3D-Aware Human Texture Synthesis
1. Introduction
In this project, we aim to design a generative model that is able to generate full textures of full human bodies and renders photorealistic images with given a variety of poses and camera angles.
Recently, as sophisticated and powerful models are proposed to represent and capture the whole human body, the models to predict 3D human mesh directly from RGB pixels are well developed for a single person or even multiple persons.
However, the predicted human meshes are generally "naked" without corresponding textures to recover and render a realistically-looking and articulated human avatar. Some recent works try to generate the texture from RGB image inputs. But they either need high-quality ground-truth textures as supervision, which should be purchased from commercial 3D datasets like AXYZ, renderpeople or twindom and generally costs $20 to $100 each, or are optimization method which is slow in inference, or require predefined garment templates.
Therefore, our motivation and goal in this project are to propose an generative model that directly produces high-quality and realistic textures to render any given 3D human body mesh by using a differentiable renderer. Also, as our model will be free from using the high-quality ground truth textures, we won't be bothered by the expensive costs of purchasing commercial 3D human datasets.
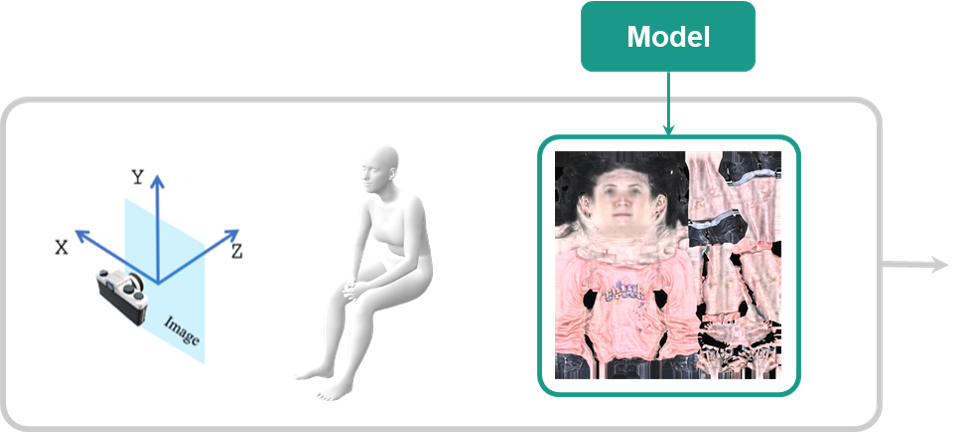

2. Dataset
SURREAL

SURREAL dataset consists of 6 million photorealistic renderings of various synthetic human bodies generated using SMPL body model in diverse shapes, textures, viewpoints and poses. In particular, the texture maps in the dataset will be utilized as ground truth textures to evaluate the generated partial and full textures
AGORA

AGORA dataset consists of 17 thousand photorealistic images, each of which contains 5 to 15 synthetic human bodies with poses and body shapes fitted by SMPL-X model based on over 4 thousand high-quality human scans in diverse poses and natural clothing. In our project, we did background removal and cropped out over 10 thousand full-body images of individuals as real images fed into discriminators to evaluate the full-view rendered images.
3. Model
Model Structure
Our model is basically built upon StyleGAN2, which takes a random latent vector z as the input and generates a full texture as the output. In addition to the direct adversial supervision on the generated textures, we futher use a differentiable renderer to render the generated textures with randomly selected 3D pose and camera to a rendered human image. We also train an additional discriminator to differentiate whether the rendered images are fake or real. Also, during our experiments, we found that the rendered images are still far from photorealistic even with relatively good generated textures, as the whole rendering process is just "painting" the cloth to the human mesh. Thus, we futher train a CycleGAN aiming at tranfering the rendered images to the photorealistic real images.
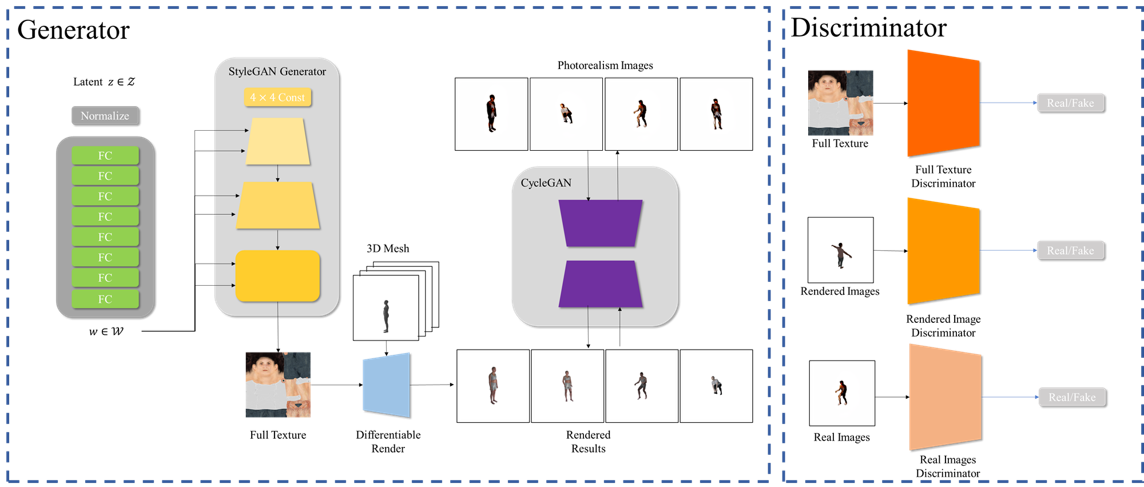
Implementation details
We implemented our techniques on top of the official implementation of StyleGAN2. Our training process is splitted into three stages, In the first stage, we pretrained the StyleGAN2 to generate textures directly. In the second stage, we resumed the model weights and trained it with an additional rendered image discriminator. In the third stage, we train a seperate CycleGAN to transfer the rendered images to the photorealistic real images.
The model is trained with 1 NVIDIA's RTX2080ti GPU with batch size of 8 for 100k iterations for all three stages.
4. Results
Texture Results
Below are the texture output generated from StyleGAN2. These are full textures that can be rendered with any body pose in any camera angle. As can be seen from the qualitative results, in good results, the face, hands and clothing are easily identifiable with great details, whereas the bad results look blurry, noisy and fake in those critical parts.

Rendered Results
To visually evaluate what's going on for our texture, here we have randomly selected 4 poses and rendered 4 gif's with a 360 degree camera. Generally speaking, our texture maps do make sense. The face, cloth, hands, bare feet or shoes are recognizable with certain level of details. However, these avatars still look "naked" because they are not "wearing" clothes but "painting clothes" on their bodies.


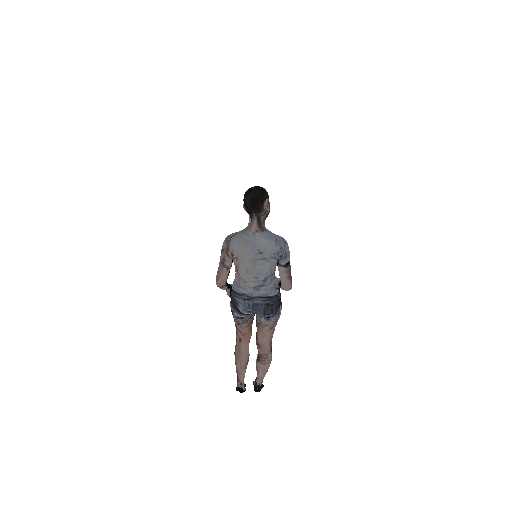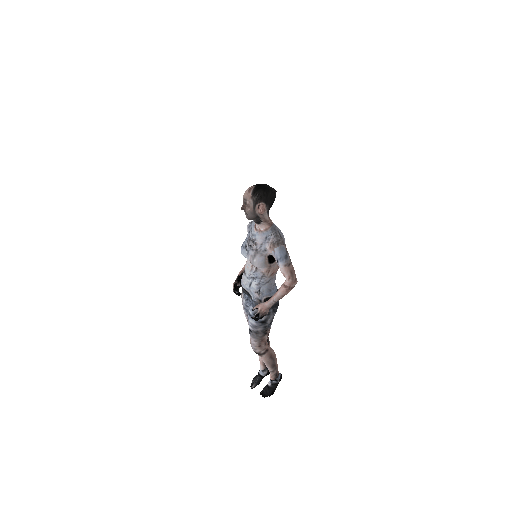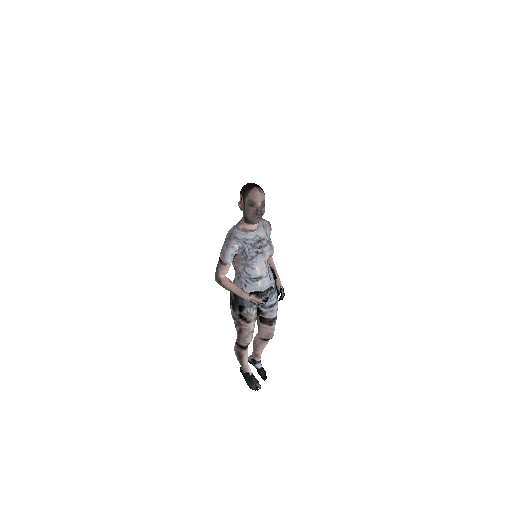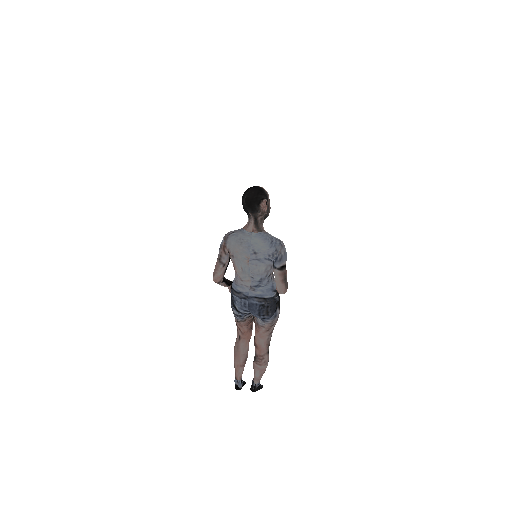
CycleGAN Results
To help them “wear” clothes, we have input our rendered images into a CycleGAN to make them more photo realistic. As you can see, the colors and details of clothing have already started changing.
The inconsistency on the output gif, from our perspective, lies in the fact that CycleGAN processes each frame independently and therefore yields a gif that looks zigzagging. In comparison, the input gif consists of frames that are rendered with the same pose and same texture, thereby looking a lot smoother.


Interpolation
We have also conducted some exploratory analysis like interpolation on texture maps, where we selected several outputs and generated 50 textures in between and rendered gif with a randomly selected pose and a 360 degree camera. Visually speaking, the result is impressive in terms of smoothly changing skin tone and garments.


Poisson Blending
Also, we have run our poisson blending code in HW2 to blend our face into the texture just for fun.




Quantitative Results
Fr'echet inception distance (FID) measures the distance between the generated and real data. Lower FID means higher similarity for the generated and real data distribution. Pretrained VGG-19 network is used to extract image features and features are modeled by multidimensional Gaussian distribution with mean \(\mu_x\) and covariance \(\Sigma_x\). FID is defined by \[FID(x,\hat{x}) = ||\mu_x - \mu_{\hat{x}}||_2^2 + Tr(\Sigma_x +\Sigma_{\hat{x}} -2(\Sigma_x \Sigma_{\hat{x}})^{\frac{1}{2}}) \] where \(x\) is the generated data and \(\hat{x}\) is the real data image.
We calculate the FID for textures, rendered results and transfered results by CycleGAN, which are shown below.
| Texture | Rendered Results | CycleGAN Results | |
| FID | 109.556 | 53.325 | 37.923 |
5. Future Work
Adversial Loss on Face Our experiments demonstrate that the photorealism of the face is one of the most critical factor in rendering a photorealistic photo. Thus, maybe we can add some specific adversial loss on the face to help the model learn a better local face representation.
Temporal Consistent Loss on CycleGAN One possible approach to tackle the issue of temporal inconsistency is to introduce a temporal loss that penalizes the discrepancy between the adjacent frames output by CycleGAN, which will be part of our future work.
Jointly Train the Model Current model training process is divided into three stages and not end-to-end. And we believe that the model will benifit from an end-to-end and joint training of all the modules proposed if possible.
Add Cloth Topology to the Human Mesh Currently the rendered results don't look photorealistic partially also due to the lack of cloth topology on the 3D human mesh we used. The rendering can't represent complex garments like greatcoats or skirts. So adding cloth topology can definitely help improve the photorealism of our rendering results.