Let's Try And Pose?
16-726 Learning Based Image Synthesis Final Project by Anusha Rao (anushasa), Greeshma Karanth (grk), and Ninaad Rao (ninaadrr).
The code for this project can be found here.Introduction.

In recent years, the surge in online shopping has resulted in intense competition among brands.
As a result, it is crucial to make products look appealing and attractive to potential customers.
This is especially true when it comes to the fashion industry.
Usually when shopping for outfits, people tend to try on clothes before buying them. This project is essential
in providing the same try-on experience to people virtually, letting them experiment with the clothes on
themselves before deciding to purchase them.
Objectives.
Towards the goal of making fashion more accessible to customers virtually, this project aims to accomplish two main objectives.
- 1. Virtual Try On
- Enable virtual try-on of clothing items on a person without using 3D information.

- 2. Pose Transfer
- Change the pose of the person in an image to display different angles of the
product.

These two objectives help customers understand the product better and give small businesses an equal opportunity to showcase their products in a superior way.
Dataset.
The dataset used in this project is the DeepFashion dataset [database].
The DeepFashion dataset is a large-scale clothing dataset that contains over 800,000 clothing images and associated meta-data, including category, style, occlusion, zoom-in, viewpoint, and landmark annotations. The images in the dataset are of high quality and resolution, and they cover a wide range of clothing categories, such as T-shirts, dresses, pants, and jackets, as well as a variety of styles, colors, and patterns.

The DeepFashion dataset is divided into three parts: the In-Shop Clothes Retrieval Benchmark, the Consumer-to-Shop Clothes Retrieval Benchmark, and the Fashion Landmark Detection Benchmark.
- The In-Shop Clothes Retrieval Benchmark contains images of clothing items in a shopping context, and it is intended for evaluating retrieval algorithms for clothing items.
- The Consumer-to-Shop Clothes Retrieval Benchmark contains images of clothing items in a consumer context, and it is intended for evaluating retrieval algorithms for online shopping scenarios.
- The Fashion Landmark Detection Benchmark contains images of clothing items with annotated landmarks, and it is intended for evaluating landmark detection algorithms for clothing.
The dataset has been widely used in the fashion and computer vision research communities for tasks such as clothing retrieval, attribute recognition, landmark detection, and style analysis. The "Dressing In Order" and "Pose With Style" papers implemented in this paper both use the DeepFashion dataset for fashion-related tasks, such as outfit recommendation and pose estimation. Specifically, they use data from the In-Shop Clothes Retrieval benchmark.
Task 1: Virtual Try On.
Virtual try-on is a technology that allows customers to try on clothing and accessories virtually. It utilizes computer vision and augmented reality to create a virtual representation of the product and superimpose it onto the user's image or live video feed.
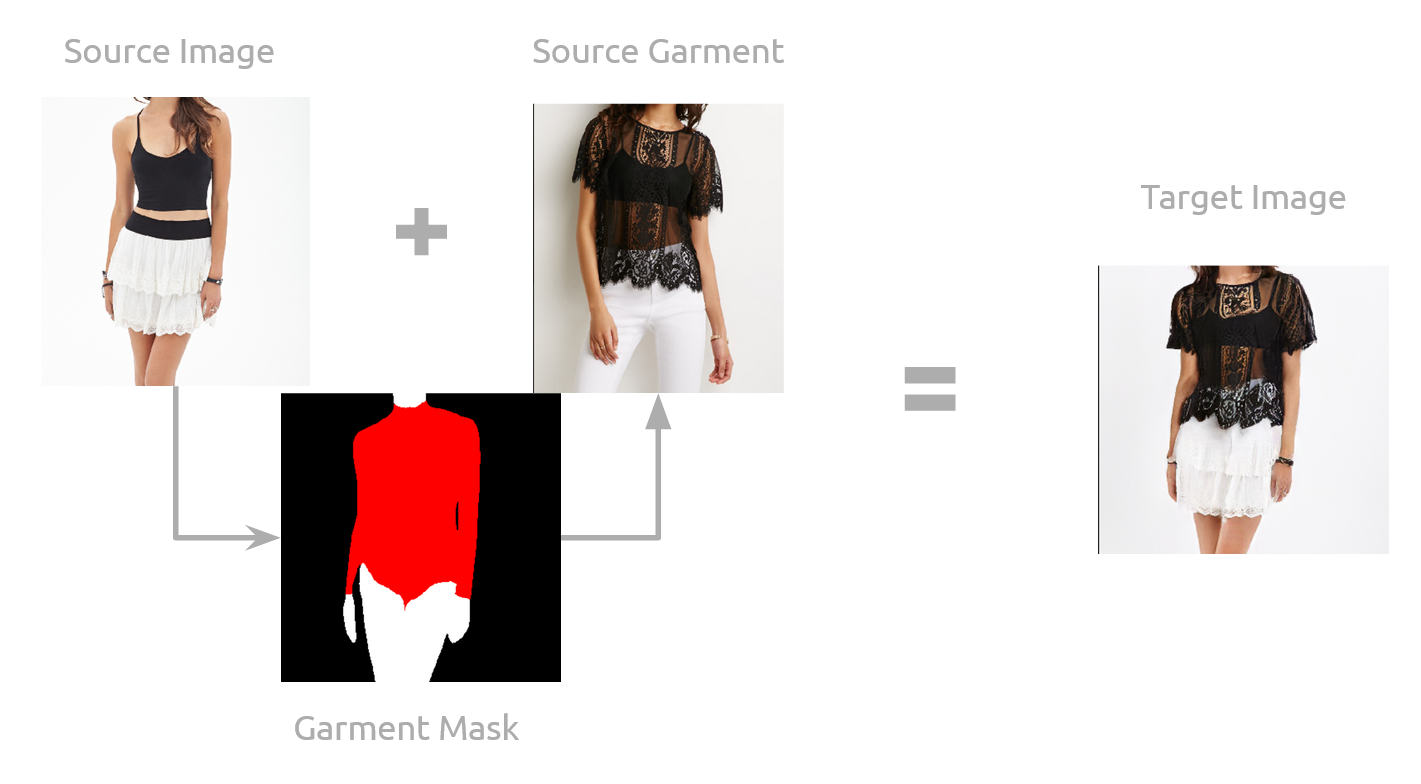
Our Virtual Try On Process
1. Pose with Style: Detail-Preserving Pose-Guided Image Synthesis with Conditional StyleGAN
In the "Pose With Style" paper, the authors introduce a novel approach to virtual try-on that involves transferring garments between different poses and body shapes while preserving garment details, such as shape, pattern, color, and texture, as well as person identity, such as hair, skin color, and pose. This is achieved by extending the StyleGAN generator with spatially varying modulation, which allows for more fine-grained control over the synthesis process.

The resulting virtual try-on system is able to produce high-quality, visually appealing results that demonstrate the potential of this approach for improving the online shopping experience and enabling more personalized and interactive fashion recommendations. By leveraging spatially varying modulation, the virtual try-on system in the "Pose With Style" paper is able to better capture the complex interplay between garment shape and body shape, leading to more accurate and realistic virtual try-on results.
In particular, spatial modulation is a technique used in computer vision and deep learning to adapt the output of a generative model to a specific input condition. In the case of the Pose With Style paper, spatial modulation is used to adapt the output of the StyleGAN generator to the specific pose and body shape of a given person.
The spatial modulation technique extends the StyleGAN generator with a set of learnable modulation functions that modulate the feature maps produced by the generator at different spatial locations. These modulation functions are conditioned on the input pose and body shape of the person, and they help to preserve the details of the garment (such as its shape, pattern, color, and texture) while also preserving the identity of the person (such as their hair, skin color, and pose).
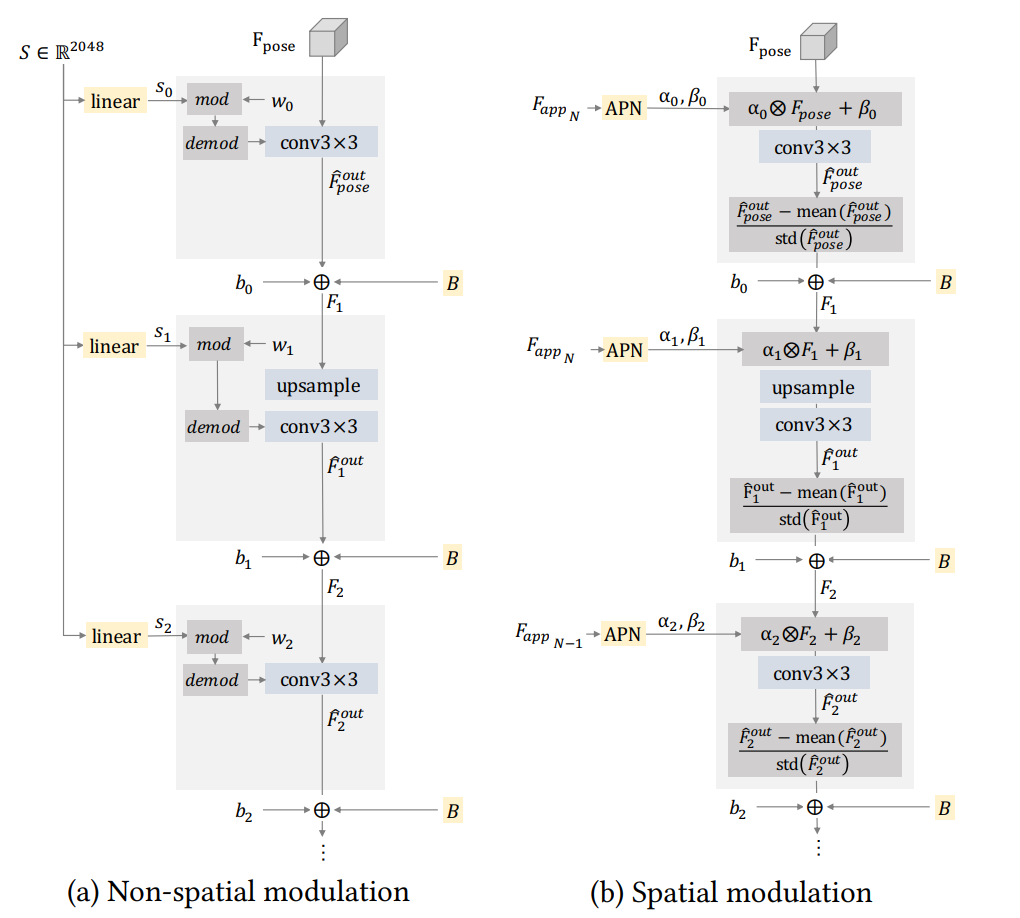
In traditional non-spatial modulation, StyleGAN2 modulates and demodulates the weights of the convolutions using a learned style vector. However, spatial modulation proposed in the paper modulates the mean and standard deviation of the features instead. This is done using shifting and scaling parameters, 𝛼 and 𝛽, generated by the affine parameters network (APN), before the convolution. The output of the convolution is then normalized to zero mean and unit standard deviation before adding the bias and StyleGAN2 noise broadcast operation.
By using spatial modulation, the Pose With Style paper is able to generate realistic images of people wearing different garments, in different poses and body shapes, while preserving the details of the garments and the identity of the people. This approach has important implications for the fashion industry, as it enables customers to more easily and accurately visualize how a garment will look on them before making a purchase. Additionally, the authors demonstrate how their approach can be extended to enable cross-domain virtual try-on, in which garments from one style or category are transferred to a person in a different style or category, further expanding the possibilities for personalized fashion recommendations.
Our Results

Example 1

Example 2
The model is trained to take in the 6 images to produce the desired result, the silhouette of the clothing, 3D UV pose coordinates, and the original RGB image for both target and source images. The results show two variations of try-on, upper body garment transfer in the first row, followed by lower body garment transfer in the second row. As observed from the results, the model performs better with similar kinds of clothing, but when the clothing is shifted from say shorts to pants, the model is unable to complete certain parts of the legs.
2. Dressing in Order: Recurrent Person Image Generation for Pose Transfer, Virtual Try-on and Outfit Editing
In the "Dressing In Order" paper (DiOr), the authors propose a novel approach for recurrent person image generation that enables pose transfer, virtual try-on, and outfit editing. The authors introduce a recurrent generator architecture that consists of a pose encoder, a feature transformer, and a decoder. The model is trained to generate a sequence of person images conditioned on a sequence of target poses.
For the virtual try-on task, the model learns to transfer clothing items from a reference person image to a target person image. The authors propose a differentiable renderer to enable end-to-end training and optimize a combination of reconstruction loss, adversarial loss, and style loss to generate realistic clothing transfers.

DiOr explicitly encodes the shape and texture of each garment, enabling these elements to be edited separately. Joint training on pose transfer and inpainting helps with detail preservation and coherence of generated garments. Extensive evaluations show that DiOr outperforms other recent methods in terms of output quality, and handles a wide range of editing functions for which there is no direct supervision. The system also takes into account factors like body shape and pose, ensuring that the clothing looks realistic and conforms to the person's body.
Overall, the Dressing In Order virtual try-on system is designed to help people visualize how different clothing items will look together, reducing the need for physical try-ons and helping to streamline the shopping process.
Our Results

Example 1

Example 3

Example 5

Example 7

Example 2

Example 4

Example 6

Example 8
The poses of the source and target photographs have a significant impact on how well the virtual try-on works. When looking at the outcomes for the male model, the garment transfers were successful when both the source and target positions were front-facing, with the exception of the fourth image, where the model failed to transfer both items of clothing. This is a similar challenge to the pose transfer problem, where solving for complicated clothing pieces proved difficult for the model. The transfer of the back pose was seamless when the poses were different, but the side poses led to an overlay of the two pieces of clothing, as shown in the case of the female model.
Same Color Try On

The same color try-on yielded good results for the displayed images. However, a limitation of the model was its inability to accurately identify the outline of the clothing item, as evident in the output where the model mistakenly classified the try-on cloth as a t-shirt instead of a vest.
Same Garment Transfer but with Different Pose

Example 1

Example 3

Example 2

Example 4
The results obtained for the same person wearing the same clothes but in a different pose were satisfactory. As illustrated in the above images, the model successfully captured the correct texture and color. However, the model struggled with multiple layers of clothes, as evident in the first image.
Gender Swap Try On

Example 1

Example 3

Example 2

Example 4
Some of the results from the gender swap experiment weren't working out as intended. As seen in the fourth image, this can be linked to the images' contrast and brightness levels. However, the model generated good results when the light levels were comparable. As seen in the third figure, a flaw in the model can be seen in the back posture transfer, where the outcomes were unsatisfactory. One possible explanation for this could be the model's inability to distinguish between the woman and the fabric in the source image.
Analyzing Racial Bias

Example 1

Example 3

Example 2

Example 4
During the analysis and evaluation of the model's potential racial bias, no signs of bias were observed, and the results generated were satisfactory.
Task 2: Pose Transfer.
Pose transfer is a technique that has shown great potential for the fashion industry, particularly for virtual try-on applications. By transferring the pose of a person onto a target garment, virtual try-on systems can realistically simulate how the garment would look on the person, allowing customers to try on clothes without physically being in a store. This can greatly enhance the online shopping experience and increase customer satisfaction.

Our Pose Transfer Method
Pose transfer also has the potential to improve clothing design and manufacturing, as it allows designers to see how garments look and move on real people before they are produced. Furthermore, it can help reduce the environmental impact of the fashion industry by reducing the need for physical prototypes and samples.
1. Pose with Style: Detail-Preserving Pose-Guided Image Synthesis with Conditional StyleGAN
In the "Pose With Style" paper, the authors propose a detail-preserving pose-guided image synthesis method that can generate high-quality images of a person in a given pose while preserving fine-grained details such as clothing textures and accessories.

The method consists of a conditional StyleGAN network that takes as input a target pose and a style code, which is a latent representation of the desired style, and generates a corresponding high-resolution image. The pose transfer is achieved by first extracting the pose information from the input image using a pose estimator and then conditioning the StyleGAN on this pose information. The authors also introduce a new conditional discriminator that encourages the generated images to match the target pose while preserving the details.
In particular, the authors use DensePose to extract the image-space UV coordinate map per body part (IUV) for both the source and target poses. DensePose is a method for dense human pose estimation that can assign UV coordinates to each point on the surface of a human body, enabling the IUV representation. This IUV map is then used to guide the conditional StyleGAN to generate the final image in the target pose while preserving details and textures from the source image.
Our Results

Example 1

Example 2
The model is trained to take in 4 images to produce the desired result, the silhouette of the clothing, 3D UV pose coordinates, the original RGB source image, and the target pose coordinates. As observed from the results, despite the face-loss component, the model is not able to complete the body structures in a very detailed manner. Additionally, the model fails in maintaining ethnic diversity.
2. Dressing in Order: Recurrent Person Image Generation for Pose Transfer, Virtual Try-on and Outfit Editing
"Dressing In Order" paper (DiOr) supports 2D pose transfer, virtual try-on, and several fashion editing tasks using Recurrent Generation Networks. It aims to produce a dressing effect by ordering the garments and including various interactions like shirt tuck-in, layering, etc. It jointly trains on pose transfer and inpainting to preserve the details and coherence of the generated garments. DiOR is the current state-of-the-art and it outperforms all other existing models for pose transfer. The authors propose a novel method for pose transfer based on recurrent person image generation. They use a sequence of generative models that transfer the pose of a source image to a target pose while preserving the appearance of the person.

In this paper, the authors propose a system for pose transfer that consists of three main components: a global flow field estimator, a segment encoder, and a body encoder.
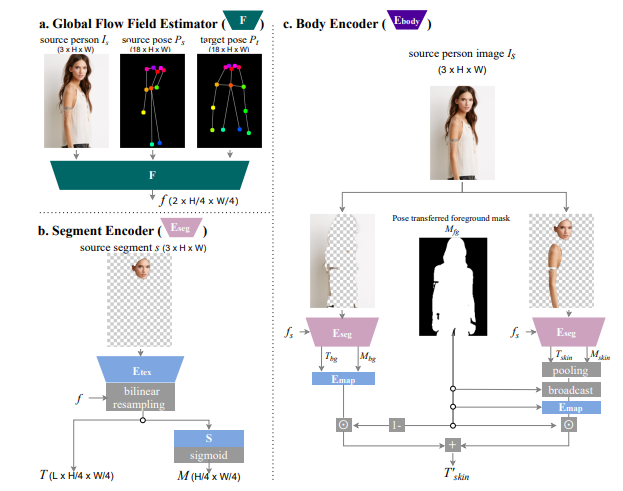
- The global flow field estimator, which is adopted from GFLA, estimates a dense flow field that describes the correspondence between the input image and the target pose. This flow field is then used to warp the input image to the target pose.
- The segment encoder takes the input image and the target pose represented as an image-space UV coordinate map per body part (IUV) extracted from DensePose. It produces a spatially aligned texture feature map T and a soft shape mask M. The texture feature map captures the appearance of the clothing and the shape mask captures the shape of the person.
- The body encoder takes the pose-transferred foreground parts and encodes them into a mean skin vector. This mean skin vector is then broadcast to the entire foreground region (union of the masks of pose-transferred foreground parts) and mapped to the correct dimension by Emap for later style blocks. This enables the model to preserve the appearance of the skin while transferring the pose.
Our Results

Example 1

Example 3

Example 5

Example 2

Example 4

Example 6
There are three main poses of interest:
- the front pose transfer
- the side pose transfer
- the back pose transfer
Same Color Transfer

With similar colors, the transfer was quite realistic. One drawback is that the method doesnt capture accessories into consideration. For example, the cap has been deformed in the target image and the style is transferred similar to the target pose.
Same Person Transfer

Example 1

Example 3

Example 2

Example 4
The DeepFashion dataset also has similar person with different poses in its dataset and we wanted to see the performance of the model. When looking at the results, the performance of the model was not very great with the same person in different poses. One possible reason could be the usage of similar colors and the loss function not being able to capture the actual difference between the source and target image. Another possible issue with the approach that we could see is that with dresses that are slightly complicated, for example in the third example, the transfer results were a little poor compared to those with simple garments such as the 2nd and 4th example.
Gender Swap Pose

Example 1

Example 3

Example 5

Example 2

Example 4

Example 6
We wanted to compare the performance of the model when the gender is different and transfer the pose. The model performed decently on majority of the results but one thing to note is that the model was not very good with retaining the patterns in the target image. If we see the second image, we can see how the “&” got shifted and similar performance can be seen for the fourth image where the man is wearing a coat with a shirt but the final result did transfer the pose accurately but the dress got a little distorted.
Analyzing Racial Bias

Example 1

Example 3

Example 2

Example 4
The model seems to do well and does not exhibit any kind of racial bias. The images above gives a brief overview of results of try on with different ethnicity and as you can see the results reflect a correct pose transfer. The model finds it hard to capture the patterns but overall the results seem good.
Pipeline Results and Comparisons.
In our implementation, we tried to combine the two pipelines i.e. virtual try-on and pose transfer. Considering our use case of online shopping, we felt the need to have an integrated pipeline, that would not only give the results for try-on but also let the customer witness how the outfit might look in various poses. Therefore, we connected the two components of each paper to create an entire pipeline of pose transfer and virtual garment try on.
1. Pose with Style: Detail-Preserving Pose-Guided Image Synthesis with Conditional StyleGAN
In the "Pose With Style" paper, the authors propose a method for human reposing using a pose-conditioned StyleGAN2 generator.
Method
- They first extract the DensePose representation of the target pose and use a pose encoder to encode it into pose features.
- These pose features are then fed into the StyleGAN2 generator to generate the new image.
- To preserve the appearance of the source image, they encode it into multiscale warped appearance features using the source feature generator.
- To warp the features from the source pose to the target pose, they use the target coordinates obtained from the target dense pose and the completed coordinates in the UV-space inpainted using the coordinate completion model.
- The warped appearance features are then modulated in a spatially varying manner using the affine parameters network to generate scaling and shifting parameters.
- The training losses include adversarial loss, reconstruction losses, and a face identity loss.
This is the formula for the loss used in this pipeline.
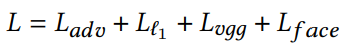
The total loss is a combination of four losses:
- $L_{adv}$ : StyleGAN2 adversarial loss
- $L_{l1}$ : L1 loss loss between the foreground human regions of the synthesized image and of the ground truth target
- $L_{vgg}$ : Minimizing the weighted sum of the L1 loss between the pretrained VGG features of the synthesized foreground and the ground truth foreground
- $L_{face}$ : Face identity loss (from MT-CNN) to detect, crop, and align faces from the generated image and ground truth target
Here, an integrated pipeline was achieved by feeding in the results of the virtual try-on with the target pose image into the pose-transfer network.
Our Results

Example 1

Example 2

Example 3
In the above set of images, starting from the top left the first image corresponds to the original/source image. It is followed by the target clothing that we need to try-on. The next two images in the row are the outputs of the virtual try-on on the original pose, followed by a pose transfer to the back-pose.
As we can observe, the entire pipeline runs quite well when the images are distinctly different. The try on is also successful between articles of clothing with similar colours and styles, as we can see in the third image. However, when trying to synthesize a full length article of clothing (like a pant) from a half length source (like a skirt) as in the second example, the model performs poorly. This performance also affects the pose transfer, where the resulting garment on the back pose is messed up. This shows that the garment try on is not able to map the target image features to the source image accurately.
2. Dressing in Order: Recurrent Person Image Generation for Pose Transfer, Virtual Try-on and Outfit Editing
In the "Dressing In Order" paper (DiOr), the generation pipeline uses a pose-conditioned generator to dress a person in a specified pose, with garments generated and added in order using a recurrent generator.
Method
- The DiOr generation pipeline represents a person as a tuple of pose, body, and garments (pose, body, {garments}).
- The process starts by encoding the target pose and source body.
- The body is then generated, and serves as the starting point for generating garments using a recurrent generator that receives garments in order.
- Each garment is encoded by a texture feature map and soft shape mask.
- Estimated flow fields are used to warp the sources to the target pose.
- At any step, an output can be decoded to show the garments put on so far.
This is the formula for the loss used in this pipeline.
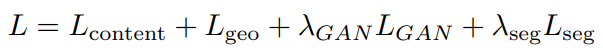
The total loss is a combination of four losses:
- $L_{content}$ : Content loss formed as a combination of L1 loss, perceptual loss, and style loss from GFLA (Global Flow Local Attention)
- $L_{geo}$ : Geometric loss as a combination of correctness and regularization loss from GFLA
- $L_{GAN}$ : GAN loss on two discriminators, one conditioned on pose and the other on segmentation
- $L_{seg}$ : Segmentation loss which is a pixel-level binary cross-entropy loss between the soft shape mask and its associated "ground truth" segmentation for each garment
In summary, the pose of the target person is first captured and applied onto the source body, before transferring the target garment onto the source person. Both tasks are done jointly, with combined learning leveraging features learnt from both tasks.
Our Results

Example 1

Example 3

Example 5

Example 7

Example 2

Example 4

Example 6

Example 8
We observe that the results of DiOr are significantly better than those of Pose With Style. DiOr is able to capture the pose as well as the clothing of the target image fairly accurately. There are some failure cases, such as example 3 where the pose is captured efficiently but the garment is not reflected successfully. In example 7, we can see that the garment transfer is not entirely successful, with the finer details such as the bow in the shirt being distorted. Similarly for this image, the pose transfer is not completely realistic either, with the finer details of the model's hand becoming distorted upon transfer. These errors indicate that the model is unable to learn the more detailed features of the target, but is able to capture the higher level dependencies accurately.
One observation is that facial features are not completely preserved when using this pipeline. Important/high level facial features are preserved across the transformation, but the finer details often get distorted. In contrast, Pose With Style performs better, where we observed that the facial features get represented correctly across the virtual try on or pose transfer task. This might be because Pose with Style uses an additional Face Identity loss that might help capture finer facial features.
Additionally, we observed that the order of tasks in the two repositories are different. Pose With Style performs virtual try on first and then does the pose transfer, while DiOr captures the target pose first and then tries on virtual clothes. We wanted to check if this order influences the quality of results, but we observed that it does not matter as much. The quality of outputs depend on the learning of each individual task and not the order of the combination of these tasks.
References.
- Pose with Style: Detail-Preserving Pose-Guided Image Synthesis with Conditional StyleGAN
- Dressing In Order (DiOr)
- DeepFashion Dataset
- Poly-GAN: Multi-Conditioned GAN for Fashion Synthesis
- XingGAN for Person Image Generation
- GFLA (Global Flow Local Attention)
- Joint Face Detection and Alignment using Multi-task Cascaded Convolutional Networks