
The aim of this project is to manipulate natural images by controlling some attributes of interest. In the traditional GAN setup, the encoded latent space is not mathematically constrained to be independent of the image attributes. For the purposes of minimizing reconstruction loss, GANs implicitly encode these attributes into latent space. Disentangling information about these attributes of interest without compromising the quality of reconstruction provides us a way of 'sliding through' these attributes to produce reconstructions that then have the desired qualities. This eliminates the need for involved data collection, as, for example, it could be costly or impossible to obtain pictures of the same person with and without glasses on but using the proposed model it could be computationally inferred.
The proposed approach relies on an encoder-decoder architecture where, given an input image \(x\) with its attributes \(y\), the encoder maps \(x\) to a latent representation \(z\), and the decoder is trained to reconstruct \(x\) given \((z,y)\). At inference time, a test image is encoded in the latent space, and the user chooses the attribute values \(y\) that are fed to the decoder.
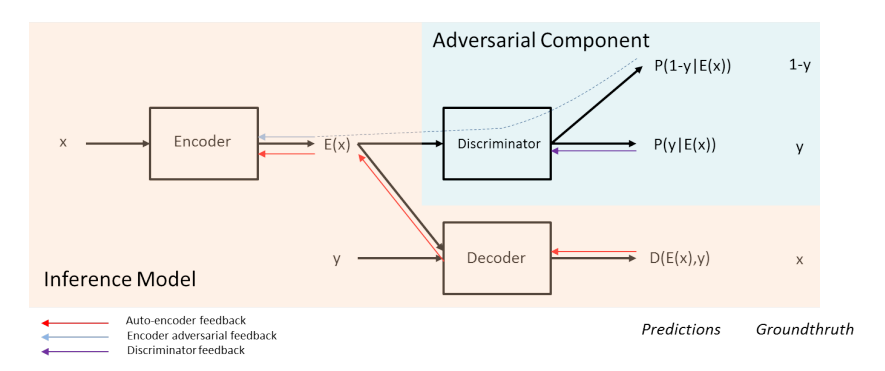
In this process, a classifier learns to predict the attributes \(y\) given the latent representation \(z\) during training while the encoder-decoder is trained based on two objectives at the same time. The first objective is the reconstruction error of the decoder, i.e., the latent representation must contain enough information to allow for the reconstruction of the input. The second objective consists in fooling the attribute classifier, i.e., the latent representation must prevent it from predicting the correct attribute values.
For this project, we wrote our own code for FaderNetworks in PyTorch, as the original repository was in an older version of PyTorch and we preferred the ease of viewing and adding modules to our own code. We also found that we did not require the discriminator to be a convolutional neural network, and were able to get highly accurate discriminators with multi layer perceptrons. Moreover, we finetune the hyperparameters involved including the learning rates of the fadernetwork and the discriminator, the discriminator weight in the overall loss term and the discriminator schedule, with the aim of running the originally extremely compute intensive training on our resources. The training is to be performed on two TITAN RTX GPUs and the reproducible architecture and model checkpoints would be made available upon request.
We trained a fader network on the MNIST dataset, with class labels as the attributes. Below are the resutls after 190 epochs of a reconstruction with original attributes, and one where we enforced the class label 3.

Our model was able to learn a good reconstruction and in most cases, it was able to modify the input image given an attribute.
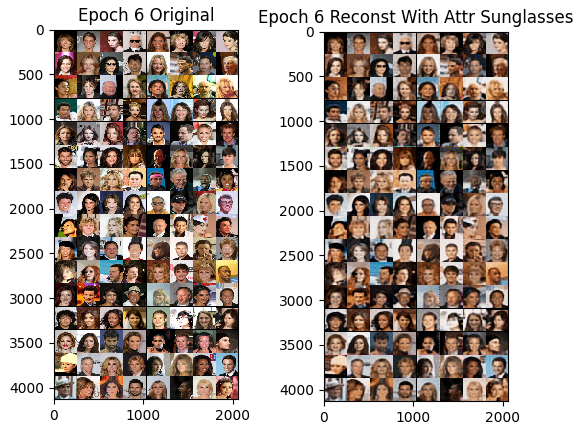
The CelebA dataset contains over 200,000 images of celebrity faces with 40 categotial attributes. We trained a fader network with three attributes and attempted to reconstruct images with the ''sunglasses'' attribute. Our model was able to learn a good reconstruction, but it was not able to reproduce images of people's faces with sunglasses when given the attribute as an input.
The Skyfinder daset consists of labeled outdoor image in various weather conditions. Here, we trained a fader network with the ''night'' label as the attribute aiming to convert night images into daylight images and vice versa.
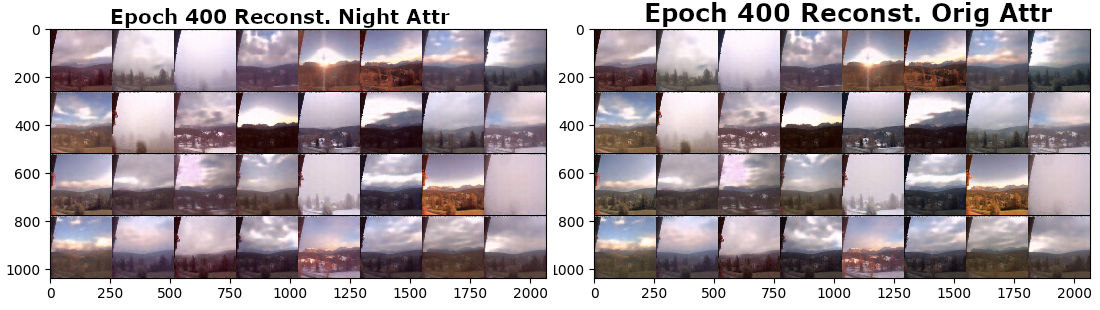
After 400 epochs we can see that the model learns a good reconstruction and it somewhat take the new attribute into account in most cases. Though, the day-to-night changes could be more apparent.
We trained a fader network to convert apple images to oranges. After 100 epochs, the attribute change was noticeable in most examples.

With the excpetion of a few failure cases, our model was able to learn a good reconstruction and convert apples to organges in only 100 epochs.
We were able to edit images by specifying attributes in most cases, but our approach struggled with complex and variable data like CelebA. We found that the discriminator schedule greatly affects the quality of the reconstruction. A schedule that is too aggressive might impede early stage learning and even with origianl attributes, good reconstruction is not feasible. On the other hand, a lax discriminator schedule leands to the input attribute being ignored.
In general we found that there was a tradeoff between the reconstruction quality and latent space disentanglement. If we used a discriminator schedule that was too 'aggressive', where the discriminator loss would be heavily weighted, we found that the reconstructions tended to be of poor quality and if we used a discriminator schedule where the discriminator loss was not as heavily weighted, the quality of reconstructions improved whereas there were minimal changes to the image upon changing the attribute. This is likely because when the discriminator does not play as big a role in the loss term, the latent space would inherently encode attribute information, circumventing the problem we intend to solve.