Introduction
Recent developments in the field of stable diffusion, notablely DDPM and DDIM, have yielded great promises in the field of text-conditional image generation. More recent work has explored more into incorporating diffusion models in video generation, notablely Video Diffusion Models and Imagen Video. A key problem in video generation, compared with image generation, is to ensure temporal consistency in the generated video, or more plainly expressed, how much the video looks like a natural video with continuity opposed to a combination of images forming a non-smooth image sequence. Current state-of-the-art methods solve the problem of temporal inconsistency by explicitly adding temporal modules in the network, such as the Temporal Attention / Convolution modules in Imagen Video. While these approaches produce convincing results, the clear drawback of these methods is their limitations in the length of the video generated and the efficiency in generating long videos, as the temporal modules require an input component for each frame in the temporal sequence, thus the network is only capable of producing a short video with a length pre-determined during training, and to obtain a longer video one must train a larger network, which is computationally prohibitive in most cases to train for video generation as short as minutes. Alternatively, one may GAN-based video extension methods, usually guided by a certain condition such as human pose movements (ie. Post Guided Human Video Generation). However, these methods are relatively older, and yield video results of much lesser quality when compared with current SOTA methods. Another limitation for these methods of video generation is that, similar to many image generation methods, the generated result may frequently be different from the user's intention, as text is limited in its capability of expression, and the user may have specific requirements hard to be described by a short text, while an intention-specific text prompt may require expertise in prompt engineering.
A very recent work, ControlNet, proposed a powerful framework for conditional stable diffusion image generation, allowing for highly controlled image generation for any stable diffusion networks. The method is highly versatile, as it utilizes any pre-trained diffusion models, keeping the pre-trained weights to ensure stable generation results, and train on a copied version of the network with fine-tuning weights, represeneting the control condition. ControlNet allows for image generation with arbitrary image-conceivable conditions, such as poses, canny edges, normal maps, sketches, etc. This image-wise controllable stable diffusion approach opens up possibility for high-quality controllable long video generation, as the image-wise processing nature of the method allows processing arbitrary length videos by applying each image sequentially, with no further requirements for the model components to adjust for video generation. In this project, we explore this possibility with several novel approaches based on this concept, and experiment with the results.
ControlNet
The approaches to video generation is highly related to the recent work of ControlNet. An overview of the concept of ControlNet can be observed in Figure 1. By locking the pre-trained weights of the original networks, ControlNet ensures the results of the image generation would not degrade from the original pre-trained network, while the conditional image c is passed in through a zero convolution network, added with the original input to go through a trainable copy of the weights in order to process of features with the guidance of the control condition, then perform another zero convolution before adding the processed controlled features back to the original pipeline. The zero convolution layers are 1x1 convolutional layers with weights and biases set to zero, which serves as an automatic guidance regulator for the control condition in order to generate the desired results given by training data.
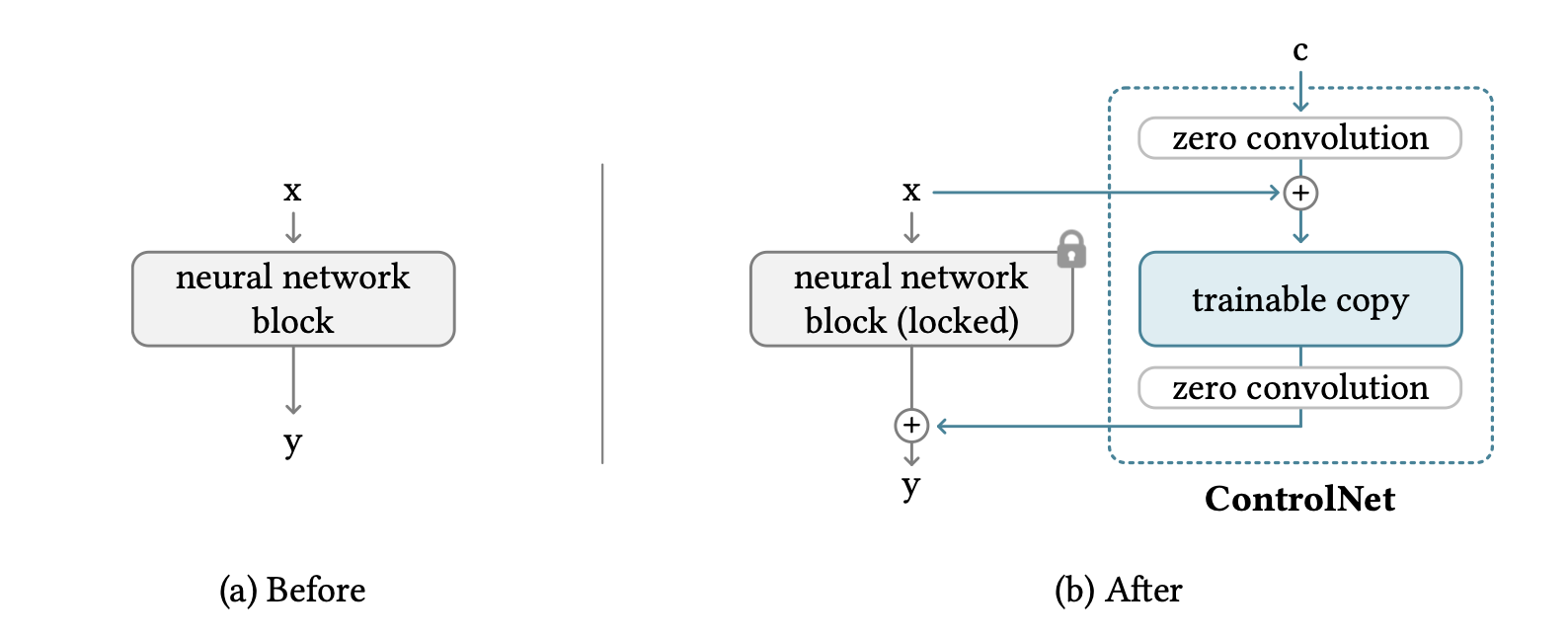
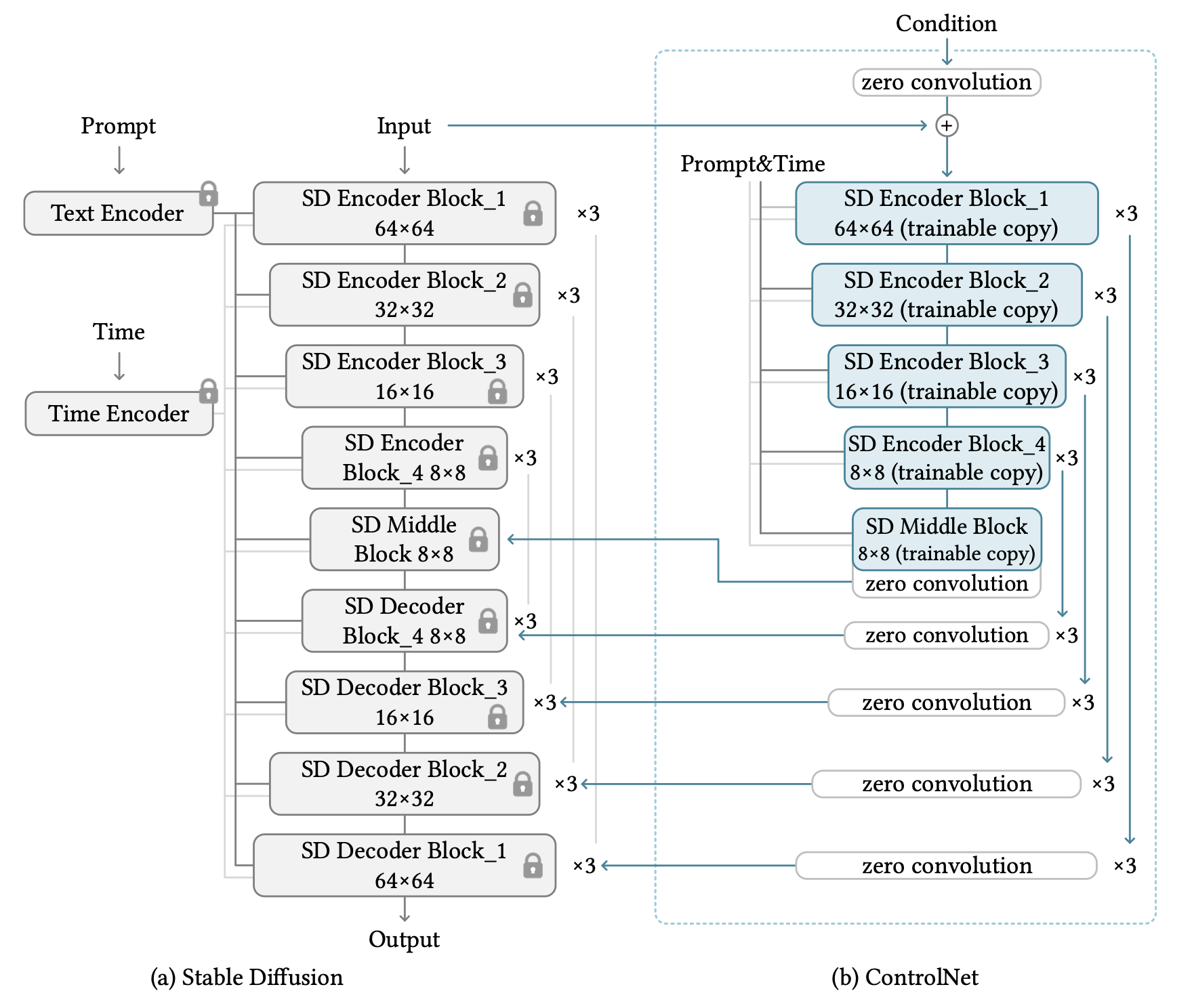
This ControlNet addition can be applied to arbitrary neural network blocks, thus yielding many possible combinations of network control methods. With the example of stable diffusion, the authors recommended controlling only the encoder and middle blocks of the stable diffusion, while training with also controlling decoder blocks can be problematic depending on the training dataset quality. This architecture, based on SD V1.5 or SD V2.1, is shown in Figure 2.
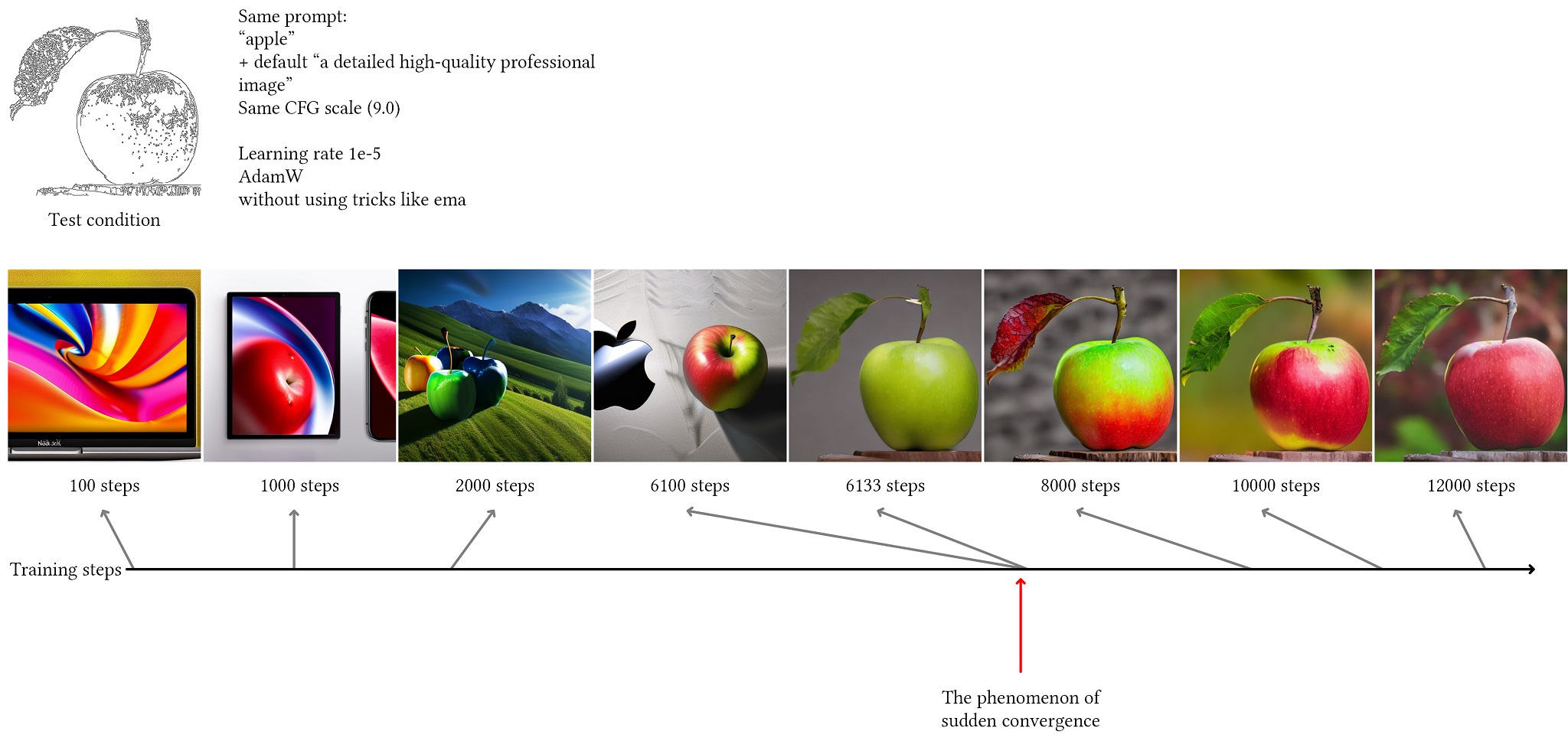
In the training process, the authors highlighted a phenomenon referred to as sudden convergence, illustrated in Figure 3. After a certain number of steps, the network will suddenly converge towards generating results that clearly fit the training conditions, as shown in the training logs of the apple image at step 6133. This phenomenon is also observed in our work discussed below.
Due to the addictive nature of the feature conditioning in the ControlNet architecture, ControlNet is easily extendable to Multi-ControlNet, a simple addition of multiple control condition features with parallel trainable copies with different feature conditions. This property allows image generation with ControlNet to be given multiple independent control conditions, with the network automatically balancing the guidance from each of the conditions based on training dataset and a guidance hyperparameter. This property is especially useful for some potential ControlNet-based video generation approaches to be discussed further.
Problem Formulation
To guide our exploration, we first define specific video generation task as our goal. As human pose movement is a simple and effective control condition, and previously proven to work with ControlNet image generation, we aim to generate an arbitrary length video with the a fixed text prompt as a basic conditioning, and a video of human pose movement of the same length as a ControlNet condition. The guidance of human pose movement is added as a preliminary condition as we aim to show that the video is controllable by a certain condition, instead of merely generating a sequence of consistent images, and human pose movement is a well-comparable condition based on previous researches.
Dataset Preparation
The MSR-VTT dataset is a large video description dataset that contains 38.7 hours of 30 FPS web video clips with corresponding human-written text description for the videos. For our training, we preprocess the dataset by extracting the videos frame-by-frame to and organize them sequentially. The first text description is chosen as the corresponding description for each group of video frames. In our training, we use the selected description as the input text prompt to the stable diffusion model, and subsample the frames once every 5 frames (hence downsample the videos to 6 FPS) for training, as the original full 30 FPS dataset is prohibitive for training given computational resources. After subsampling, we use the i-th frame as input condition and (i+1)-th frame as desired output for training in approach 2. We decided to use subsampling instead of using a smaller dataset, as the frame-by-frame difference between images are too small to allow for sufficient training observations.
To generate the corresponding appropriate human pose video dataset, we use the openpose framework and pre-trained pose estimation models to generate the human poses available in the MSR-VTT dataset. Videos without a single detected human pose are excluded from the dataset.
Approach 1: Image-Wise Fixed-Noise Generation
The first approach we attempted is a simple image-wise generation. We process each image independently, while also decompose the guiding condition of human pose video into frames of the same 30 FPS and impose single pre-trained ControlNet of openpose with text prompt input. One caveat is that, instead of using randomized latent noise for each image generation, we fixed the randomnization to the same seed in order to achieve a naive consistency among each image generated to promote video temporal consistency. The developments in the video are controlled by the developments from the openpose video.
This naive approach yielded well-constructed results beyond expectations, with a few selected examples shown in Figure 4 and Figure 6, with their corresponding control condition shown in Figure 5 and Figure 7.

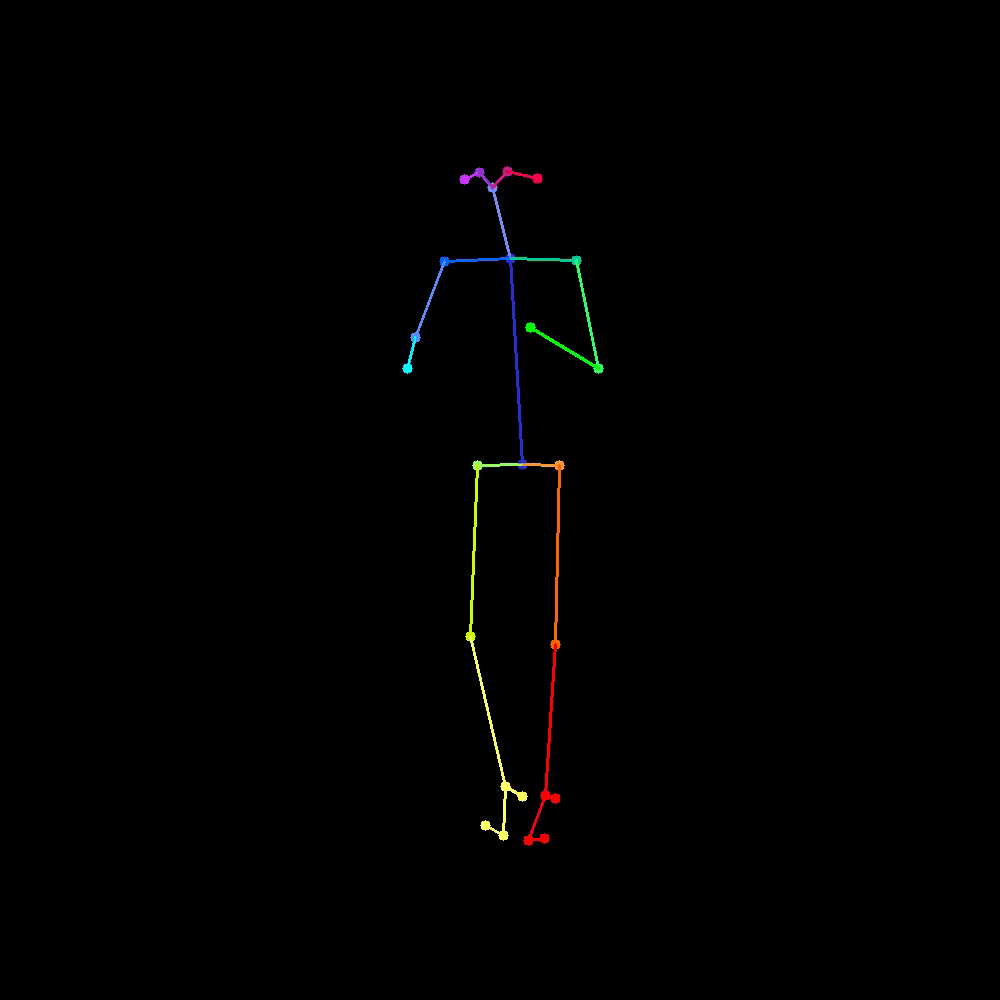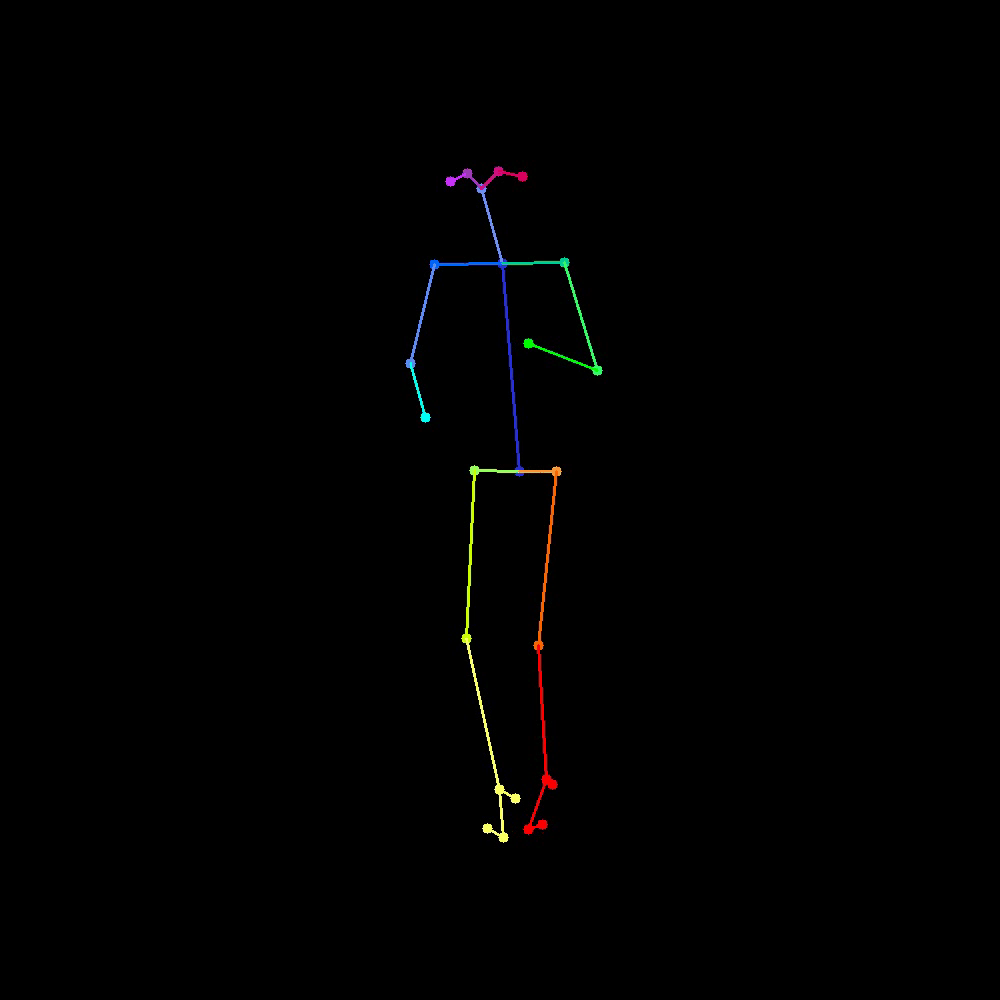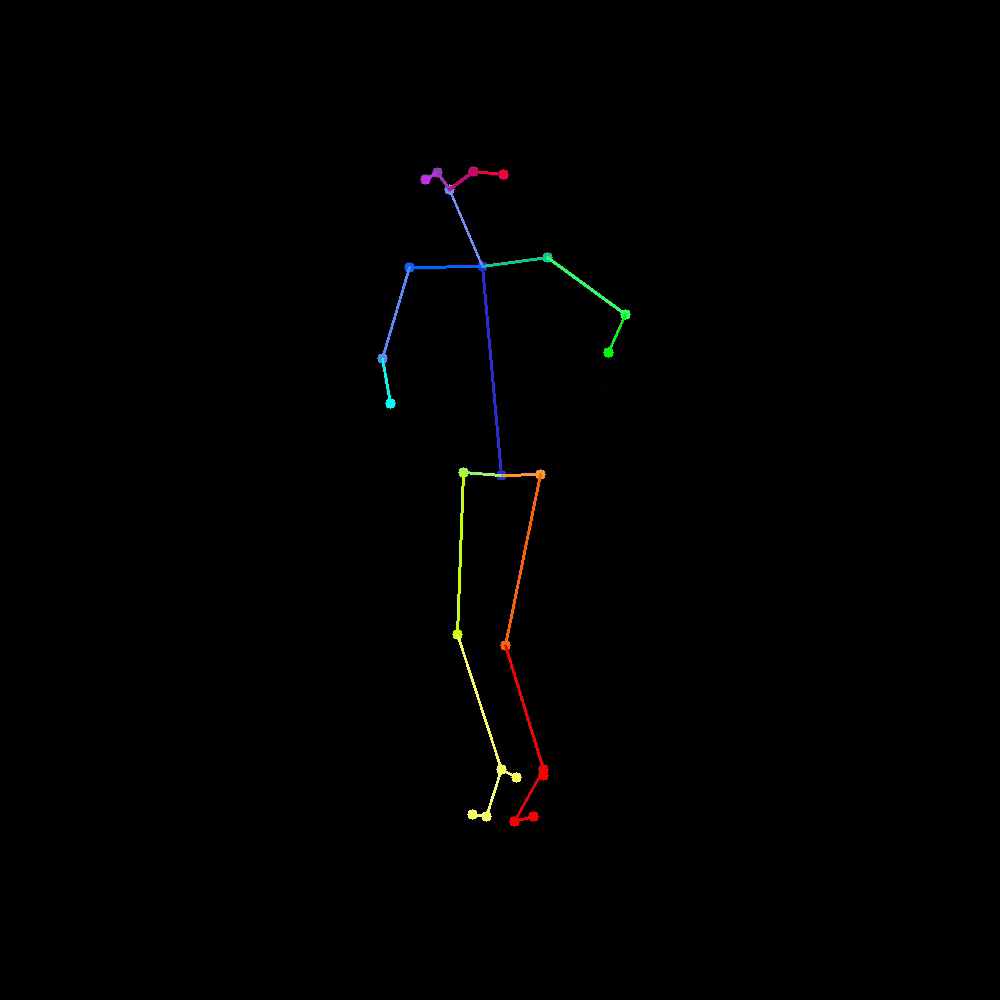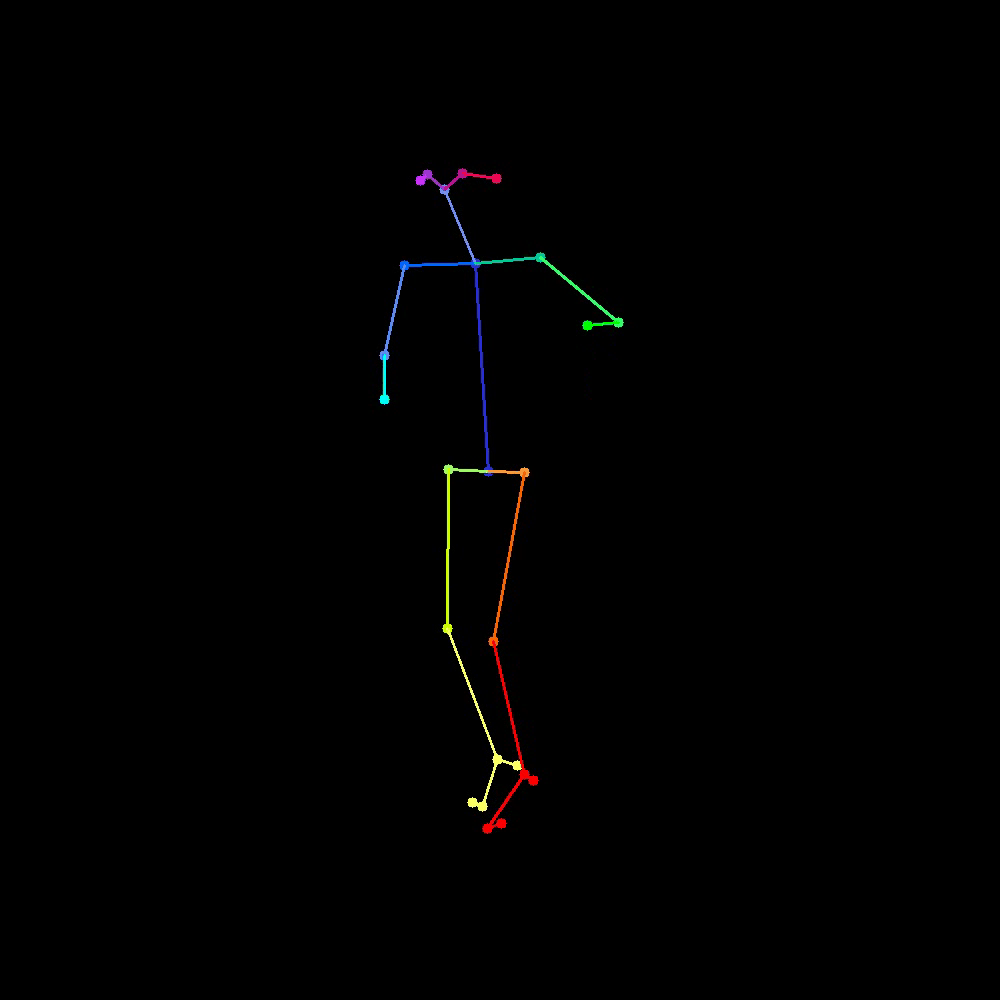


As we can observe, with a fixed randomness of noises, the generated video is capable of obtaining similar frames even though generated independent of each other. The complete independence in the frame generation process allows for us to generate an arbitrary length video using this method based on the control condition, with guarantee of non-degrading result. However, this naive approach does yield non-negligible temporal inconsistency specifically due to this complete independence.
Approach 2: Multi-ControlNet Conditioned by Previous Frame
To fix the temporal inconsistency problem from Approach 1, we propose an additional ControlNet condition, where the input condition is the previous frame of the video, and the desired output is the current generated frame. Due to the addictive nature of ControlNet, this additional condition can be implemented in parallel with the previous openpose control. As their feature addition is independent of each other, we can train the ControlNet for temporal consistency with fixed weights for the pre-trained neural network block for openpose, but unlocked zero convolution weights and biases for the pre-trained openpose ControlNet. A detailed illustration for a block in this architecture is shown in Figure 8.
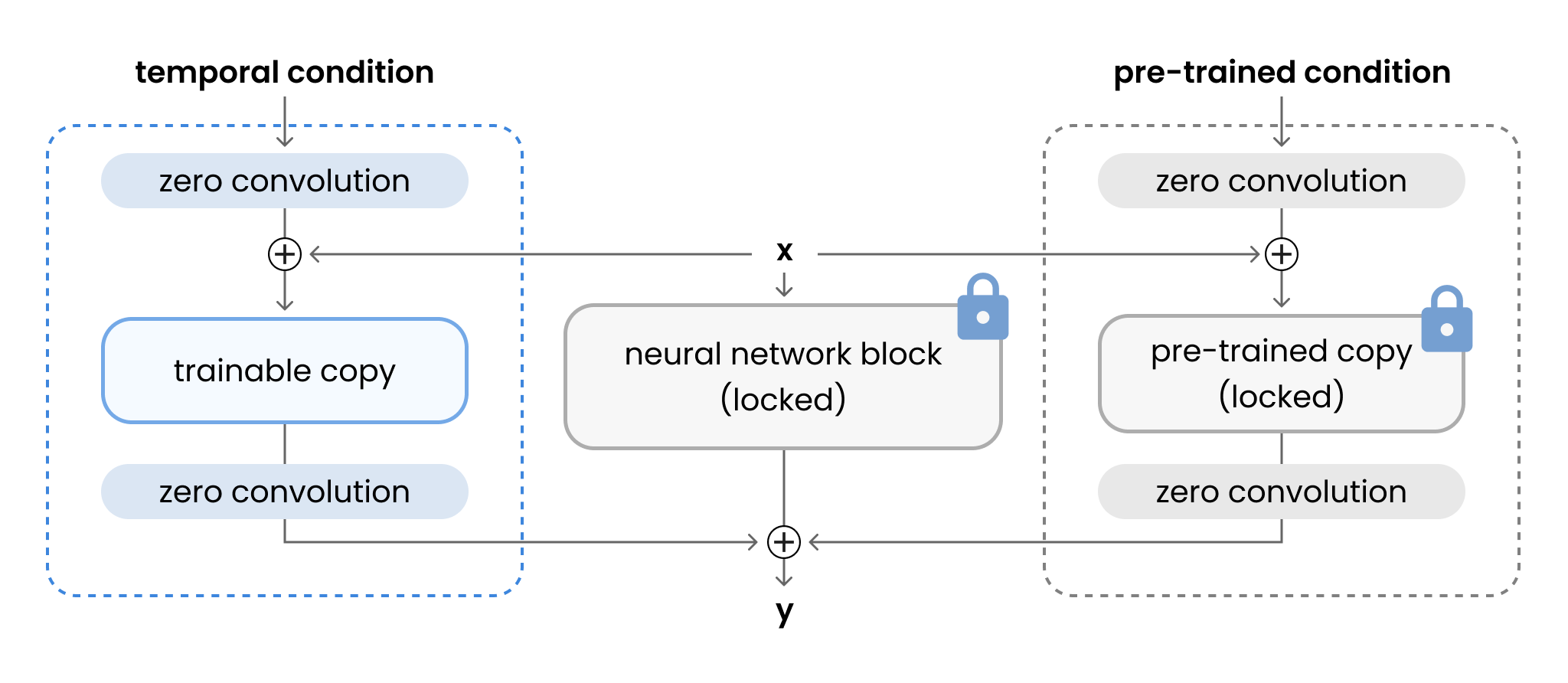
In our experiment, we follows ControlNet's adaptation of SD V1.5 as the base model. As we have to copy the entire neural network blocks into the ControlNets while also keeping the original locked weights, the resulting model is almost 3 times as large as the original model. We fixed the input and output images to be 512x512x3 to keep the high quality generation enabled by ControlNet. Our experiment is modified based on ControlNet's original official implementation. However, due to the larger model size and input image dimension, we have to optimize the training process for GPU memory in order to avoid out-of-memory situations. Following advice by the authors of ControlNet, we used batch size of 1 and gradient batch accumulation of 4, as well as adding additional memory optimizations throughout the process. This reduced the GPU memory requirements in our experiment to at least 16 GB, which is now feasible for a Nvidia V100 GPU.
Finally, video generation is achieved first by using standard stable diffusion to generate a starting image, then subsequent images are generated by ControlNet conditioning of openpose and the previous frame.
It is worth noting that training the ControlNet must not be using a fixed seed for generating noises, as it is theoretically likely to fail, as it is equivalent to asking the stable diffusion process to learn a single way for adding noises that allow a reconstruction result that is similar to all inputs. To the date of May 6th, 2023, we are training multiple models simultaneously, with the maximum training step of 100,000, taking 63 hours on one Nvidia V100 GPU. However, at present we have yet to observe the sudden convergence phenomenon described by the authors. Our current generated image results are far from similar to the condtiion given from previous frame. Although the authors trained each of the ControlNet conditions for hundreds of GPU-hours, with a maximum of 600 GPU-hours on Nvidia A100 80G, we expect much less training time for our case, as we expect an output image very similar to the input condition. We will update this page once we observe the sudden convergence.
Approach 3: ControlNet of ControlNet
As a future work, we propose an alternative more intuitive approach. As the expected generation result of next frame is in fact not only dependent upon the previous frame, but also the expected human pose (or any other control conditions guiding video movements), a more reasonable approach is to utlize the property of ControlNet that it may be added as a modification to any diffusion-based models. Instead of training a ControlNet for temporal consistency in parallel to other locked pre-trained ControlNets such as openpose ControlNet, we propose the architecture of ControlNet of ControlNet, locking the weights of the entire pre-trained ControlNet architecture (including zero convolutions) along with the pre-trained stable diffusion model, then construct a new trainable copy of the entire pre-trained ControlNet. This allows the model to learn to generate the next frame specifically following the model framework that movement control module (such as openpose ControlNet) is a separate module than the original image feature generation. This architecture is illustrated in Figure 9. The concept of ControlNet of ControlNet can be further extended to any ControlNet-based image generation methods with explicit dependencies of different level of control conditions.

One key problem with this approach is that it may easily result in a very large model architecture, resulting in prohibitive computational resource requirements for training, hence this approach is listed as a future work to be explored.
References
Ho, Jonathan, Ajay Jain, and Pieter Abbeel. "Denoising diffusion probabilistic models." Advances in Neural Information Processing Systems 33 (2020): 6840-6851.
Song, Jiaming, Chenlin Meng, and Stefano Ermon. "Denoising diffusion implicit models." arXiv preprint arXiv:2010.02502 (2020).
Ho, Jonathan, et al. "Video diffusion models." arXiv preprint arXiv:2204.03458 (2022).
Ho, Jonathan, et al. "Imagen video: High definition video generation with diffusion models." arXiv preprint arXiv:2210.02303 (2022).
Yang, Ceyuan, et al. "Pose guided human video generation." Proceedings of the European Conference on Computer Vision (ECCV). 2018.
Zhang, Lvmin, and Maneesh Agrawala. "Adding conditional control to text-to-image diffusion models." arXiv preprint arXiv:2302.05543 (2023).
Xu, Jun, et al. "Msr-vtt: A large video description dataset for bridging video and language." Proceedings of the IEEE conference on computer vision and pattern recognition. 2016.
Cao, Zhe, et al. "Realtime multi-person 2d pose estimation using part affinity fields." Proceedings of the IEEE conference on computer vision and pattern recognition. 2017.