Method
|
|
|
| This is a final course project for 16-726 Learning Based Image Synthesis in Spring 2023. |
| We propose Latent Light Field Diffusion (LLFD), an approach to generating 3D scenes using a discretized light field representation. Existing 3D generation approaches adapt score distillation sampling (SDS) and use text-image diffusion models for 3D scene optimization; however, they are time consuming and do not generate diverse outputs. Instead of optimizing a 3D representation, we directly generate a set of posed images (light field) that capture the 3D appearance of a scene. This alternate 3D representation enables us to efficiently generate diverse 3D scenes by sampling from the distribution of light fields. We evaluate our method on large-scale 3D dataset, Objaverse, and highlight its advantages over prior works. |
| Novel View Synthesis. Just as we observe the 3D world through 2D projections from multiple viewpoints, we can reason about 3D by generating novel views of objects and scenes. Early works on novel view synthesis (NVS) use deep convolutional neural networks to directly regress features for novel views [1, 2, 3]. Many works also incorporate 3D reasoning through intermediate representations such as multi-plane images [4, 5], point clouds [6, 7, 8], volumes [9], and meshes [10, 11]. More recently, large generative models show great results without reasoning about geometry explicitly [12, 13, 14, 15]. While these methods are able to generate realistic, novel-view images conditioned on input and a target camera pose, multiple novel views of the same scene are often not 3D consistent, making it hard to use extract an explicit 3D representation for downstream tasks. |
|
|
|
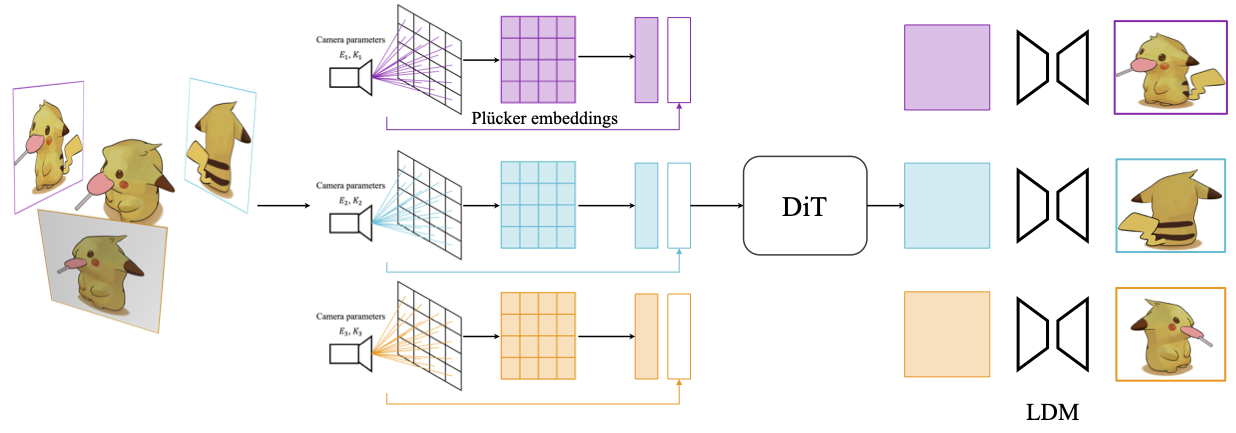
Our proposed LLFD consists of three main components: Ray Embedding, Diffusion Transformer, and Latent Diffusion Model. The entire procedure is as follows: The model takes a few input images and their camera poses as input. The input images are first fed into a pretrained VAE model to get latent codes. For the camera poses, we choose the first image as the reference image and compute the relative camera poses of the others. Then we extract pluecker coordinates from the camera poses and feed them into a Ray Embedding model to get ray embeddings. The ray embeddings and latent codes are then fed into the Diffusion Transformer together with a time step embedding. Noice is added to latent codes with a level t. The latent diffusion model is then used to predict the noise level and produce the denoised images. During training, the number of visible images are randomly chosen from 1 to 3, while the others are set to random noise. The model is trained to genete the masked images. During inference, the model can generate multi-view images simultaneously conditioned on the input images. The number of input images can be arbitrary. If the number is 1, then the model is performing single-view 3D generation. The model is trained on the large-scale Objaverse dataset, where the categories inside are very diverse. The model is able to generate diverse 3D scenes with high quality. |
|
Here're the results of our proposed LLFD model. We train our model on the large-scale Objaverse dataset, where we sample 750K 3D scenes as training set and the remaining 50K as test set. For each 3D scene, we use blender to render 24 images from different views. The views are randomly chosen from a sphere.
The first row shows the input images. The second row shows the generated images from Diffusion Transformer. The third row shows the denoised images from Latent Diffusion Model. The last row shows the ground truth images.
|
| Next, we present the multi-view image generation as gif, with only one image with ramdom camera pose as input. As shown below, our method can produce diverse and realistic 3D scenes across different categories, which shows strong generalization ability. |

|

|

|

|

|

|
|
[1] Tinghui Zhou, Shubham Tulsiani, Weilun Sun, Jitendra Malik, and Alexei A Efros. View
synthesis by appearance flow. In ECCV, 2016.
[2] Maxim Tatarchenko, Alexey Dosovitskiy, and Thomas Brox. Multi-view 3d models from single images with a convolutional network. In ECCV, 2016. [3] Ersin Yumer Duygu Ceylan Alexander C. Berg Eunbyung Park, Jimei Yang. Transformation- grounded image generation network for novel 3d view synthesis. In CVPR, 2017. [4] Richard Tucker and Noah Snavely. Single-view view synthesis with multiplane images. In CVPR, 2020. [5] Tinghui Zhou, Richard Tucker, John Flynn, Graham Fyffe, and Noah Snavely. Stereo magnifi- cation: Learning view synthesis using multiplane images. In SIGGRAPH, 2018. [6] Olivia Wiles, Georgia Gkioxari, Richard Szeliski, and Justin Johnson. SynSin: End-to-end view synthesis from a single image. In CVPR, 2020. [7] Ang Cao, Chris Rockwell, and Justin Johnson. Fwd: Real-time novel view synthesis with forward warping and depth. CVPR, 2022. [8] Chris Rockwell, David F. Fouhey, and Justin Johnson. Pixelsynth: Generating a 3d-consistent experience from a single image. In ICCV, 2021. [9] Eric R. Chan, Koki Nagano, Matthew A. Chan, Alexander W. Bergman, Jeong Joon Park, Axel Levy, Miika Aittala, Shalini De Mello, Tero Karras, and Gordon Wetzstein. GeNVS: Generative novel view synthesis with 3D-aware diffusion models. In arXiv, 2023. [10] Andrew Liu, Richard Tucker, Varun Jampani, Ameesh Makadia, Noah Snavely, and Angjoo Kanazawa. Infinite nature: Perpetual view generation of natural scenes from a single image. In ICCV, October 2021. [11] Ronghang Hu, Nikhila Ravi, Alexander C. Berg, and Deepak Pathak. Worldsheet: Wrapping the world in a 3d sheet for view synthesis from a single image. In ICCV, 2021. [12] Robin Rombach, Patrick Esser, and Björn Ommer. Geometry-free view synthesis: Transformers and no 3d priors. In CVPR, pages 14356–14366, 2021. [13] Jonáš Kulhánek, Erik Derner, Torsten Sattler, and Robert Babuška. Viewformer: Nerf-free neural rendering from few images using transformers. In ECCV, 2022. [14] Daniel Watson, William Chan, Ricardo Martin-Brualla, Jonathan Ho, Andrea Tagliasacchi, and Mohammad Norouzi. Novel view synthesis with diffusion models. In ICLR, 2023. [15] Ruoshi Liu, Rundi Wu, Basile Van Hoorick, Pavel Tokmakov, Sergey Zakharov, and Carl Vondrick. Zero-1-to-3: Zero-shot one image to 3d object, 2023. |
|
|



