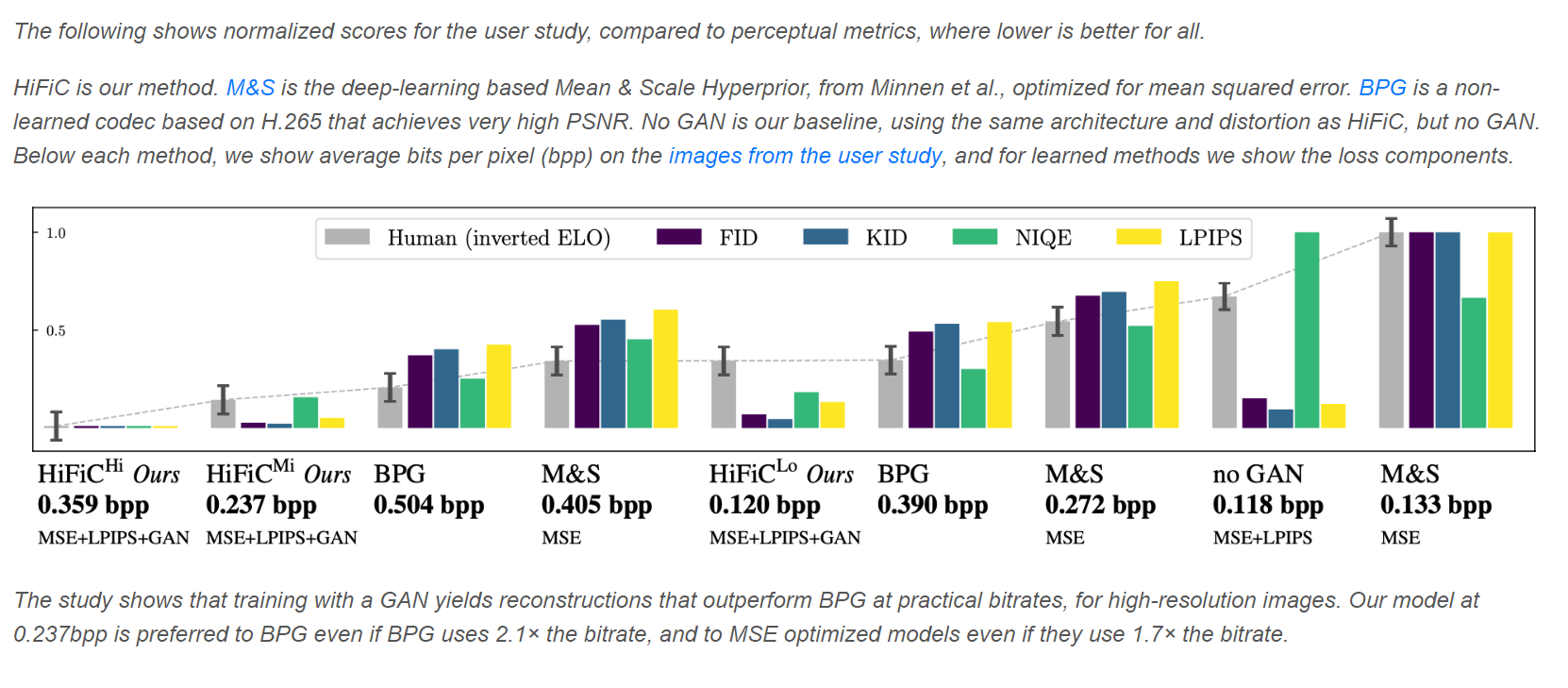
The follow is the user study conducted by this paper:
original compressed


The advancement of image compression has been stucked at JPEG methods over years. To make the image compression more effiective,
people begin to think about new ways to make the image compression better. Using machine learning technology like Generative Adverserial Network to
ompress image is really a big try on it. Motivation for using GAN in image compression is listed as following: image compression are common on most cases,
and compress image with GAN may potential method to save storage space on disk; traditional method does very bad at extreme high compression ratio,
GAN method may help to solve this problem; Modern software system are always bottlenecked by database and storage performance rather than computing power.
This is potential tradeoff between computing and storage to resolve this bottleneck; etc. Since, people are coming with various ideas and motivation on GAN and
image compression work, study image compression would be very meaningful.
In this final project, I will explore image compression with GAN. And this final project focuses on compressing images into at a idea ratio
while maintaining the quality of the compressed images. The basic idea to do this is to try on existing work on image compression with GAN area and
do some modification on existing work to try the improvement.
The most frequently used lossy compression algorithm is JPEG. Various hand-crafted algorithms have been proposed to replace JPEG,
including WebP and JPEG2000. Relying on the video codec HEVC, BPG achieves very high PSNR across varying bitrates.
Neural compression approaches directly optimize Shannon rate-distortion trade-off. Initial works relied on RNNs,
while subsequent works were based on auto-encoders.
This project is mainly based on https://hific.github.io/ This paper combines Generative Adversarial Networks with learned compression
to obtain a state-of-the-art generative lossy compression system. The paper investigates normalization layers, generator and discriminator architectures,
training strategies, as well as perceptual losses. In a user study, the paper shows that its method is preferred to previous state-of-the-art approaches
even if they use more than 2x the bitrate.
The follow is the user study conducted by this paper:
As this final project is focus on improving existing general purpose image compression work, the project needs image dataset that does not limited on specific area. So, I referenced original dataset plus searching online, and mainly found following two datasets as training, test and validation dataset.
Since the original work does not require any fixed size image, it has dataloader to different size images. The datasets are variable sized image. In searching
of datasets for training, there is an condition that the image cannot be too large; otherwise, large images would explode my GPU memory. Luckily,
these two found datasets all satisfies this requirement. All images in these two datasets are roughly smaller than 1MB.
OpenImages believes that having a single dataset with unified annotations for image classification, object detection, visual relationship detection, instance segmentation, and multimodal image descriptions will enable to study these tasks jointly and stimulate progress towards genuine scene understanding. This description shows it is an general purpose dataset, which aligns with this final project's goal. The training set images are a subset of OpenImages.
COCO is a large-scale object detection, segmentation, and captioning dataset. This description shows it is an general purpose dataset, which aligns with this final project's goal. The training set images are a subset of COCO image collection.
The mothed is the modification on the original paper's method. The original paper replies heavily on entropy encoding to get the encoded image size. As focusing on entropy coding algorithm, the model may not notice that there is still possibility on optimzing the original model. The modification on original model can be done by setting a new loss that to limiting the nonzero or non-closezero values in middle compression layer's tensor. By reducing the number of nonzero and non-closezero values compression middle layer helps to improve the compression effieciency.
This idea has two interpolations on improving compression: 1. with entropy coding algorithms, the less number of effiective values in middle compression layers helps the entropy coding algorithm to find a better prapobility so that the entropy encoded binary content size can grow smaller. 2. wihtout entropy coding, the binary content can be directly wrote by a sparse representation matric of effiective content; The less effiective values, the smaller binary size of sparse matrix. However, This new introduced idea may incur a new problem that less effiective values in middle compression layers, the less expressiveness it has. This would introduce difficulties in following generator structure. It is a kind of trade-off. The following is modified loss function based on original paper's loss:
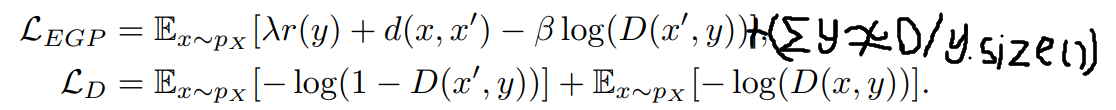
The network structure is still using the original network structure. The reason is that the original model's component is already good as an GAN compression model. Changing the structure of generator or discriminator does not necessitate a novel idea. In addition, the model is already large enough ~2GB. Changing part like discriminator may incur huge amout re-training work. Beside training on top of existing model is good to practice and experiment ideas. Here is network structure illustration:

The first four example iamges are rendered by me in the Visuals Computing System course. And the last three images are collected from internet. None of them appear in training dataset.
original: 2.212285 bpp compressed: 0.070132 bpp


original: 2.247934 bpp compressed: 0.089994 bpp


original: 1.913821 bpp compressed: 0.072314 bpp


original: 9.479342 bpp compressed: 0.321486 bpp


original: 1.513216 bpp compressed: 0.423775 bpp


original: 2.823648 bpp compressed: 0.401271 bpp


original: 3.292623 bpp compressed: 0.634104 bpp


Clearly, as we can tell from above images, this imame compression with GAN method performs very well on general image. Wihtout looking closely into images, human eyes cannot easily tell differences between compressed and original.
When we zoom in to look closely on the above images. We may still find that compressed image lose many small figures. The GAN image compression method omit many details information in compression and only keeps the frequently occurs information through images. To overcome this difficiency, we could train the image compression GAN in a domain specific area. In this way, compression GAN can focus on more domain specific figures so that many more small figures can be perserved from compression.
Another point is that entropy coding is not a very protical idea because we need different entropy coding sample for different set of images to compress. Even with same network structure, images compressed by different network instances may produce different entropy coding tables, which is not very portable. So, this compression is still very research purposed. I believe we can think more to have some new ideas this difficiency in Future.