount of visual artifacts:
Different weights of the Pseudo-Stereo Loss, from left to right:
(top) 0, 1e4, 1e5
(bottom) 5e5, 8e5, 1e6
Image-to-image, qualitatively it is noticeable the consistency of style transfer being done with the Pseudo-Stereo Loss compared to the model without when looking at the loss weighted 1e4 and 1e5. That being said, anything greater than 1e5, which I tested at varying degrees, makes the style transfer more prone to flickering and unstable. This is either due to the weighting of this loss being too strong and/or being greater than the Content Loss. Either way, having to tune three loss weights does make parameterizing these networks more difficult.
When it does make the experience better, it is because, between frames, it is more consistently stylized by the network, making it less of an eye strain. That being said, it is far from perfect in the details though perhaps makes the network ever so slightly more temporally consistent as well.

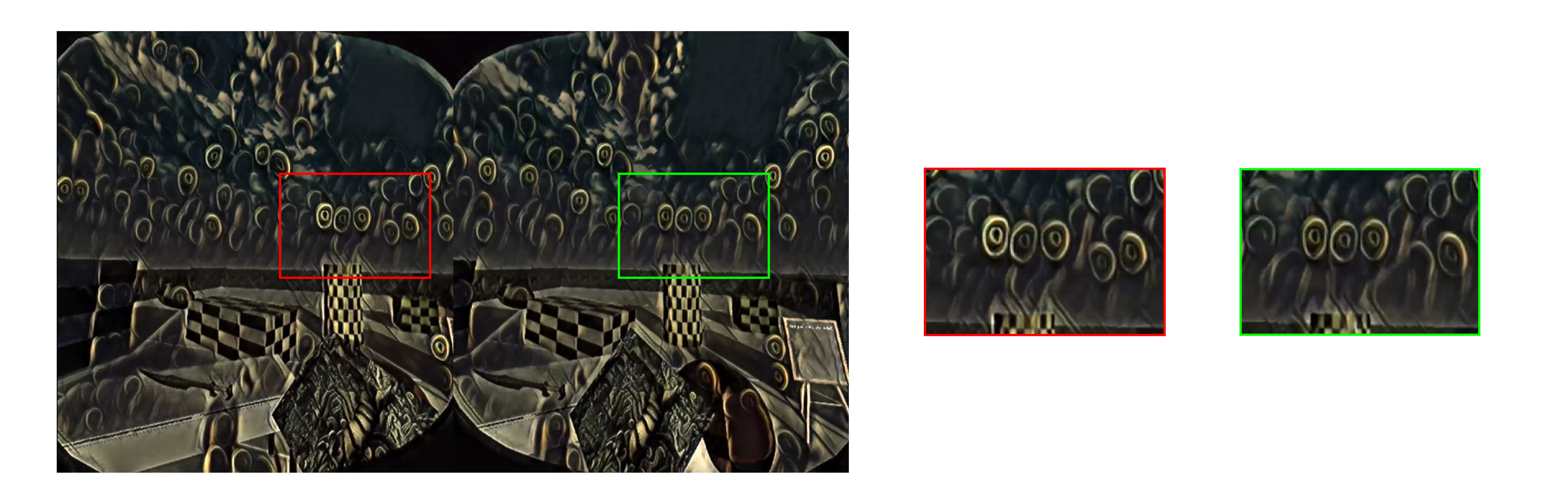

Comparing the left and right stereo images from different network outputs, from top to bottom: base, 1e4, 1e5
We see emerging characteristics that distinguish the networks based on the different weighting of the Pseudo-Stereo Loss for this particular style image and parameters. In the base network, the flickering textures often do not align causing tiredness to the eyes. In the 1e4 weighted network, you do get lots of flickering still, but they are better aligned spatially between eyes causing a noticeable difference in the VR headset. The 1e5 network eliminates the flickering largely altogether, meaning that the stereo output is actually experienced a lot more similarly for the most part. That being, said, oddly there are still a number of notable patterned textures that do not mostly align, similar to the base model.
One interesting takeaway is that despite the 1e5 network being imperfect, toning down the textural effects of the style image helps significantly for VR. Highly texture-style images also are notably difficult when it comes to temporal consistency in video-style transfer. It seems that the condition of the Pseudo-Stereo Loss can help tone down the style's textural output without decreasing the weight of the Style Loss either.
Let's take a look at another highly texture style that explores changes to the three loss weights:
Different loss weights (Content, Style, Pseudo-Stereo) from left to right:
(1e5, 1e10, 0), (1e5, 1e10, 1e5), (1e5, 1e9, 5e4), (1e5, 8e9, 8e4)
By default, the base network actually performs rather well, lending the addition of the Pseudo-Stereo Loss to have a negative qualitative effect, the most noticeable difference being less temporal consistency. Even if on a per-frame basis the stereo consistency is good, the constantly changing textural quality per frame can be overwhelming. We also can notice that the Pseudo-Stereo Loss again discourages textural details, removing the dots in the sky for a flat shade of black or white. This goes to show how careful we need to be with weighting our new loss, and it could likely be dependent on the current style and content images.
VR Experience
To help fully imagine what a VR experience would look like with style transfer, I implemented a simple system for cycling through the current runtime style network. This is a really fun and dynamic experience and helps us speculate what a potentially polished experience might look like.
Left eye footage within the VR expereince, cycling between different styles
Note that recording is a constant framerate and does not reflect experienced framerate within VR
Within my headset, switching networks does cause a drastic framerate drop, and I am already scaling down the network and lowering the resolution of the rendered images to help network performance. For comparison, without style transfer, the test VR environment runs at ~120 FPS, whereas turning on style transfer drops it to ~20 FPS. Typically for VR games your target is at least 45 FPS minimum, so this could potentially have issues, especially in dynamic environments, environments with lots of physics calculations, and models with high-poly counts.
That being said because I am running this all on my GTX 1660 ti GPU, it is outdated for even typical high-end VR performance let alone running style transfer. Say, such access to running locally a more recent RTX GPU, I can imagine that the VR experience with style transfer could be far better.
Conclusion
In conclusion, I hope my project can help us speculate the potential for style transfer to feature in video games and VR. We saw that introducing a new Pseudo-Stereo Loss value did have an effect on the network's outcome, which at times might be preferable, but it did lead to temporal instability and other types of artifacts. Though there are technical limitations, if this area of research was given more attention, I believe that more sophisticated architectures can make this effect very promising given that proper computing resources are used. Personally, I felt that the ‘wow’ effect of style transfer was felt more strongly in VR than in 2D, simply due to the immersive and surreal nature of it - it truly is incredibly trippy and in a unique way that I would reccomend someone to experience.

Targetted style transfer applied to a 2D image in the Unity environment
Something I had tried to implement and was not able to get working was targetted style transfer, where style transfer is only rendered to select objects in the scene via a masking layer. I had this working in 2D, but unfortunately not in 3D having trouble translating the 2D mask to the VR stereo views. I think for the sake of practical application, style transfer on an entire scene, especially in VR can be a lot. Having select objects allows for a more intentional application of style textures, which could be a really fun effect to play with. Imagine in VR, style transfer only activates once you touch an object - now wouldn't that be cool!