
Project 3
For this project, I implemented two different types of GANs. The first, the deep convolutional GAN generates images of grumpy cats based on a random input vector. The second is a Cycle GAN, which is able to convert images of one class into another. The examples shown here are two different tyeps of cats, and two different types of fruits. The Cycle GAN can either use a patch discriminator to optimize the transformation, or the cycle-consistency loss to encourage the transformation to be invertible.
Deep Convolutional GAN
In this section, I implemented a convolutional GAN to generate grumpy cat images. This comprised of creating a discriminator network, a generator network, a training algorith, and to improve the quality of my results, augmentation of the input data.
Creating the discriminator and generator layers was fairly intuitive by using the architecture provided in the assignment writeup. One thing of note though, is that because we do upsampling and downsampling in the convolutional layers of these networks, it is important to apply the proper amount of padding to the images so that each layer has the desired output size. I adapted the following formula from the Conv2D doc page (with the assumption that dilation is 1)
W' = floor([(W + 2P - K) / S] + 1)
to determine the size of the output image (W') given the size of the input image (W), the padding size (P) and the convolution stride (S). In the case of our first layer in the discriminator, we have W = 64, W' = 32, K = 4, and S = 2. This means that our padding must be P = 1.
To train this network, we first select some sample images from our dataset, and generate some fake ones with our generator. We then use these sets to train the discriminator. After that, we then generate more fake images, and use the discriminator to train the generator. Below are some sample images of the output of this algorithm given different augmentation procedures. The first row contains samples from iteration 200, and the second row contains samples from iteration 6400.
| Basic Non-differentiable | Basic Differentiable | Deluxe Non-differentiable | Deluxe Differentiable |
|---|---|---|---|
 |
 |
 |
 |
 |
 |
 |
 |
We can see that both the deluxe and differentiable augmentations can significantly improve the output quality. Similarly, we can see that the basic (essentially none) augmentation does tend to overfit, as can be seen in the lack of diversity in the output images.
One major change that can be seen with increased training iterations is the presence of higher frequency features in the output images. While the early iterations tend to produce blurry images of cats, later iterations produce images with sharp features such as whiskers and fur texture. Another thing to note is that of the four configurations, the basic non-differentially-augmented case has the sharpest images early on. This lines up with the theory that this configuration is overfitting the data, as it appears to converge much faster than the other cases.
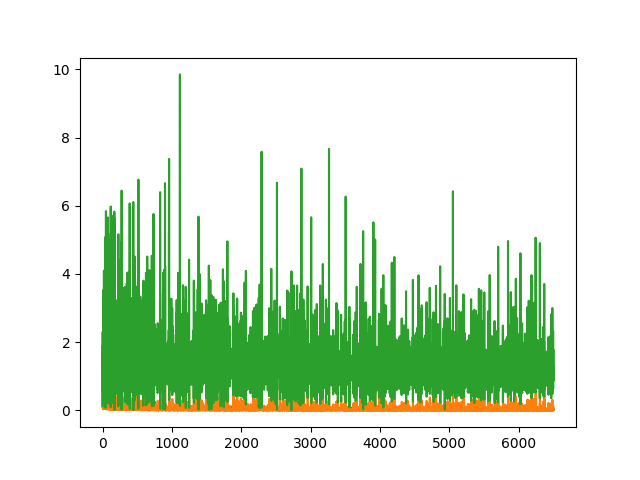
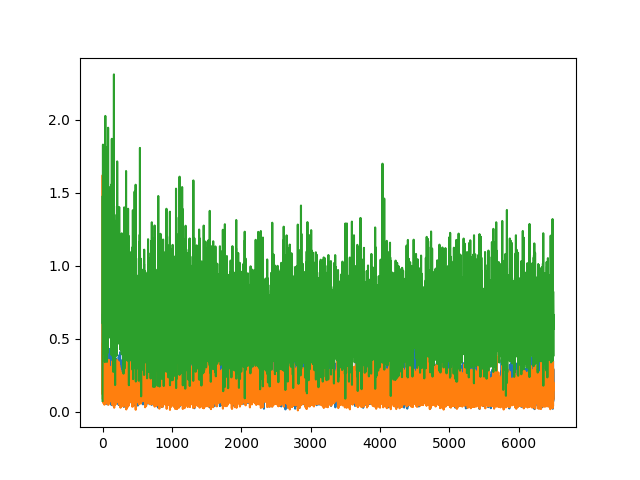
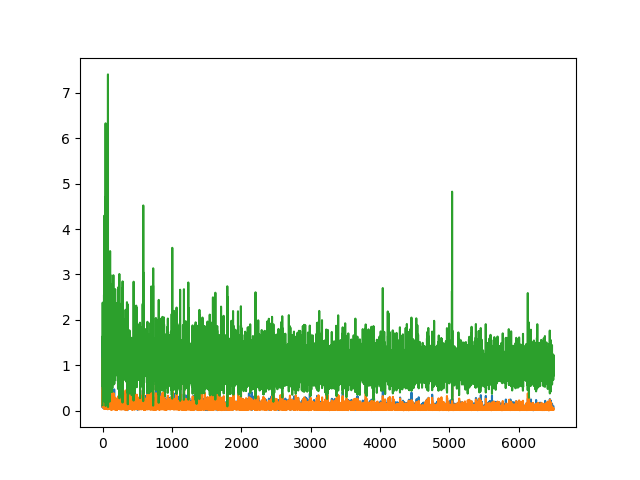
Below are some images of the discriminator (blue and orange for real and fake) and generator losses (green) given different augmentation procedures.
| Basic Non-differentiable | Basic Differentiable | Deluxe Non-differentiable | Deluxe Differentiable |
|---|---|---|---|
 |
 |
 |
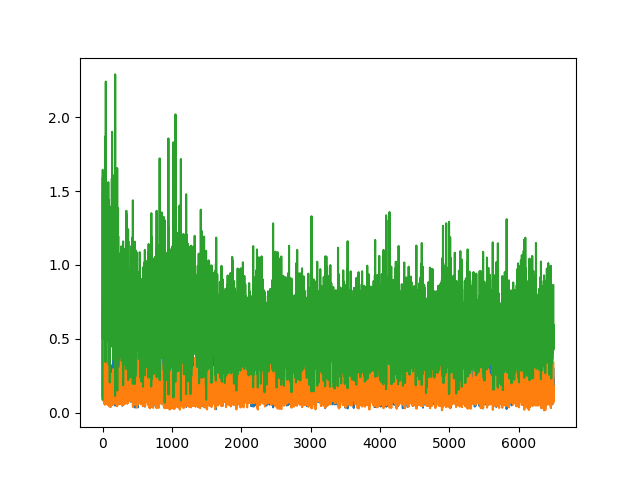 |
We can see that both ideal generator and discriminator losses are low, however given that the network is adversarial, neither loss gets the chance to converge very close to zero. In general the best results came when both the generator and discriminator losses were similar, compared to cases where the discriminator loss was significantly lower than that of the generator. In this (basic non-differentially-augmented) case, the discriminator was better at identifying fake images than the generator was at creating them, therefore the output image quality was poor.
In general it does appear that adding more augmentations (deluxe and differentiable) tends to bring down the generator loss, and consequently produce better output images.
CycleGAN
In this section, I implemented CycleGAN to convert images from one class to another. This was accomplished by using a discriminator for each class. Specifically, these discriminators were patch discriminators, which return real/fake assessments for segments of the input image. A GAN with this architecture alone is capable of performing cross-class transformations, however I also implemented a cycle-consistency loss term which helps to ensure our transformation from class X to class Y is the inverse of the transformation from class Y to class X.
Below are some samples of the output of this CycleGAN implementation on the provided datasets after 1000 iterations.
| X to Y (no cycle-consistency) | Y to X (no cycle-consistency) | X to Y (with cycle-consistency) | Y to X (with cycle-consistency) |
|---|---|---|---|
 |
 |
 |
 |
 |
 |
 |
 |
Below the same outputs after 10k iterations.
| X to Y (no cycle-consistency) | Y to X (no cycle-consistency) | X to Y (with cycle-consistency) | Y to X (with cycle-consistency) |
|---|---|---|---|
 |
 |
 |
 |
 |
 |
 |
 |
In general both the losses with and without cycle-consistency appear to create plausible output images. I did tend to note that the non-cycle-consistency loss image outputs did tend to vary more with each training iteration, which makes some sense considering that we are not enforcing cycle-consistency on our functions between X and Y, which means that larger perturbations in the function output are less discouraged. On the other hand, I did note that in some cases, the results generated by cycle-consistency did tend to appear less physically plausible in some cases. In particular, some transformations between the grey and grumpy cats didn't look quite right because cycle-consistency loss tries harder to preserve the face shape of the original image, even if it doesn't match the target domain. I assume with more training this effect would be weakened though.
| X to Y (patch loss) | Y to X (patch loss) | X to Y (DC discriminator) | Y to X (DC discriminator) |
|---|---|---|---|
|
|
 |
 |
|
|
 |
 |
I couldn't notice a very strong difference between the patch and DC discriminators in my generated output. In theory, I would expect that the patch discriminator would more strongly favor preserving the image layout (since it contains more spatial information) whereas the DC discriminator would allow more changes to the shapes of objects. In practice though, I didn't see much of a difference here, both discriminators tend to preserve the shape of the source object even if it doesn't fit (in the apples to oranges example). My theory is that the cycle-consistency loss term is also discouraging changes to image geometry.
Bells and Whistles
Becoming James Bond
You may or may not be familiar with the story of how one minor wardrobe change nearly cost the 2016 James Bond movie Skyfall millions of dollars. You can find more details here, but long story short, Daniel Craig decided to wear a pair of gloves with his costume on set. This ended up creating a plot hole in the movie, since gun he uses in the scene is fingerprint-activated. The scene was fairly elaborate, and it would have cost millions to bring the actors and animals back on set to re-shoot. The studio had no choice but to painstakingly digitally paint over the gloves on James Bond's hands.
After seeing how CycleGAN tended to preseve the shape of the objects it translated while changing texture, I figured it would be a good tool to try and automatically remove the gloves from my hands, saving countless overworked VFX artists hours of thankless work. To do this, I created a dataset of two minute-long videos of my hand in various poses with and without the glove. (Thanks to mirroring augmentation I only needed to film my right hand!) After seeing promising results with 64x64 images, I added additional upsampling and downsampling layers to the CycleGAN model (along with more channels) so I could train on sharper 128x128 images, where more interesting texture was visible.
After training over every 15th frame of the video for 20,000 epochs, I ran the source video through the model I had trained and got the following result!
Thanks to CycleGAN creating an invertible transformation, I can also do the reverse and add a glove onto my hand, effortlessly undoing all the hard work of the Skyfall VFX team.
Overall, I was pretty impressed with the glove removal results from CycleGAN. For a network where I was able to provide unpaired examples of the two classes I wanted to transform between, it does a decent job at creating a convincing output image. That said, there are some artifacts in the hand video. Namely, my hand has barely any texture. I looks like the network didn't learn any of the wrinkles in the palm of my hand, and instead just smoothed out and recolored the leather texture from the glove. In some cases it even looks like some of the folds from the glove are transferred onto my hand.
The reverse direction, adding the glove to hand has some more prominent artifacts. In early iterations, the network had a hard time telling how long to make the glove go down my arm, and at first, it looked like the network simply learned to recolor my hand. With time some more realistic texture and shine from the leather started to be generated, though the model had a bad habit of either erasing my fingers or merging them into a single blob. I'm told creating realistic hands is still an area of difficulty for generative models though, so I won't fret too much.
| Hand to Glove | Glove to Hand |
|---|---|
 |
 |
 |
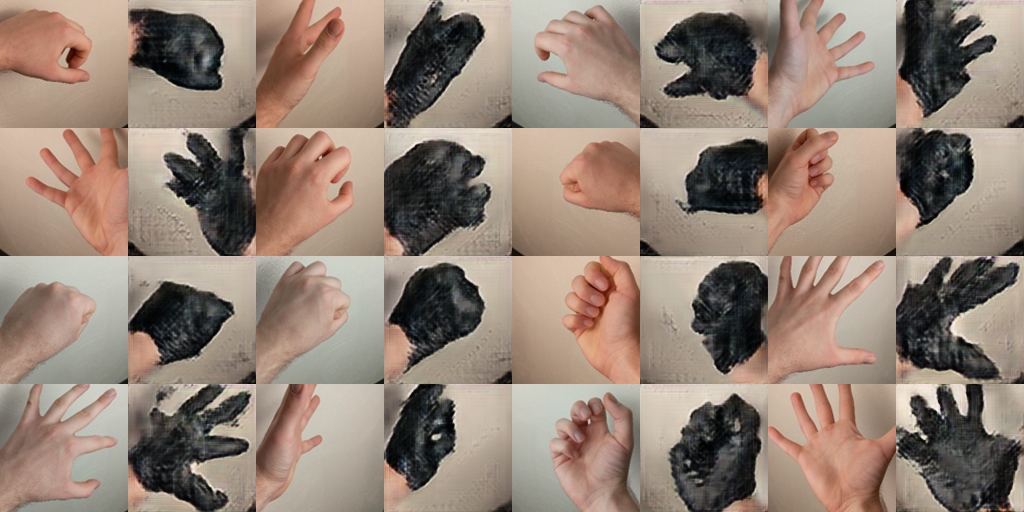 |
 |
 |
Above are the intermediate results of the model during training at 500 iterations, 10k iterations, and 20k iterations. The Glove to Hand model started getting some weird noise artifacts around iteration 17k which I can't really explain. The Hand to Glove model though looks like it could benefit from even more training.
Some Neat Animations
Below are some animations of the results of both GANs over time. You can see how they improve with more iterations.
| Basic Non-differentiable | Basic Differentiable | Deluxe Non-differentiable | Deluxe Differentiable |
|---|---|---|---|
 |
 |
 |
 |
| X to Y (no cycle-consistency) | X to Y (with cycle-consistency) |
|---|---|
 |
 |
| Y to X (no cycle-consistency) | Y to X (with cycle-consistency) |
|---|---|
 |
 |