For Style Transfer, besides using my own images as content, I also borrowed my artistic girlfriend's paintings as style images, and was able to achieve desirable results (see experiment 8)
Implementing style transfer from one picture to another, and know the tips of tuning content/style layers.

The major idea is to compare images' latent vector and optimize their correlations to the output image.
In this assignment, we directly use the pretrained VGG19 to encode our images to latent vectors. Therefore, it is just an optimization problem that doesn't involve training.
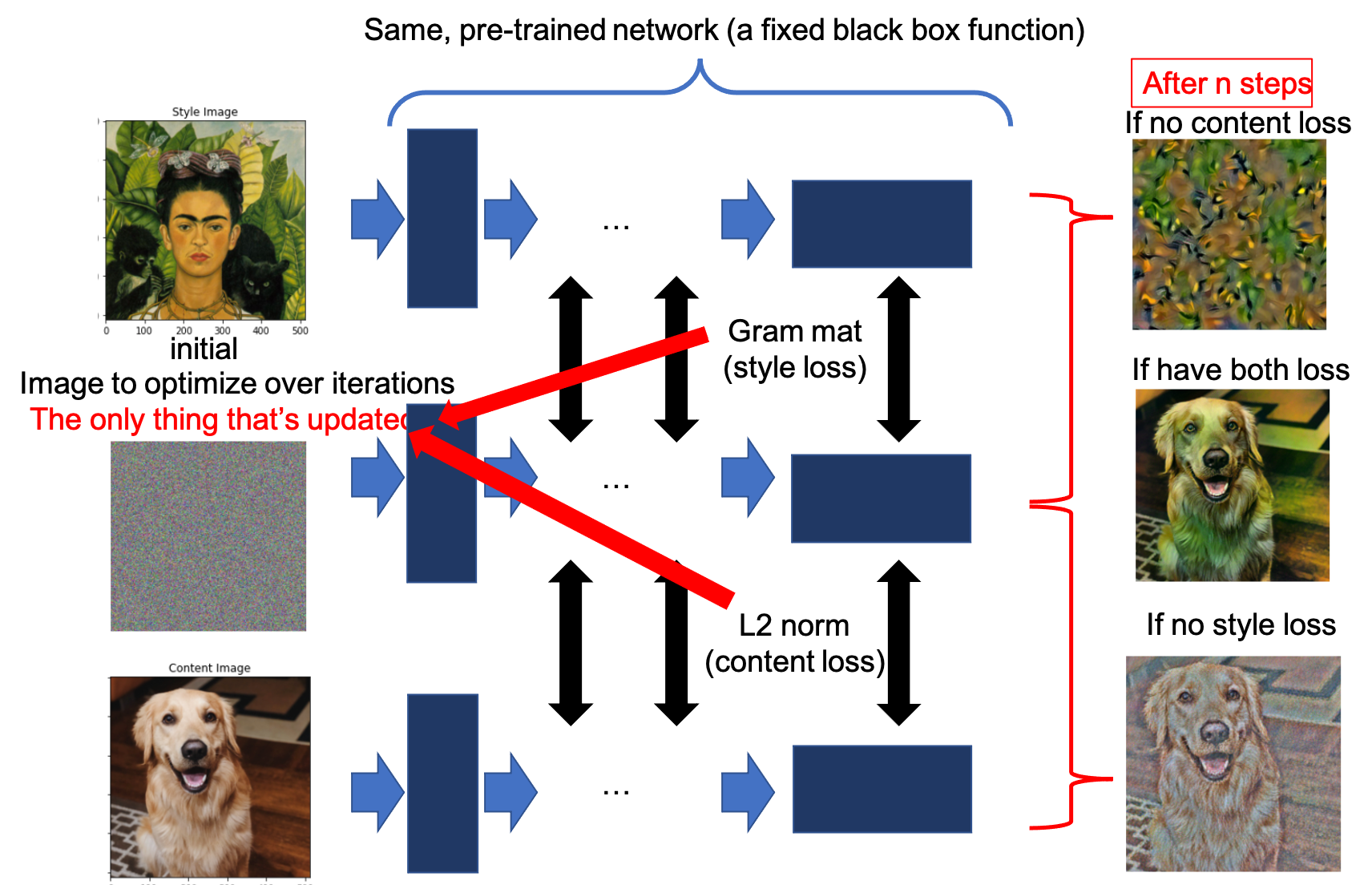
No style loss, just content loss.
We can easily notice that the simpler the network is (the lower the content layer is), the better the reconstruction is, both in terms of convergence rate and image quality. I think this is because bigger network causes higher instability, and there may be a lot of data loss and stucking at local minimum happening, which makes the convergence harder.

I chose conv4 to be the content layer. As the converging process may look very similar, I subtracted the two images and you can see that there are still many pixel-level differences that might be too hard for human to perceive.

No content loss, just style loss.
Again, I choose to use only 1 style layer a time, respectively 1st, 2nd, 4th, 8th, 16th layer.
I observed that, for lower level layer, the textures are more geometrical, rough and shallow. At higher levels, the texture tends to be fine grains.

In this experiment, I choose to use only conv4 as style layer. Unlike the result in exp2, the images generated from different noises are completely different. However I think it's safe to claim that they belong to the same texture.
Include both content loss and style loss.
Following the suggestion, I choose content layer to be conv4 and style layer to be conv1,2,3,4,5.
In experiment 5, I generate images from content image, and I found that the style weight is best to be higher than recommended. I use 10^7 at last. However, the same set of parameter works terrible for random input images. At last, I choose 10^5 for random noise input. This phenomenon is understandable because if given the content image, the influence from style's image is reasonably a lot weaker, which means we need a bigger style weight to balance this factor.
The content weight was kept to be 1. I also use L-BFGS optimizer to and optimized input image for 300 steps.
Here is my tweaking experiment result. The goal is to make an image look like the content, but with the style of the style image.

When input is random noise, the effect is more obvious.



As shown in the figure below, sometimes the generating from content yields better results (e.g. Style 1, 3) and sometimes the generating from noise yields better results (e.g. Style 2). I think the reason is because the nature of the input, and how it matches the texture of the content and style image. For example. since style 2 has less blocks of color as style 1, and the direction is more random than homogeneous compared to style 3, it's easier for a random noise to approach such texture. On the other hand, inputting a real image will make homogeneous texture styles transferred better.
The running time is similar (both ~1min on AWS).

First, I tried my favorite content images with the 3 styles:

I also wanted to try other styles. Thankfully my girlfriend is a good artist, and I was able to use her paintings to generate some novel styles too:

One notable thing is that the "sketch" style seems to fail more often than the others. I think the reason is because black and white images has 2 less information compared to RGB, thus the latent representation might be harmed. Another thought is that it consists of sharp curves that doesn't have good gradients.