When Cats meet GANs
1. Introduction
In this assignment, two powerful and groundbreaking generative adversarial network (GAN) will be implemented.
In part 1, we will implement a variation of Deep Convolutional GAN (DCGAN), which is uses a convolutional neural network as the discriminator, and a network composed of upsampling layer and a convoluation layer as the generator. The DCGAN is trained on both low resolution and high resolution grumpify cat datasets and experimented with differential data augmentation and different data preprocessing policies.
In part 2, the Cycle GAN, which is designed for unsupervised image-to-image translation will be implemented. The DCGAN will be trained both on low resolution and high resolution datasets for catA-to-catB and orange-to-apple. The additional identity loss and SSIM loss are implemented to improve the model's performance.
In part 3, I will introduce a Leo dataset I create consists of my faces, and the Experiments I conduct on this dataset with DCGAN and CycleGAN.
In Appendix, some additional qualitative results are shown.
The spectral normalization is implemented to stabilize the training of both DCGAN and Cycle GAN. The Fréchet Inception Distance (FID) is used as a quantitative metric to evaluate the model's performance.
2. Deep Convolutional GAN (DC GAN)
The DCGAN is a variation of original GAN by introducing convolutional layers. The DCGAN is implemented with using a combination of a upsampling layer and a convoluation layer to replace transposed convolutions in this assignment.
2.1 Data Augmentation (Preprocess)
Data augmentation is required for training GAN as to introduce noises in the input images and
prevent the discriminator from overfitting on a small-sized dataset. In this assignment, the
following preprocess data augmentation
is applied to all datasets if adding --data_preprocess=deluxe to command line in
training.
| Name | Detail |
|---|---|
| Resize | Resize the input image to 1.1 times of its original size with BICUBIC interpolation. |
| Random Crop | Crop the given image centered at a random location to its original size. |
| Random Flip | Horizontally flip the given image randomly with a probability of 0.5. |
The Random ColorJitter is also tried at first but it's found that the ColorJitter seems to prevent the model from converging somehow. And also we have color post augmentation later. So it's not used.
2.2 Differentiable Augmentation (Postprocess)
To further improve the data efficiency of GANs, the differentiable augmentations, proposed in
this paper is implemented
and applied both the real and fake images during training time. The postprocess differentiable
augmentations used in this assignment is listed below, which can be enabled by adding
--use_diffaug='color,translation,cutout' to command line in training.
| Name | Detail |
|---|---|
| ColorJitter | Randomly change the brightness, contrast, saturation of the image . |
| Random Translation | Randomly shifted the image within the range 1/8 its its original size. |
| Random Cutout | Randomly a square in the image and replace it with gray color. |
2.3 Generator, Discriminator and Training Loop
The generator and discriminator is implemented in the model.py. The training Loop is
implemented in vanilla_gan.py.
Specifically, for the discriminator, the padding can be calculated by the formula: \(H_{out} = \lfloor\frac{H_{in}+2*padding-kernal}{stride}+1\rfloor\), where \(H_{in}=2*H_{out}\), \(kernal=4\) and \(stride=2\). Solve the equation by substitution, we got \(padding=1\)
2.4 Spectral Normalization
The Spectral Normalization proposed is borrowed from its official github implementation and is applied to my model for testing. Following the setting from the original paper, the spectral normalization is applied to only convoluational layer for discriminator. (Also for Cycle GAN in part 2)
2.5 Metrics: Fréchet Inception Distance (FID)
The FID is a measure of similarity between
two datasets of images by computing the Fréchet distance between two Gaussians fitted to feature
representations of the Inception network. It's usually used to measure the
image quality of generative models and thus adopted in this assignment to quantitatively
evaluate the performance of model. In the evaluation of DCGAN, the trained model generated the
same number of images of the trained dataset, and the FID is calculated between the trained and
generated images using
a pytorch implementation of FID from
github. The functions to calculate FID is in calculateFID.py
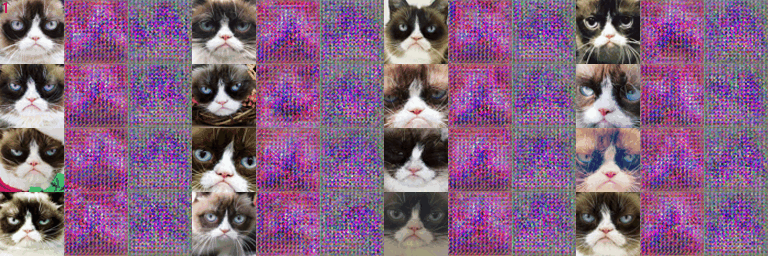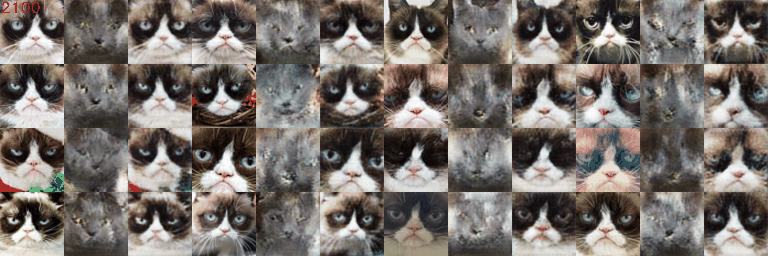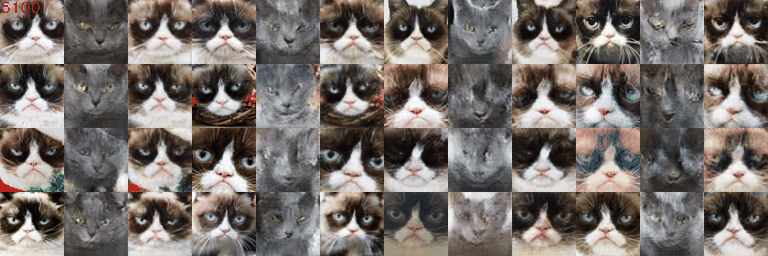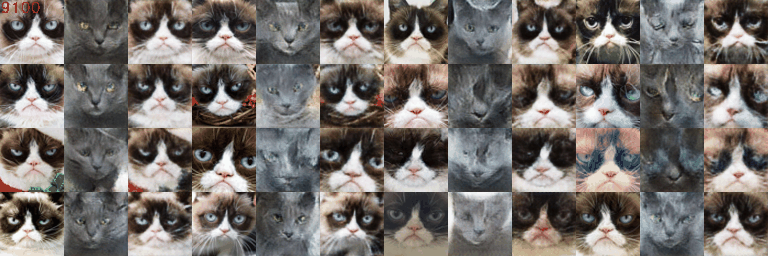
2.6 Experiments (Cats Low Resolution)
The DCGAN is trained for 500 epochs under default given setting on low resolution grumpify cat \(64\times64\). The ablation study is conducted on 1) with basic data augmentation (baseline) or with deluxe data augmentation (pre-DA) for preprocessing; 2) with postprocessing differentiable augmentation (post-DA) or without; 3) with spectral normalization (SN) or without.
Training Loss
The Training loss can be view here.
Qualitative Results
The qualitative of different experiments is shown below.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Quantitative Results
The quantitative of different experiments is shown below.
| Experiments | baseline | baseline + post-DA | baseline + SN |
|---|---|---|---|
| FID | 384 | 55 | 123 |
| Experiments | pre-DA | pre-DA + post-DA | pre-DA + SN |
|---|---|---|---|
| FID | 98 | 72 | 136 |
Discuss
We can see from the loss curve that the discriminator loss drops quickly to a low value without any data augmentation due to overfitting, making the generator loss increase afterwards and the model can't converge. Both quantitative and qualitative results demonstrate the same issue: the baseline mode without any augmentation converges slowly and tends to produce the same results for any input due to the overfitting of the discriminator, and thus lead a very high FID.
By using either deluxe pre-data augmentation or differentiable post data augmentation, we can see that this problem is alleviated: the discriminator loss is significantly higher without quick dropping in the beginning, and the model can produce different but realistic images for different noise inputs. Although, it's noted that using both pre and post data augmentation don't result in the best FID. Experiments show using only post data augmentation produce best results. The reason may be too much data augmentation modify the image space too much and will make generator harder to converge.
Also, it's interesting to find that adding spectral normalization also helps the baseline model to converge even without any data augmentation. I don't find a explanation from the original paper. But my guess is the spectral normalization guarantee the Lipschitz continuity for the discriminator, and thus maybe improve the its generalization ability. We can see from the loss curve that with a spectral normalization, the baseline model's discriminator loss don't have a drastic decrease in the beginning. Also, from the loss curve, we can see the generator loss is smoother, demonstrating ability of enhancing the stability of the training. Though it should also be noted that even the spectral normalization enhance the stability of the training, it don't necessarily lead to a better results.
2.7 Experiments (Cats High Resolution)
The DCGAN is trained for 2000 epochs on high resolution grumpify cat \(256\times256\). To adopt the model on high resolution inputs, I add two more upsampling blocks on DC generator. Also, in each block, I use two convoluation layers and reflective padding after upsampling. To stabilize the training and prevent overfitting, I used spectral normalization, pre-data augmentation and differentiable post data augmentation. No ablation study is conducted dut to the limited computing resources. The
Qualitative Results

Also, I interpolate between different input noises and generate a gif to demonstrate the continuity and smoothness of the learned model.

3. Cycle GAN
In this part, a CycleGAN structure will be implemented to convert images between domain \(X\) and domain \(Y\), by using two generators \(G_{X→Y}\) and \(G_{Y→X}\), and two discriminators, \(D_X\) and \(D_Y\). The cycle consistency losses is also implement to reduce the space of possible mapping functions and force the generators to learn a one-to-one mapping where the output should be closely to the input images x.
3.1 Data Augmentation
The same preprocess data augmentation is used as in part 1 for all experiments. And the postprocess differentiable augmentation will be tested in ablation study.
3.2 Generator
For low resolution images, the generator is implemented exactly as required in
model.py. For high resolution images, the same 6 residual blocks and 9 residual
blocks generator is implemented based
on the original cycle GAN paper.
3.3 Patch Discriminator
For low resolution images, the patch discriminator is implemented exactly as required in
model.py, which has a receptive field of \(46\times 46\). For high resolution
images, the same patch discriminator is implemented based
on the original cycle GAN paper with using
stride=2 in the last two layers, making the discriminator's receptive field to \(94\times 94\)
instead of \(70\times 70\) .
3.4 Training Loop and Cycle Consistency
The training loop and cycle consistency is implemented in cycle_gan.py
3.5 Identity Mapping Loss
In the experiments of orange-to-apple transfer, I found the model sometimes reverse the color (like from black to white) with adding the cycle consistency loss. So the identity mapping loss, proposed by original cycle GAN paper, is implemented to encourage the mapping to preserve color composition between the input and output. Specifically,
\(L_{identity} = E_{x\in X}[||G_{Y->X}(x), X||_{1}+ E_{y\in Y}[||G_{X->Y}(y), y||]]\)
To enable identity mapping loss, adding --use_identity_loss in command line when
training.
3.6 Structural Similarity Index (SSIM) Loss
In this paper, the author claims that the quality of the image generation results improves significantly with using SSIM, which I thought might be helpful for our model. To add the SSIM loss, I follow the empirical setting in that paper and replace the L1 loss we used for cycle consistency loss to a weighted sum of SSIM loss and L1 loss.
To enable SSIM loss, adding --loss_type 'SSIM' in command line when training.
3.7 Experiments: Cats (Low Resolution)
In this experiments, the CycleGAN is trained for 10000 iterations under default given setting for low resolution cat dataset. The ablation study is conducted on 1) with DC discriminator (DC) or with patch discriminator (patch); 2) cycle consistency loss (\(L_{cyc}\)) or without; 3) with identity loss (\(L_{id}\)) or without; 4) with SSIM loss (\(L_{SSIM}\)) or without; 5) with spectral normalization (SN) or without; 6) with postprocessing differentiable augmentation (post-DA) or without;
Training Loss
The Training loss can be view here.
Qualitative Results
The qualitative of different experiments is shown below. I slightly modify the visualization code so that the reconstructed results are also shown every third column in the results. I only show the required results of with or without the cycle-consistency loss and DC discriminator or with patch discriminator here. The other results are put on Appendix so that this part won't be too long.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Quantitative Results
The quantitative results of using different discriminators and cycle-consistency loss are shown below. It's should noted that the FID only cares about the distribution of the feature space for the generated images and real images but don't take the consistency into consideration. And thus a higher FID don't necessarily indicate a better performance of CycleGAN.
| Experiments | DC | DC + \(L_{cyc}\) | patch | patch + \(L_{cyc}\) |
|---|---|---|---|---|
| FID (X) | 122 | 105 | 97 | 115 |
| FID (Y) | 67 | 83 | 68 | 73 |
The quantitative results of other experiment settings are shown below. Here the patch + \(L_{cyc}\) is considered as baseline.
| Experiments | Baseline | + \(L_{id}\) | + \(L_{SSIM}\) | + post-DA | + SN | + all |
|---|---|---|---|---|---|---|
| FID (X) | 115 | 122 | 114 | 87 | 110 | 110 |
| FID (Y) | 73 | 70 | 102 | 59 | 76 | 103 |
Discuss
From qualitative results, we can see adding cycle-consistency loss helps the model to reconstruct the original image by passing the input images to two generators —— which is for sure as it's what the cycle-consistency loss designed for. And the adding cycle-consistency loss helps to preserve more similarities between the generated images and input images. But both our qualitative and quantitative results demonstrate that adding cycle-consistency loss doesn't necessarily improve the generation quality, or say realism. One explanation maybe the adding the cycle-consistency loss impose more constrains and thus may be harder for the generator to converge. So it's a consistency and realism tradeoff here to use the cycle-consistency loss, especially for a small-sized dataset.
By using path discriminator, we can see the model gets better local generation quality, as the patch discriminator is essentially equal to divide images to patches and classify each patches using a DC discriminator individually. Though, the patch discriminator don't make too much difference in this case, which I think the reason is that: if I implement the patch discriminator as the instruction in the assignment handout by removing one layer from DC discriminator, the discriminator will have a receptive field of \(46\times 46\), which is not significantly small for a \(64\times 64\) input image. But in original paper, the author uses the patch discriminator with receptive field of \(70\times 70\) for a \(256\times 256\) input image, which makes more difference.
For other ablation studies, we can find adding identity loss don't help here, as the color composition is already similar between two domains. And replacing the L1 loss to a combination of L1 and SSIM also don't benefit too much, I think maybe because we cares more about pixel-wise more than the structural similarities when two domains are both from real life. The SSIM loss will help more in the style transfer like between photo to painting. The differentiable data augmentation improves the model performance most, as the training dataset of cats is really small. The spectral normalization also don't help improve the FID of the model, which as mentioned before, a more stable training is not necessarily related to a better result.
3.8 Experiments: apple2orange (Low Resolution)
In this experiments, the CycleGAN is trained for 10000 iterations under default given setting for low resolution apple2orange dataset. The same ablation study is conducted;
Training Loss
The Training loss can be view here.
Qualitative Results
The qualitative of experiments on discriminator and cycle-consistency loss are shown below. Also, the results of adding identity loss are shown as it solve the color-inverting problem in the training.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Quantitative Results
The quantitative results of using different discriminators and cycle-consistency loss are shown below.
The other results are put on Appendix so that this part won't be too long.| Experiments | DC | DC + \(L_{cyc}\) | patch | patch + \(L_{cyc}\) |
|---|---|---|---|---|
| FID (X) | 214 | 160 | 119 | 139 |
| FID (Y) | 181 | 191 | 164 | 181 |
The quantitative results of other experiment settings are shown below. Here the patch + \(L_{cyc}\) is considered as baseline.
| Experiments | Baseline | + \(L_{id}\) | + \(L_{SSIM}\) | + post-DA | + SN | + all |
|---|---|---|---|---|---|---|
| FID (X) | 139 | 93 | 133 | 131 | 98 | 84 |
| FID (Y) | 181 | 128 | 165 | 172 | 127 | 133 |
Discuss
Some experiments are similar with that in cats case and thus not discussed here.
One thing to highlight in this experiment, the generator sometimes will inverts the color of the input image especially if we add cycle-consistency loss. And both adding a identity loss or using spectral normalization solve the problem, as they both somehow stabilize the training of the generator, making the generator won't change drastically in the training.
3.9 Experiments: Cats (High Resolution)
In this experiments, the CycleGAN is trained for 10000 iterations with \(\lambda_{cyc}=5\), patch discriminator, cycle-consistency loss and identity loss for high resolution cat dataset \(256\times 256\). No ablation study is conducted as the training of cycle GAN in high resolution image takes too long in my own device.
Qualitative Results
{kind=link}
{kind=link}
Quantitative Results
| Experiments | patch + \(L_{cyc}\) + \(L_{id}\) |
|---|---|
| FID (X) | 107 |
| FID (Y) | 208 |
3.10 Experiments: apple2orange (High Resolution)
In this experiments, the CycleGAN is trained for 10000 iterations with \(\lambda_{cyc}=5\), patch discriminator, cycle-consistency loss and identity loss for high resolution apple2orange dataset \(256\times 256\). No ablation study is conducted as the training of cycle GAN in high resolution image takes too long in my own device.
Qualitative Results
{kind=link}
{kind=link}
Also, I use my trained model to transfer a clip of video consist of oranges from Youtube. The result is shown below. Don't know why but the output video looks wired somehow, which is not the case for image input shown above. I guess maybe the model overfits the dataset to some extent?
{kind=link}
{kind=link}
Quantitative Results
| Experiments | patch + \(L_{cyc}\) + \(L_{id}\) |
|---|---|
| FID (X) | 103 |
| FID (Y) | 144 |
4. Leo Dataset
A fun thing I do in this assignment is to create a Leo dataset consisting of my own faces from my albums, and play the datasets with DCGAN and CycleGAN. The pipeline to generate the dataset is shown below.

4.1 Face Detection and Verification
First thing to do before creating my face dataset is to detect and crop all my faces out from my albums. To do so, I manually select and crop 4 images as source images, and then use the public Face Recognition library to detect and verify whether there is my face in the image. If there is my face in the input image, the algorithm crops the face using the detected bounding box plus some paddings. There will be some false positives created by the algorithm and I manually delete them. Totally, I get 275 images of my faces.
4.2 Face Alignment
Then I use the Face Alignment library to detect the landmark in my face, compare it with the standard landmark and use the calculated affine matrix to conduct affine transformation on the cropped face to get a aligned face.
4.3 Background Removal
As first, I directly use the aligned images for training DCGAN and CycleGAN, but the results are always blurry. So I tried to remove the background from the aligned image by using Portrait Segmentation so that the network don't need to learn additional knowledge to generate the backgrounds. Finally, a sample of images from the Leo dataset are shown below.

4.4 DCGAN Results
The DCGAN is trained on Leo dataset for 5000 epochs with spectral normalization and both pre and pos data augmentation. Also I add a learning rate scheduler to help the model converge, and use patch discriminator to ensure local realism. I trained the model only on low resolution images \(64\times64\) due to the limited computing resources. The model works better than my expectation actually as we are using pretty simple architecture here, but maybe one reason is that we are training on low resolution images here.
Qualitative Results

Also, I interpolate between different input noises and generate a gif to demonstrate the continuity and smoothness of the learned model.

4.5 CycleGAN Results
The Cycle GAN is trained between Leo dataset and Obama Dataset I download from here> with background removal for 30000 iterations with spectral normalization ,cycle-consistency loss, identity loss, patch discriminator and both pre and pos data augmentation. Also I add a learning rate scheduler to help the model converge. I trained the model only on low resolution images \(64\times64\) due to the limited computing resources. The model don't get a satisfying results even for the low resolution images. I guess maybe the differences between two domains are two large, and maybe I can change to a Asian celebrity (with glasses also, as I find the model is hard to learn to add a glass) if I have time.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}