Final Project - Controllable LiDAR Scene Generation with Diffusion Models¶
- Haoxi Ran (hran@andrew.cmu.edu)
0. Project Overview¶
This project includes the following features:
- Section 1: Implementation:
- Section 1.1: Create Environment
- Section 1.2: Training
- Section 1.3: Sampling
- Section 1.4: Evaluation
- Section 2: Method:
- Section 2.1: Input Representation
- Section 2.2: Network Architecture
- Section 2.3: Training
- Section 2.4: Sampling
- Section 3: Experiments
- Section 3.1: Visualization
- Section 3.2: Evaluation
1. Implementation¶
1.1 Create Environment¶
To initialize a conda environment of this project:
conda env create -n lidar_diffusion -f environment.yml
conda activate lidar_diffusion
1.2 Training¶
To train a LiDAR Diffusion on Argoverse2 Dataset (To retrieve the training data, please refer to Argoverse 2 and download the Sensor Dataset):
python lidar_diffusion.py --train --exp argo2_lidardiffusion --config argoverse2.yml
1.3 Sampling¶
To sample from a pretrained model (We provide a pretrained model in Google Drive, feel free to download it and put it in the root directory!):
python lidar_diffusion.py --sample --exp argo2_lidardiffusion --config argoverse2.yml
1.4 Evaluation¶
To evaluate the model with the metrics of Maximum Mean Discrepancy (MMD) and Jensen–Shannon divergence (JSD):
python lidar_diffusion.py --mmd --exp argo2_lidardiffusion --config argoverse2.yml
python lidar_diffusion.py --jsd --exp argo2_lidardiffusion --config argoverse2.yml
2. Method¶
An overview of our method:
2.1. Input Representation¶
Our proposed method begins by converting the input parameterization, which is an unstructured point cloud that is sparsely distributed in Euclidean space, into a dense multi-channel equirectangular perspective image. This image has two channels that represent depth and intensity, respectively. The conversion process involves converting each point from its Cartesian coordinates into its spherical coordinates. Specifically, we use the following equations to perform the conversion:
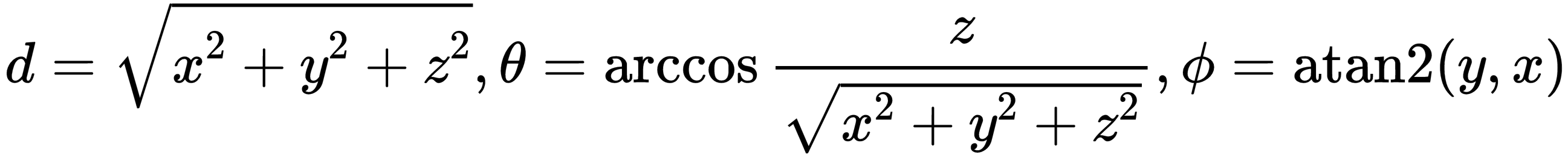
where $\theta$ is the inclination, $\phi$ is the azimuth, and $d$ is the depth range. We also remap the depth range so that it is normalized from 0 to 1.
To produce the two-channel rectangular image, we quantize the two angles and perform rasterization. Specifically, for each point $\mathbf{z}_i=(\theta_i, \phi_i, d_i), r_i$, we use the following equation:
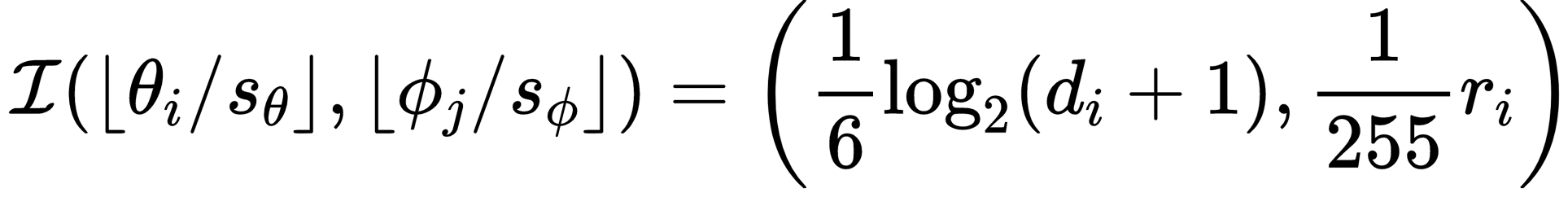
Both channels of the image are normalized to the range (0, 1), and we use a logarithm mapping to ensure that nearby points have a higher geometry resolution. Throughout the rest of the section, we will also use $\mathbf{x}$ to represent the point cloud in its equirectangular representation.
Our input representation has several benefits. Firstly, it encodes information into a dense and compact 2D map, which allows us to leverage efficient network architecture transferred from the 2D image generation domain. Secondly, due to the ray-casting nature of the spinning LiDAR scans, most scans will only return the peak pulse for each beam. Therefore, encoding the point cloud into this representation will not result in any information loss, and the generated point cloud properly reflects the scanning and ray-casting nature of the sensor.
2.2. Network Architecture¶
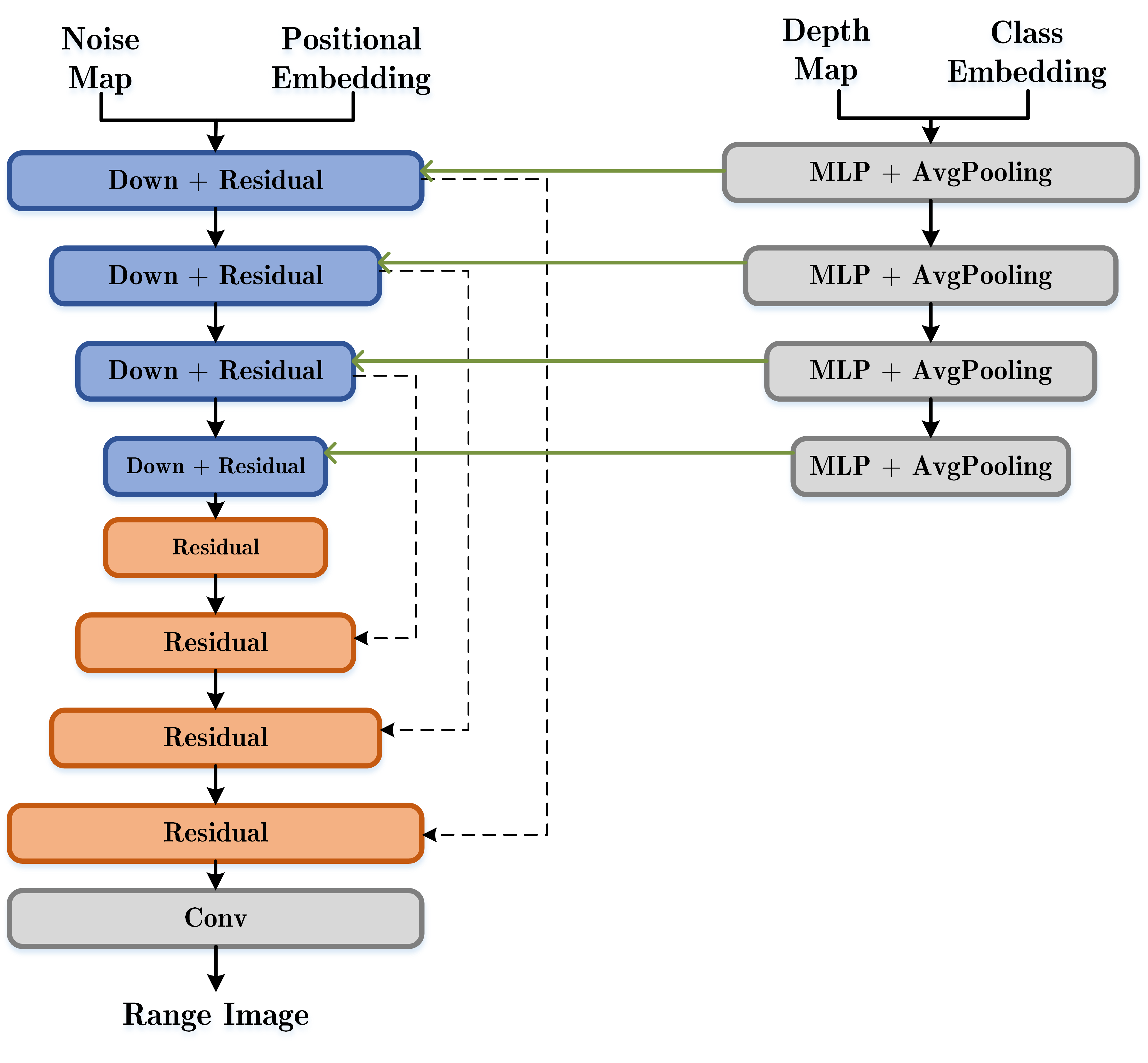
The U-Net architecture is a well-known convolutional neural network (CNN) that is widely used for image generation tasks due to its success in capturing both global and local features of an image. The architecture consists of an encoder that downsamples the input image to a lower dimensional feature map and a decoder that upsamples the feature map to the original image size. At each level of the encoder and decoder, skip connections are used to concatenate the feature maps with the same size to preserve spatial information. In this work, the U-Net architecture is adapted for our score-based network $s_\theta$. The circular convolution is used to take into account the circular nature of equirectangular images. Besides, with the backbone of U-Net, we design a condition branch to control the results given the condition (i.e., 3D keypoints). This branch enables us to generate an expected range image. The architecture of the network is shown in the above figure.
2.3 Training¶
Training denoising score matching models can be challenging due to the need to select a proper noise level. The choice of noise level heavily influences the accuracy of score estimation, and in practice, we find that having a noise-conditioned extension is crucial for the success of the model. Specifically, we expand our score network $s_\theta({\mathbf{x}}, \sigma_i)$ to be dependent on the current noise perturbation level $\sigma_i$. During training, we use a multi-scale loss function, with a re-weighting factor for the loss at each noise level, following the noise-conditioned score-matching model. The multi-scale loss function is defined as:
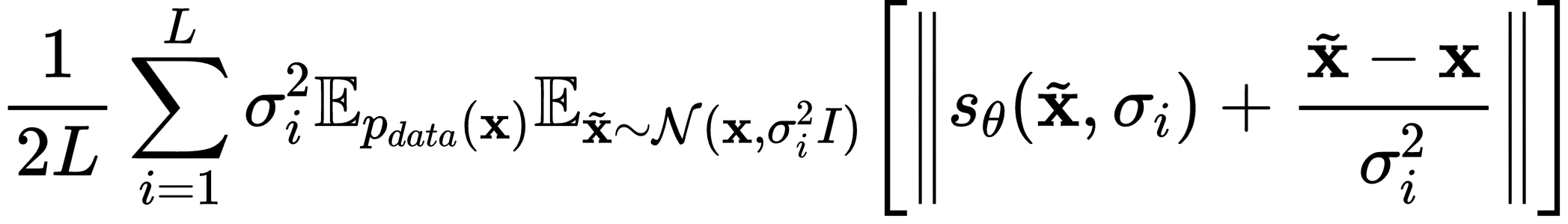
where $\tilde{\mathbf{x}}$ represents the randomly perturbed noisy signal at each noise level, and $\sigma_i$ denotes the standard deviation of the noise distribution.
2.4 Sampling¶
We utilize annealed Langevin dynamics sampling in our point generation task to improve sampling efficiency. To be more specific, we begin by setting the noise level to its highest pretrained value, and gradually decrease it during the sampling process:
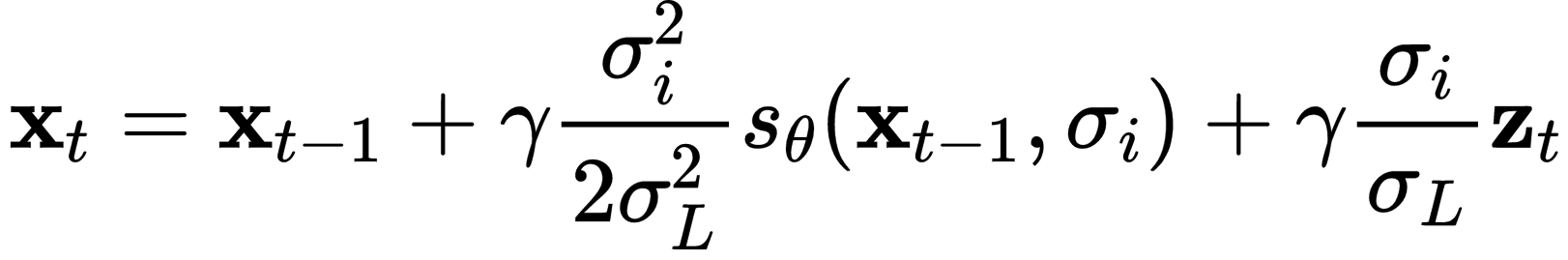
where $\gamma$ and $\sigma_L$ means the learning rate and the smallest noise level, respectively. After gradually reducing the noise level, we obtain a clean equirectangular range image using the final step of Langevin dynamic sampling. This image is then unprojected back into 3D Cartesian space to recover the 3D point cloud.
3. Experiments¶
3.1 Visualization¶
| Epoch | Ground Truth | Sample 1 | Sample 2 | Sample 3 | Sample 4 | Sample 5 | Sample 6 | Sample 7 | Sample 8 |
|---|---|---|---|---|---|---|---|---|---|
| range image |  |
 |
 |
 |
 |
 |
 |
 |
 |
| Point Cloud (BEV) |  |
 |
 |
 |
 |
 |
 |
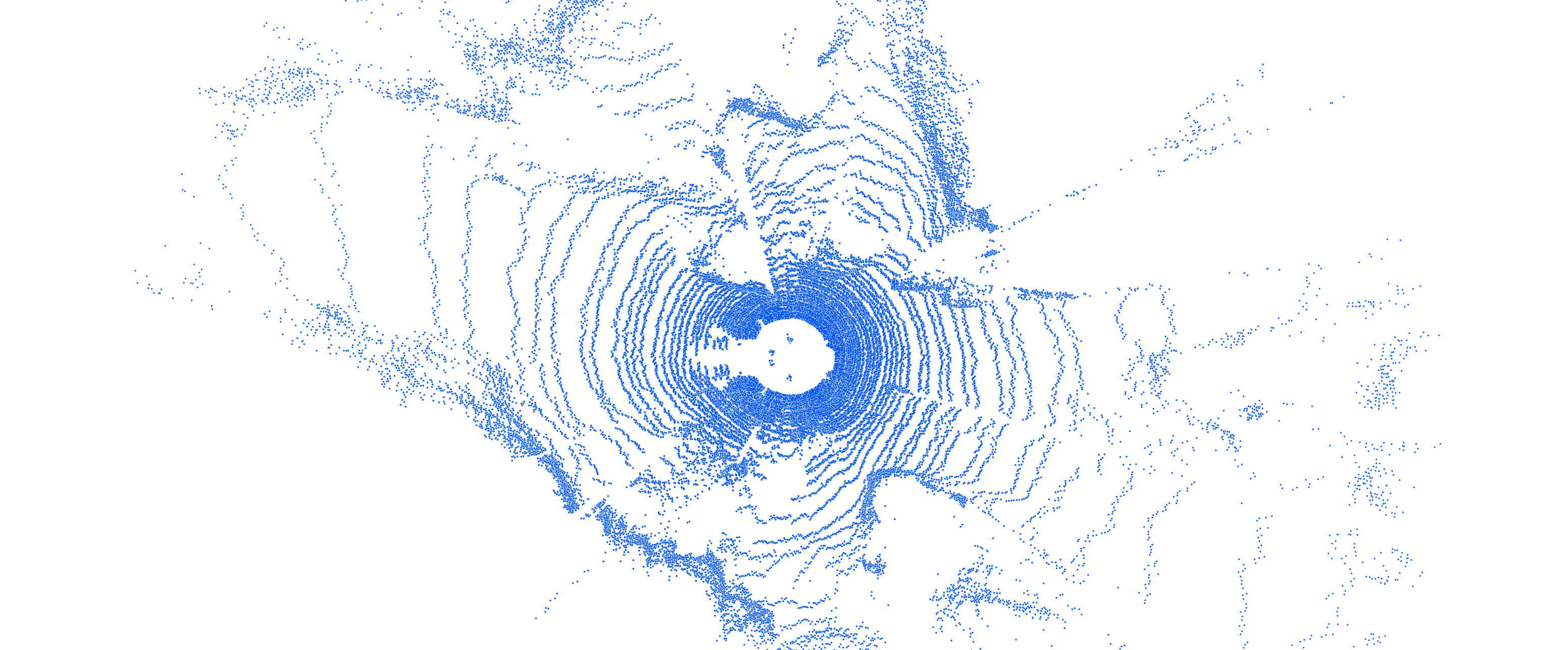 |
 |
| Point Cloud (Frontal) |  |
 |
 |
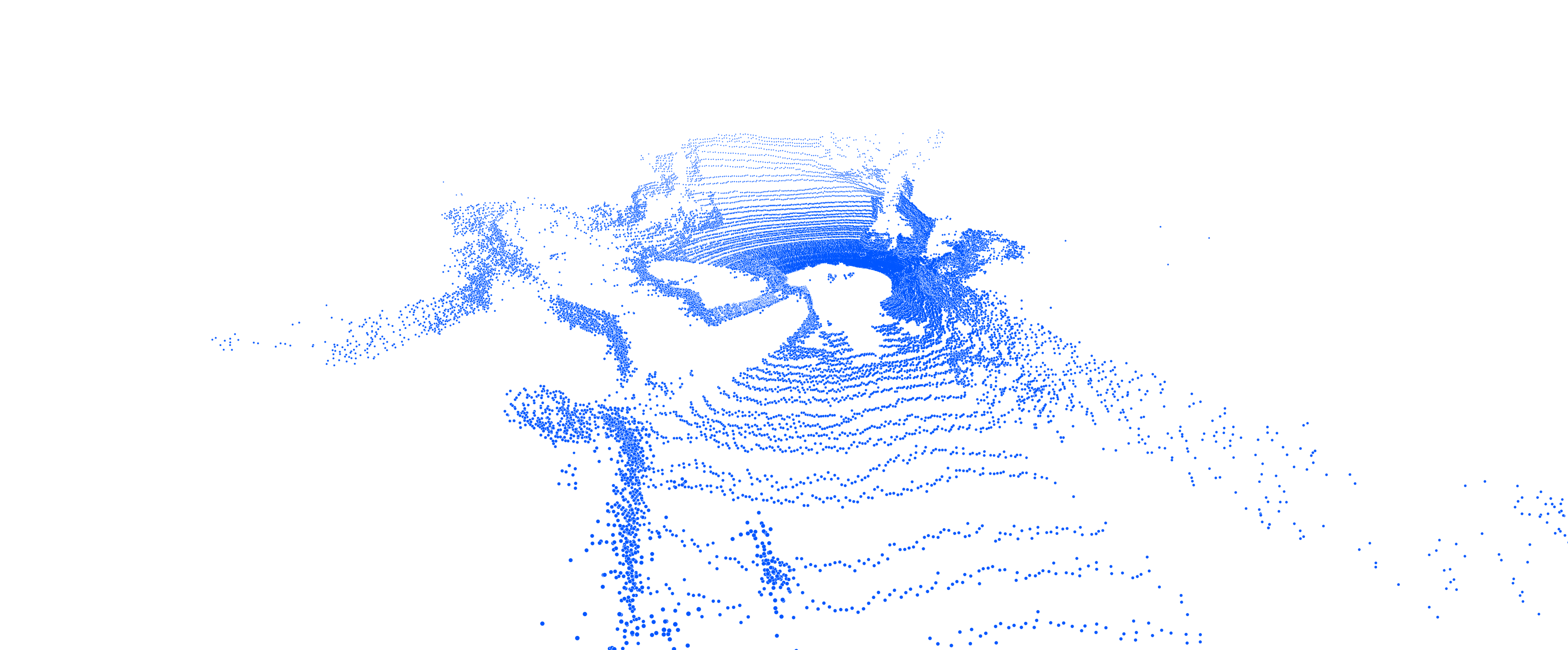 |
 |
 |
 |
 |
 |
3.2 Evaluation¶
| Method | Naive | w/ condition branch |
|---|---|---|
| MMD (lower is better) | 4.55 × 10−4 | 3.23 × 10−4 |
| JSD (lower is better) | 0.076 | 0.058 |
Acknowledgement¶
We develop our project based on the codebase of LiDARGen. We thank the authors for their work.