Final Project - Generative Models for Illumination Recovery in Low Light
apraveen, lrickett, shrutina
Project Description
Images taken in low light or near darkness suffer from limited visibility, loss of detail, and noise. Common post-processing methods such as global brightness and exposure scaling often produce unrealistic, oversaturated images as a result and are typically unable to produce a realistic illuminated image from a low light one. In this project, we aim to explore and utilize multiple generative model architectures to recover the contents of these low light images. Recovering these details has multiple applications from making images more aesthetically pleasing to enhancing images for robotics, such as autonomous driving in the dark.
Method 1: Enlighten GAN
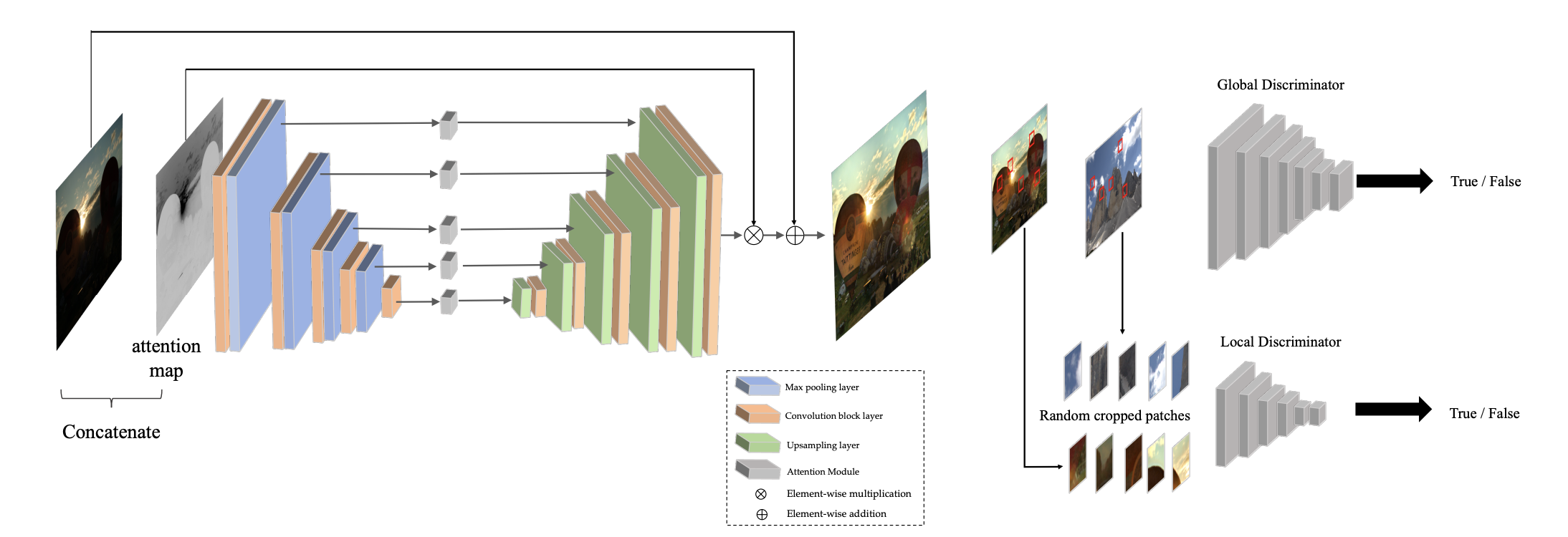
The first approach we explore is EnlightenGAN, generative model that is able to enhance low-light images. This model, shown in the following figure,
uses unpaired images for training, improving upon previous methods that required paired low/high lighting supervision for a given image. The model also uses an inverted grayscale version of the input image as an attention map,
which helps the model focus illumination efforts on the darkest portion of the image. The output of the UNet generator is the illumination component, which is then added to the original
image to get the final result. EnlightenGAN then uses a combination of global and local discriminators that tell whether the image is illuminated or low-light.
We use this model as a baseline for comparison with other methods, as well as try to improve upon the results of this model.
Experiments / Results
1. Baseline Experiment
For a baseline comparison of this model, we downloaded pretrained weights and ran it on various datasets. The results reported in the paper look extremely clear and are reported mostly on outdoor scenes. We see that the model is able to sufficiently recover detail in low lighting conditions, making the images look as though they were taken during the daytime.

However, these high quality results seem to only hold for these outdoor images. When testing on indoor datasets such as LOL (LOw-Light Dataset) or People's Illuminations, we see certain artifacts. Namely, there exist lots of noise in the final result and in some cases the hue over the image is green.


2. Experimenting with Gaussian Activation Function
In an attempt to automatically learn noise reduction, we tried implementing a gaussian activation function in place of ReLU in the generator model. Gaussian blur is a common way to denoise an image and get rid of high frequency information. Because of this, we thought a Gaussian activation function parameterized by g(x) = exp(-x**2) would be able to mimic that functionality. However, we found this to not be the case and the model was unable to learn any illumination changes at all, producing the same image as we had given as input. This may be because the Gaussian activation function truncates signal responses that are out of the variance of the distribution to 0. Illumination requires brightening the pixels and using a Gaussian curve for the activation did not allow for bright pixels to be preserved, which also explains why the default ReLU activation was necessary.
3. Automatic Post Processing (hue reduction)
In order to reduce the green hue over the image, we tried automatic white balancing as a post processing step after the generator. This involved taking the image and scaling the pixel values so that the brightest region of the original
image corresponds to the color white. This worked decently well at not only reducing the green hue over the image but also illuminated the image more.




Takeaways
EnlightenGAN works well for illuminating images past baseline, but does so especially well for images that are not too dark, such as outdoor datasets. When we tested on indoor datasets, we see a significant increase in the amount of noise in the final result and a hue over the image. We experienced difficulties in trying to remove these artifacts from the model, and perhaps a more complex model such as a diffusion model would be more capable of handling artifacts such as noise.
Method 2: StyleGAN-NADA
Another approach we explored, was the use of StyleGAN-NADA for illumination recovery. The model uses 2 text prompts and the semantic knowledge of CLIP embeddings to describe a source and target domain for an image, and aims to generate a new image in the style defined by the user. Because it works in a zero-shot manner, it is flexible in generating images from domains the pretrained generators have not seen before. We can take advantage of this to observe the results with some prompt engineering in an attempt to move the low-light image to a domain with better lighting. If it doesn’t work well, we can look into manipulating the CLIP embeddings to be more familiar with the requested transition and give better results.
Experiments / Results
1. Prompt Engineering with StyleGAN-NADA






We can see by these results that there are some attempts to increase lighting but it does not come out well because this model is interested in zero shot learning in terms of a domain shift. It looks closely at a word (e.g: "Simpson") and would use its pretrained frozen generator to start with the original images (e.g: faces) that eventually turn to look like Simpsons. It is interesting to note that photo -> relighting did highlight areas of the face where brightness would increase if light had increased.
2. Fine-tuning CLIP Embeddings
Because CLIP loss plays a role in the domain shift of this model, we thought that finetuning CLIP embeddings would influence the model accordingly. This was done by loading a pretrained CLIP Model from OpenAI (ViT-B/32) and fine tuning it on the People Illuminations dataset. This finetuning was done over 3 epochs. A small number was chosen due to size of the dataset and because it was noted that it was easy for the model to overfit to the new data rather than generalize. Dataset was built by creating a caption of "flash" for every "flash" photo and "ambient" for every "ambient photo". The results are shown below:

Judging by the results, we can see a bit of the overfit present. Although we cannot expect great results from a model that is influenced by text, this finetuned model did a decent job at trying to replace flash features with ambient features. We can see this with the increased sharpness of the images and slight increase in brightness. With more finetuning and a larger dataset, this could potentially improve.
Method 3: Control Net
Control-Net is a very recent paper that proposes a way to condition text-to-image generation on extra features in addition to just input text prompts. This allows us to exert greater control over the kind of output image that gets generated. For instance, if you want to generate an image of a “stormtrooper giving a lecture at university”, but want it follow the pose in the picture below (left), you can supply the depth-map (middle, the “extra feature”) in addition to the text prompt, to get the desired generation (right).



Since this extra feature could be anything (edge map, pose coordinates, segmentation maps, etc.), we fine-tuned the Control-Net model with an image in low illumination as the control feature, to recover the contents of the low light image, as well as experiment with prompts to see what the image might look like in daylight. For the People's Illumination dataset, here's an sample datapoint where you can see the "flash" (low light) image on the left, and the "ambient" (illumination recovered) image on the right.


The control-net architecture extends the stable diffusion model with an external network which begins as an exact copy of the initial few layers of the stable diffusion 1.5 model, as those weights contain valuable semantic information. During training, only the external network's weights are tuned - meaning the gradients don't flow through the trained stable diffusion model. At the end of training, we are now to influence the generated image with the conditioning feature - which in our case is the dark image (ie, image taken with flash)

Experiments / Results
We attempted to training control-net on two datasets from the Flash and Ambient Illuminations Dataset, namely the People's Illumination dataset, and the Plant's Illumination dataset. Here are a few results after training for ~30,000 iterations on each dataset.
Note: We used the prompt "picture in ambient light" for all image generations.









Takeaways
The main takeaways using control-net for illumination recovery would be: