|
|
|
|
 |
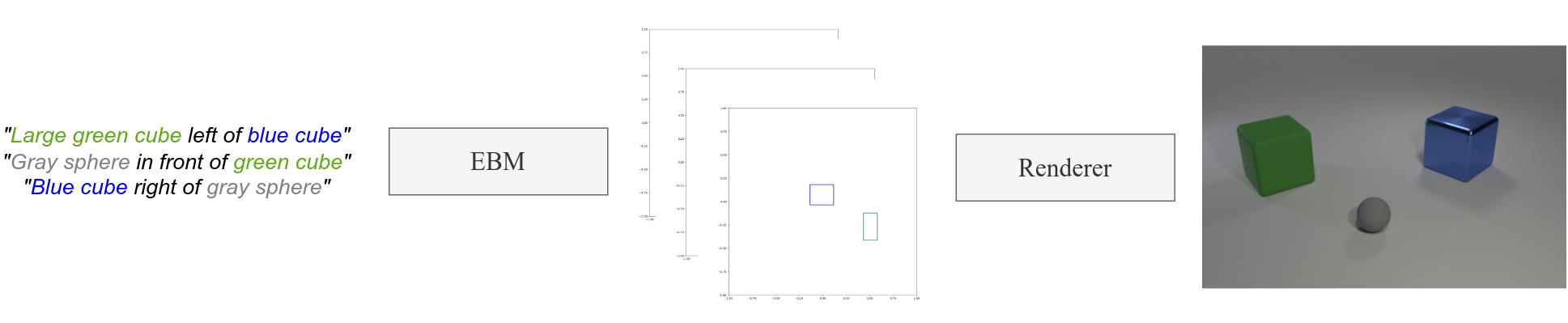
| Robotic policies often rely on goal images. However, how to obtain these images in a new environment is not a trivial problem. We investigate image generation as a possible solution. Figure adapted from [1]. |
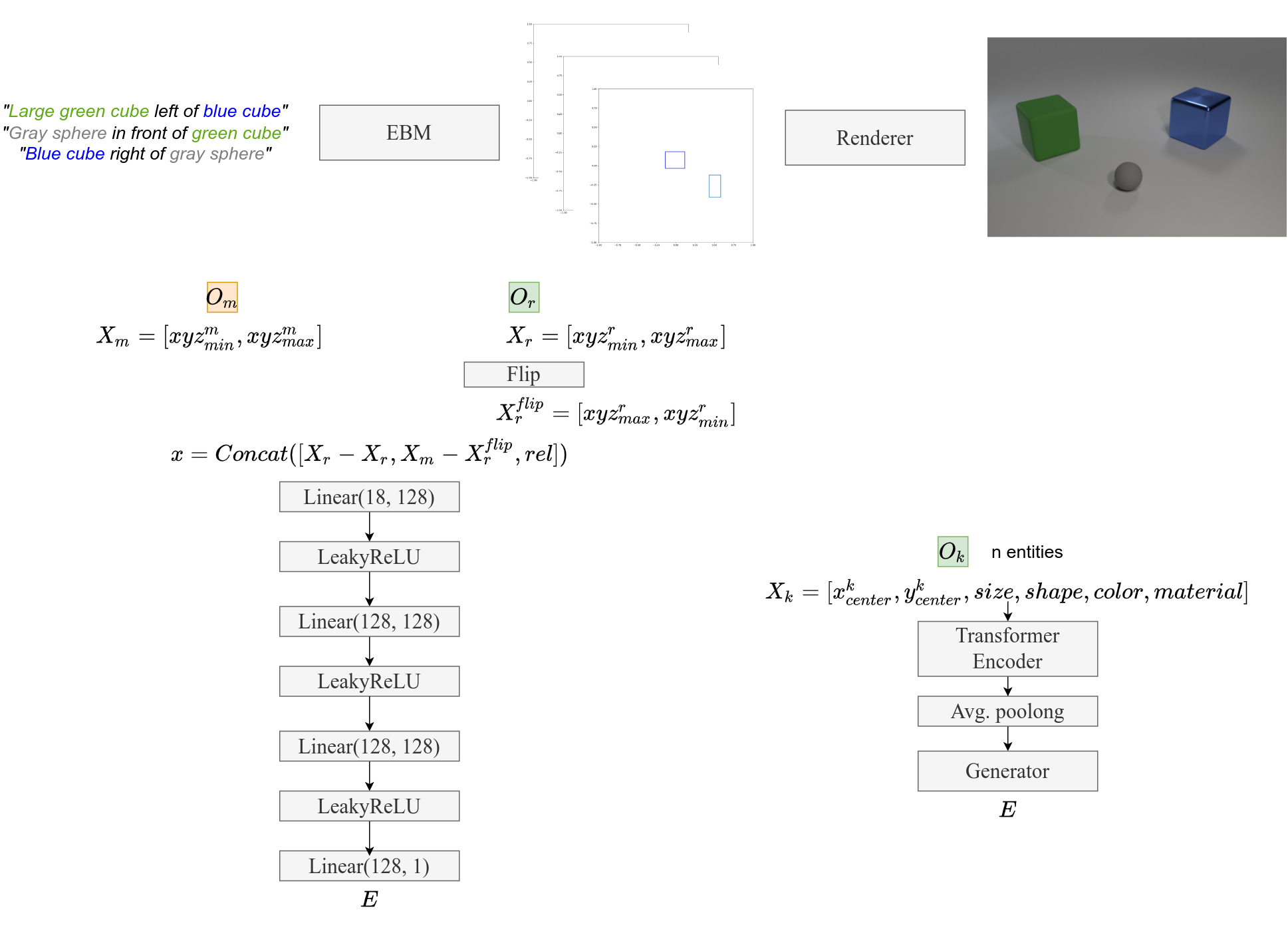 |
| Upper: Full pipeline of our model. The input is a language scene graph that is converted to abstract symbolic representations which are fed into a rendering model to output an image. Bottom left: The architecture of the Concept EBM that maps graphs to boxes. Bottom Right: The architecture of the rendering module which maps object-centric graphs to images. |
| Method | Relation acc | Graph acc |
|---|---|---|
| CLEVR Full | 84.5 | 6.9 |
| CLEVR 1% | 75.8 | 1.0 |
| Method | FID |
|---|---|
| GT graphs | 99 |
| Predicted graphs | 144 |
| Predicted graphs 1% | 175 |
 |
 |
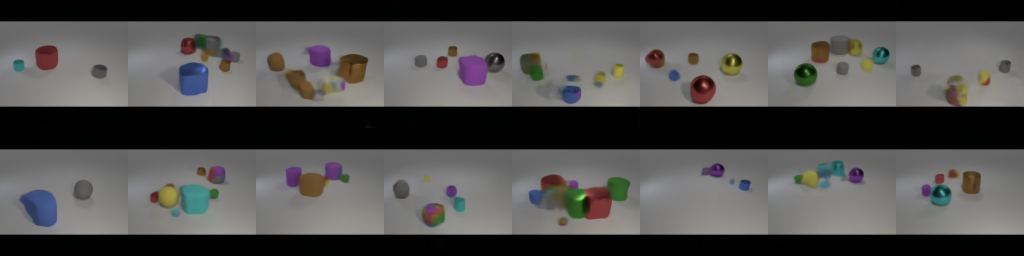 |
 |
 |
 |
References[2] Thomas Weng, Sujay Bajracharya, Yufei Wang, Khush Agrawal, David Held. FabricFlowNet: Bimanual Cloth Manipulation with a Flow-based Policy. CoRL, 2021. [3] Corey Lynch, Pierre Sermanet. Language Conditioned Imitation Learning over Unstructured Data. RSS, 2021. [4] Mohit Shridhar, Lucas Manuelli, Dieter Fox. CLIPort: What and Where Pathways for Robotic Manipulation. CoRL, 2021. [5] Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, Ilya Sutskever. Learning Transferable Visual Models From Natural Language Supervision. CVPR, 2019. [6] Alec Radford, Luke Metz, Soumith Chintala. Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks. Arxiv, 2021. [7] Aditya Ramesh, Prafulla Dhariwal, Alex Nichol, Casey Chu, Mark Chen. Hierarchical Text-Conditional Image Generation with CLIP Latents. ArXiv, 2022. [8] Tero Karras, S. Laine, and Timo Aila. A style-based generator architecture for generative adversarial networks. CVPR, 2019. [9] Nan Liu, Shuang Li, Yilun Du, Joshua B. Tenenbaum, Antonio Torralba. Learning to Compose Visual Relations. NeurIPS, 2021. [10] Will Grathwohl, Kuan-Chieh Wang, Jorn-Henrik Jacobsen, David Duvenaud, Mohammad Norouzi, Kevin Swersky. Your classifier is secretly an energy based model and you should treat it like one. ICLR, 2020. [11] Igor Mordatch. Concept learning with energy-based models. ICLR Workshops, 2018. [12] Yilun Du, Shuang Li, J. Tenenbaum, Igor Mordatch. Improved contrastive divergence training of energy based models. ICML, 2021. [13] Drew A. Hudson, C. Lawrence Zitnick. Generative Adversarial Transformers. ICML, 2021. [14] Max Welling and Yee Whye Teh. Bayesian learning via stochastic gradient langevin dynamics. ICML, 2011. [15] Bingchen Liu, Yizhe Zhu, Kunpeng Song, Ahmed Elgammal. Towards Faster and Stabilized GAN Training for High-fidelity Few-shot Image Synthesis. ICLR, 2021. [16] Justin Johnson, Bharath Hariharan, Laurens Van Der Maaten, Li Fei-Fei, C Lawrence Zitnick, Ross Girshick. Clevr: A diagnostic dataset for compositional language and elementary visual reasoning. CVPR, 2017. |