Index:
Final Project - Deep Virtural Try-On
Overview/Introduction/Motivation
With the unprecedented trend of online shopping, people are purchasing most of their needs online, including necessities for life, entertainment facilities, and most importantly, fashion items like clothes. With numerous kinds of styling clothes, it is convenient if customers can visualize the try-on effect of the clothes on their bodies. Therefore there is an urgent demand for the idea of virtual try-on. Not only virtual try-on save the customers’ time spent in the traditional fitting room, but it also enables customers to try any clothes they like without any physical constraints.
In this project, we explore different state-of-the-art virtual try-on models using GAN and apply them to our customized dataset to synthesize new images. We also identify their shortcomings and try to solve these issues.
We did research on models both with parsers and without parsers. The models with parsers are: VITON, CP-VTON, VTNFP, ClothFlow, and ACGPN, etc. Those without parsers are: WUTON, PF-AFN, etc.
Parsers in a Try-On GAN are used to do several tasks, such as human body segmentation and representation. Since the objective is to replace only the cloth on a human model image, we would not wish the other parts of the human body are changed in this process. Therefore, the parser is considered beneficial for correctly regulating the area that has a cloth to be replaced.
https://arxiv.org/pdf/1711.08447.pdf
Compared to the coarse result, the result with a parser performs better on collar shapes. The reason is that the skin area of the model image could be inferred by using the parser. However, this method fails when receiving some tricky input. If the image of the reference person has more complicated postures and the separation of top and bottom is not as regular as general, then the result of the model with a parser gets more artifacts. To solve this problem, we then utilized the parser-free model.
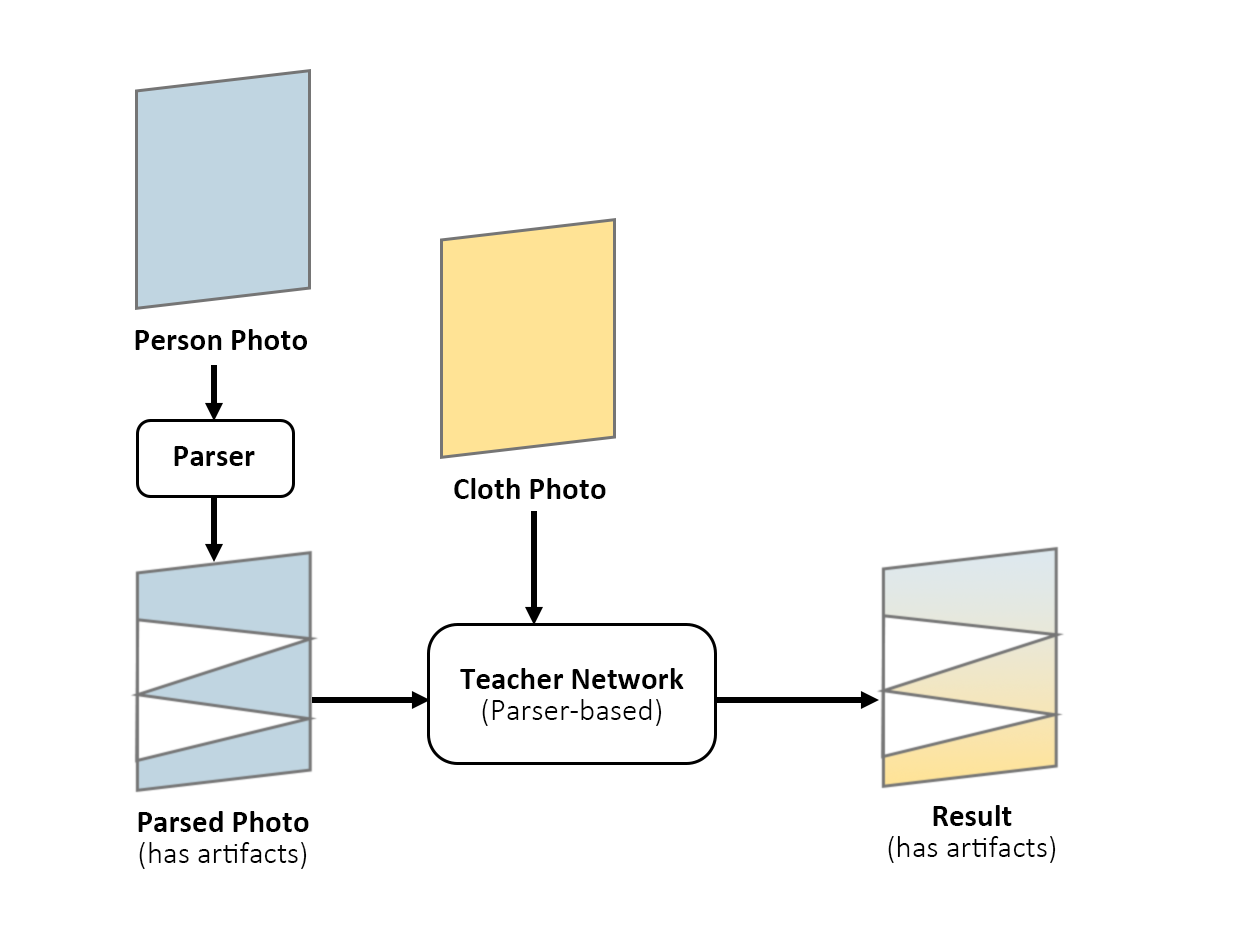
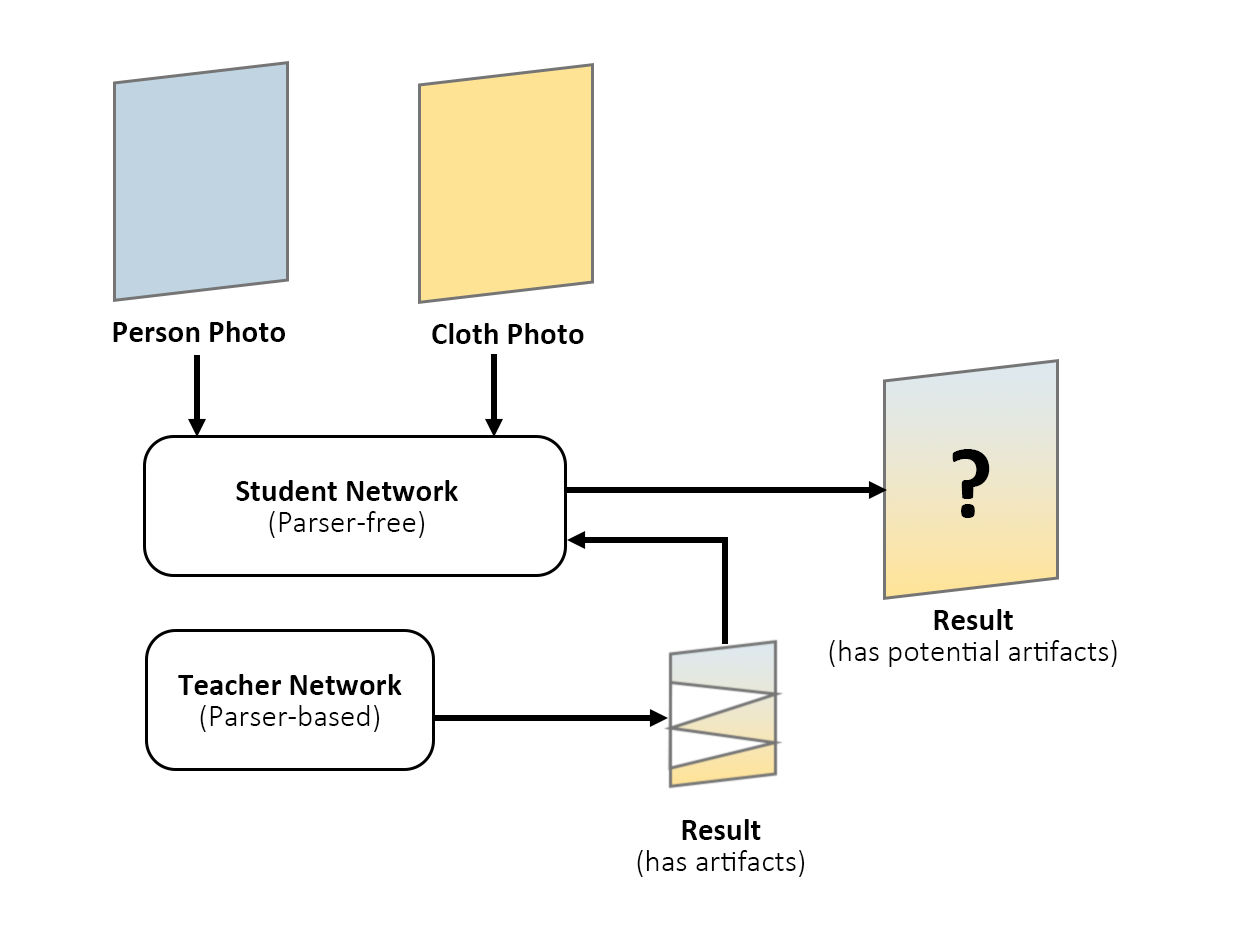
There are several different parser-free models, and the one we used is PF-AFN, an improved work based on WUTON. The basic idea of WUTON is firstly to train a parser-based network as a “Teacher Network”. Then train a “Student Network” which imitates the “Teacher Network”. The trained “Student Network” does not require any parser to get an output then. However, since the result generated by the “Teacher Network” can have many artifacts, the “Student Network” may learn those parts as well, which is not what we want.
(Training process of the Teacher Network, WUTON)
(Training process of the Student network, WUTON)
Currently we are using this git repo as a baseline.
First we test the performance with some latest samples we collected from fashion websites, including ZARA, H&M and Mango. They are of various shapes and we reshape them into 192x256, as the VITON dataset.
In order to increase the testing efficiency, we wrote a tool to automatically mask the cloth out of the background. In most images with light backgrounds, the tool extracts the cloth quite well.
We used VITON dataset for the training process.
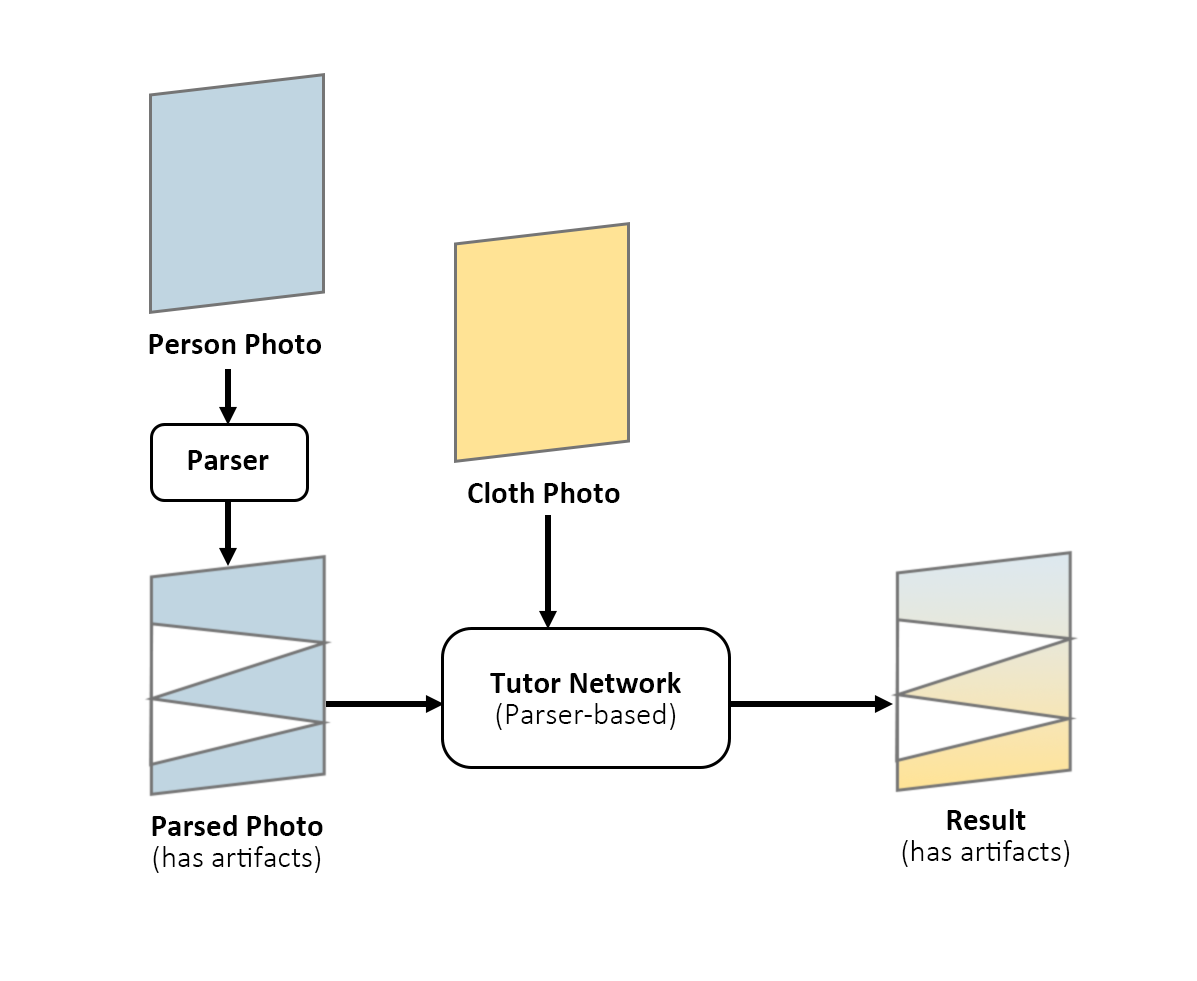
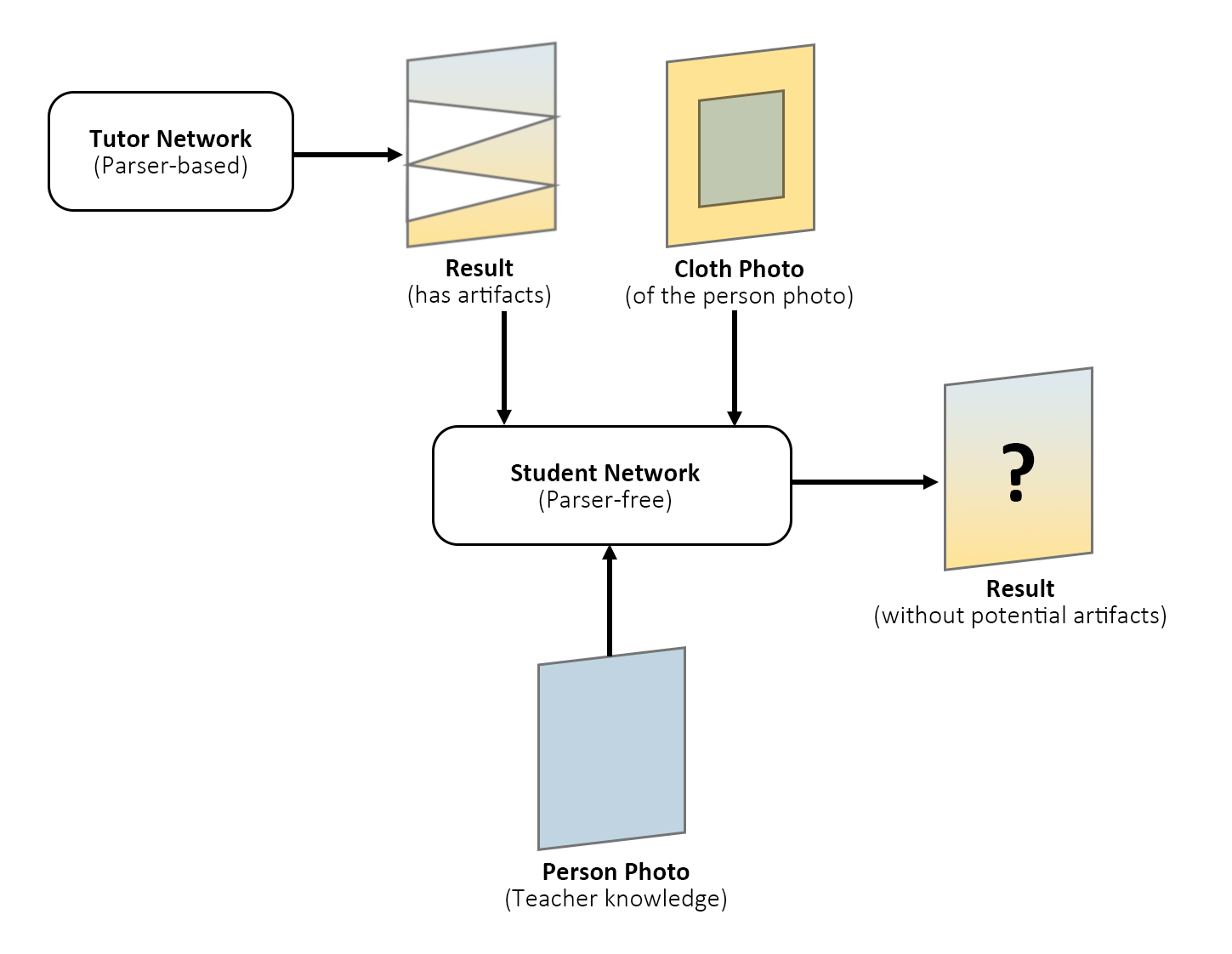
There is a common issue for GANs: generated results always have some artifacts and could not simply be improved for that there is no label as its reference. Thus, PF-AFN smartly solved this problem by changing the structure of the networks. Instead of letting the “Student Network” imitate the parser-based one, PF-AFN used an inverted logic, that uses the fake image generated by the (Parser-based) Tutor Network and the clothes on the real image as the input. Therefore the “Teacher Knowledge” is surely correct because it is the real image. This inversion ensures that the “Student Network” has reliable knowledge to improve itself.
(Training process of the Tutor Network, PF-AFN)
(Training process of the Student Network, PF-AFN)
With the PF-AFN model, we identify a few challenges when synthesizing new images:
Firstly, the model fails to generate nice try-on affect when the input image has a non-white background.More specifically, we find that the background and position of human may significantly affect the result. For example, the below figures show that when the background of the input image is yellow, the model fails to synthesize the try-on image. However, when we zoom in the input image and change the background to be white, the model works well.
In order to resolve this problem, we proposed an idea to separate the background and the model. We feed the model without background into the network to get the result and apply the original background to the result.
Furthermore, the model tends to perform well with t-shirt or other simple top items while fails to process other cloth items like long dresses. We suspect this is because the model’s learned cloth pattern is not diverse enough, and we propose to solve this issue by training the model on a more diverse dataset.
Qualitative result
In order to improve the model’s performance on various kinds of cloth items, we could train the model on a more diverse dataset. For that the current model was trained on top items, it does not perform well on bottom items, and dresses. We want to expand the knowledge to let the model have better universality.