
Final Project
For our project, we used a neural net to infer shading characteristics from face images. Using these, we were able to relight the face images using a physics-based formulation.



System Overview
Portrait relighting is a particularly interesting feature beginning to appear on consumer mobile devices such as the Google Pixel phone. The goal of this problem is, using a single RGB image of a face under some unknown, uncontrolled lighting conditions, generate a new realistic image of that face under a user-provided set of lighting conditions. In the case of the Google Pixel, this is defined as a directional light, but for our case, we would like to provide light as an environment map.
Environment maps are spherical high dynamic ranges images which model all incoming light at a single point in space. They are often used in graphics to add photorealism to a scene as a backdrop, without needing to model a bunch of extra geometry. Compared to a directional light, these spheres represent incoming light more generally, and can represent effects like indirect illumination, or atmospheric illumination (things in shadow being shaded blue due to the color of the sky.) Thanks to their popularity and relative ease of capture, websites exist with large selections of free to download high resolution HDRI images. In our project, we hope to take advantage of these datasets to create more interesting facial relightings.
Our method attempts to take advantage of the long history of pixel shaders used to model materials in 3D computer graphics. Specifically, rather than use a neural net conditioned on our desired illumination, our method uses a neural network to infer various shading parameters from the face image. These parameters can then be fed into a shading algorithm to generate a new image of the face with different illumination from the original image. While this approach is fairly generalizable to many different pixel shaders, for our project, we will model the face as a smooth Lambertian surface. To relight this surface, we need to compute the albedo of the surface (effectively removing the existing shading from the source image) and the surface normals at each pixel. We also compute a mask around the face in the image, either to replace the background with that of our new environment, or to limit the effects of our relighting algorithm to only the face.
After reviewing the literature, we were able to find an existing neural portrait relighting implementation which also used environmental illumination as input. In the paper Deep Single-Image Portrait Relighting, an autoencoder network is given a source image and attempts to resolve the source illumination in the latent space so that it can be replaced by the target illumination before decoding. Using an adversarial loss against real face photos, this technique attempts to generate more photorealistic output images. While we will not be using this architecture specifically, we do make use of its dataset, and our technique of rendering images is very similar to the technique used here to generate images for their dataset.
Dataset
Our dataset requirements were very specific, and unfortunately there is not a lot of data available in the wild for faces which includes ground-truth surface normal and shading/albedo. There were some datasets we found but these were not made available publicly, and required permission to use, which isn’t granted to students. For this reason, we had to use the dataset from the previously mentioned paper, which is a synthetic dataset built off of real images. This dataset contains thousands of faces which are re-lit using another network to extract features such as normal and shading.
Because the dataset we used only provided face images which were artificially relit using a different model, we needed to do some processing to extract the source image as well as a mask for the face. We retrived the source image by taking the average of the artificially relit images to get an albedo image and then multiplying the original shading map, which was also provided. The normal map was also provided, both as a map defined over the whole image, and one defined only over the face. We used the latter to construct a pixel mask for the face, using only locations where a normal was defined. As we will mention later, this had some limitations in that the normal map did not completely cover the face, missing areas such as the teeth and upper forehead.
Shading Methods
Because the neural network training is independent of our shading algorithms, we implemented some of our shading pipeline before finishing our neural network architecture, and tested the shading on synthetic input data, including some faces from our dataset. This is what was shown for our final project presentation in class, and here, we'll discuss a bit more about this part of the relighting pipeline.
For simplicity, we represent the skin as a Lambertian surface, which means that the illumination of a pixel is only dependent on the albedo, and the angle of incoming light with respect to the surface normal. This isn't a perfectly realistic representation of human skin, which can have some specular effects when wet, and also exhibits some subsurface scatterring, but for our cases it is good enough, even if it produce somewhat "plastic" looking results.
Because we are using environment spheres to represent all incoming lighting, we need to consider light coming in from all directions at each point. This can be represented as an integral over the hemisphere surrounding a given normal with the appropriate Lambertian weights. Because this step is fairly expensive to compute however, we preprocess our environment spheres to precompute the incoming diffuse illumination from all directions. This allows us to shade a given pixel simply by multiplying its albedo with the incoming illumination which we use the normal to look up on the diffuse environment sphere.
Network Architecture
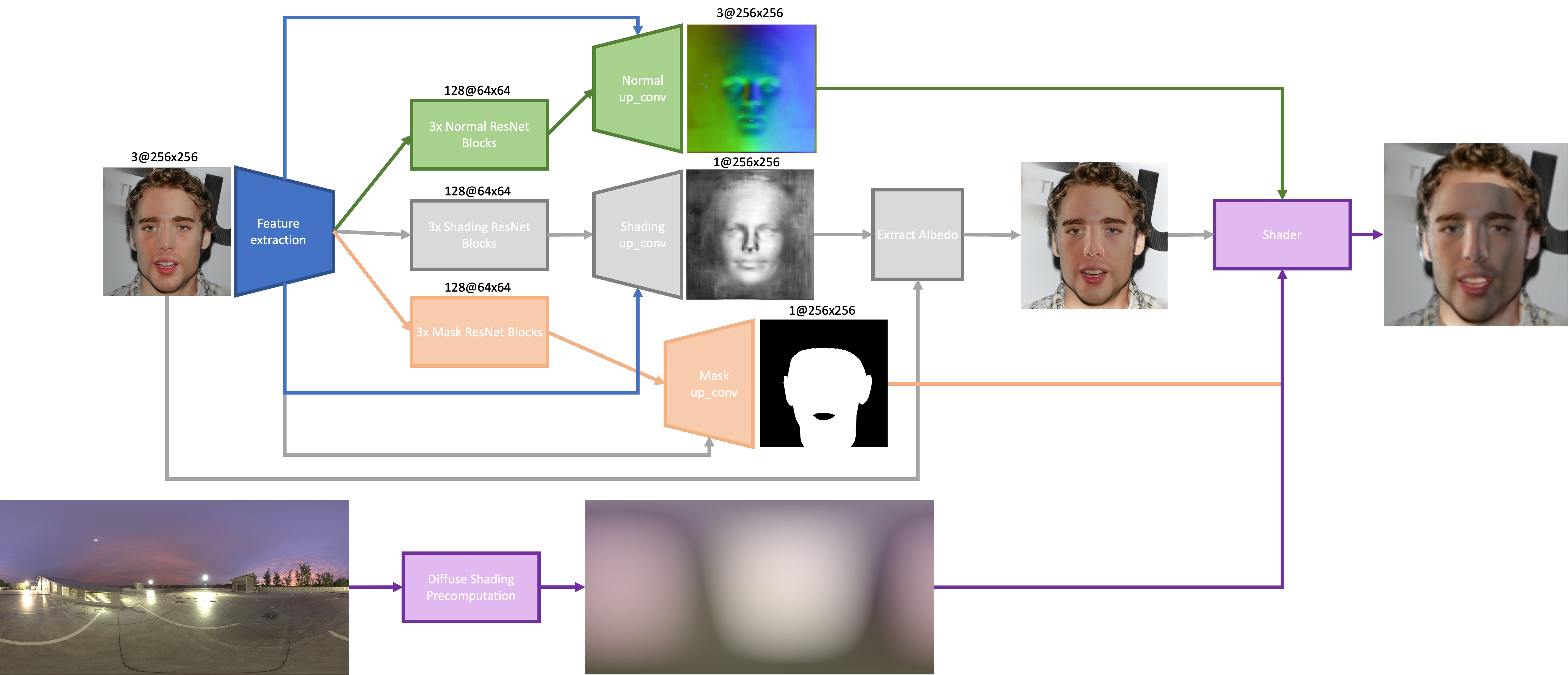
The general network consists of a feature extraction and down sampling piece, whose resulting encoding is then fed into 3 separate parts to extract the normals, shading, and mask. Each of these components is the same, with the only difference being the final number of channels for the mask and shading is only 1, whereas the output for the surface normals is 3.
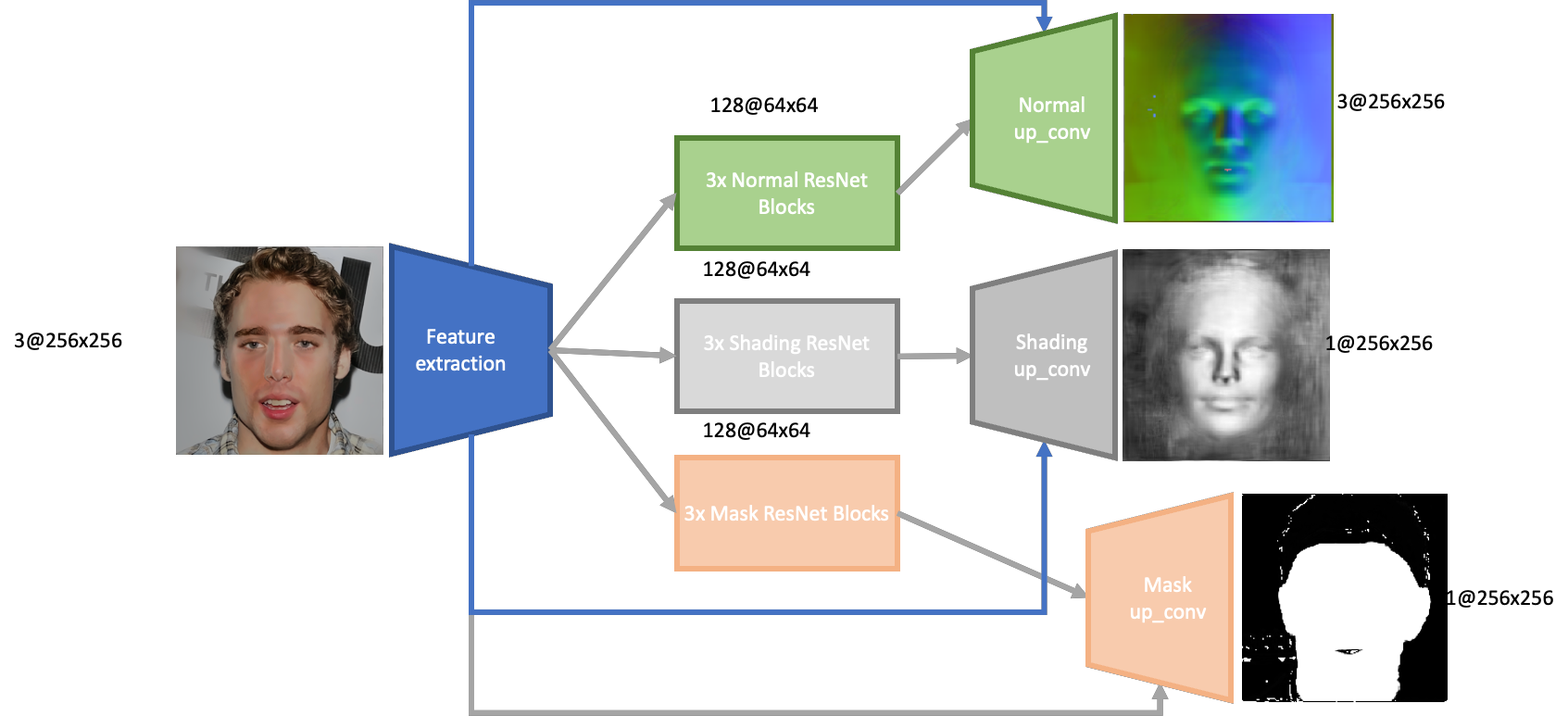
The feature extraction portion consists of two 2D convolutions which maintain the input size, followed by 2 down-sampling convolutions to quarter the input size. Each convolution is followed by a batch normalization and a ReLU layer. The final layer consists of 128 features.
The normal/shading/mask extraction portions of the network contain 3 residual network blocks. The output from these is then up-sampled, and then run through five 2D convolutions, which reduce the 128 features to the appropriate number of output channels. Two of these convolutions also take input from the results of the 2 non-down-sampling convolutions from the feature extractor. In this manner we’re able to retain intermediate information from the feature extraction which is useful when recovering the normals and shading.
The architecture of our network was heavily influenced by SfSNet, which performs similar tasks of extracting surface normal as well as albedo. However, we wanted to produce a lighter weight network which we were capable of training. Additionally, we extract shading and mask as well, and thus our network compensates for this. Although this lighter-weight network may lead to marginally poorer results, when combined with our final rendering technique, the errors are impossible to notice.
Previous Attempts
In our efforts to make a lighter architecture we went through a variety of iterations. Early attempts kept the maximum number of features at 64. We soon realized that this was too little, especially when trying to increase the granularity of our output. We originally increased this to 256, however we were then unable to run our model on higher resolution images, as training took far too long, and we’d often run out of memory. We were able to settle on 128 as an appropriate balance.
Regardless, outputs continued to be quite blurry and low-resolution. To resolve this, we included the skip layers, which maintain the output from the intermediate feature extraction steps and include them in the input to the reconstruction convolutions. These serve to make sure that information which is extracted early on is not lost in subsequent layers in the network, and borrows ideas from ResNet. We also went through a variety of other iterations which include less interesting changes such as kernel sizes, and number of convolutional layers. We found that in general if we dipped below 4 convolutions on the feature extraction, we would end up with normal results as shown below.

Results
Below are some results generated by our shading parameter inferencing model. We note that the surface normals are reproduced fairly accurately, which makse sense considering they are fairly consistent with respect to facial geometry across the dataset we trained from. The shading results are a bit less consistent and have some splotchy artifacts, particularly on images not from the training set. We think this is mostly due to the fact that shading is somewhat ambiguous to estimate, particularly that multiple illumination patterns can give similar results. Our mask results are fairly good (no artifacts along the edges) although they fail to cover the inside of the mouth or the top of the forehead. This is a limitation from the masks provided in our training set, since these failed to cover the whole face.
Also note that the normal reconstruction isn't as good on the last face image shown here. We believe this is because the face is not pointed at the camera head-on while most of our training set contains head-on images.
| Source Image | Normal Map | Shading | Albedo | Mask |
|---|---|---|---|---|
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
After applying our diffuse shading algorithm to the results derived above, we get the following reilluminated face images. Overall we think that these results look fairly realistic (within the masked region) and do a good job at conveying the geometry of the face. The three scenes selected show lighting cases with one bright source, fairly even lighting, and two light sources on opposite sides. Most artifacts in these results seem to be due to bad shading esimates from the neural network, which causes our albedo estimate to have splotches.
 |
 |
 |
|
|---|---|---|---|
|
 |
 |
 |
|
 |
 |
 |
|
 |
 |
 |
One final benefit to our approach compared to the Deep Portrait Relighting paper is that we can run arbitrary shading algorithms on the results we infer from the source image. For example, while the above results used a diffuse shading model, we can also use a reflective shading model as shown below to give the face a metallic surface. While the results are not a realistic face image, they could be useful for special effects reminiscent of the T-1000.

Challenges / Goofs
While implemeting this project, we did hit a few snares that made it more difficult. One of which was finding a good dataset. As described above, many datasets either didn't include the data we were looking for, or were hidden behind some form of authorization wall. While we did eventually find most of what we wanted from the DPR dataset, we did need to implement some code to extract the data we wanted to train on from this dataset (in particular the original shaded images, and facial mask images).
In our original formulation as described in the proposal, we had hoped to use a neural network to compute the normal map and albedo image used for shading. In practice, this turned out to be not very effective in terms of the albedo image. Even after many iterations of training, sharp details from the source image would tend to get lost in the model's output albedo image. Taking a hint from the preparation steps for the DPR dataset, we switched our model to estimate the (smooth) shading of the source image, then divide that out to get the albedo. This approach worked much better, and tended to give us sharper results.
While training our network, we spent some time wondering why our results for the normal maps were not closely representing the provided data. In at least one case, this was caused by normalization not being applied to all training images in our dataloader. Beyond that bug though, our network would fairly quickly learn vertical geometry of the face (which normals pointed up and down), but not horizontal. Later, we noticed that the data augmentation techniques we had been applying contained a random horizontal flip. While typically fine, in the case of the normal map, flipping the image does not change the orientation of the normals, thus half of our training data was oriented the wrong way, causing the model to fail to learn the left side of the face from the right.