Methodology
We precondition the output of the GAN model based on certain vibes to tune the artistic nature of the music video.
Below are samples of the changes that vibes can add to the output.
| Without vibes |
Painting |
Dark |
Weird |
|
|
|
|
VQGAN
Vector-Quantized Generative Adversarial Network (VQGAN) is a deep learning model that can be thought of as a combination of VQVAE and GAN. VQGAN has similar GAN architecture with a Generator that creates an image from a latent code, and a Discriminator that is tasked to differentiate between real or fake images. The Generator and Discriminator are then trained together whereby the two tried to outdo each other. At test time, we only use the Generator to generate an image by sampling the latent code. VQVAE has several additional properties from the vanilla GAN. It uses image patches for the Encoder and the Discriminator. It has a codebook of representation that is learned using a Transformer.
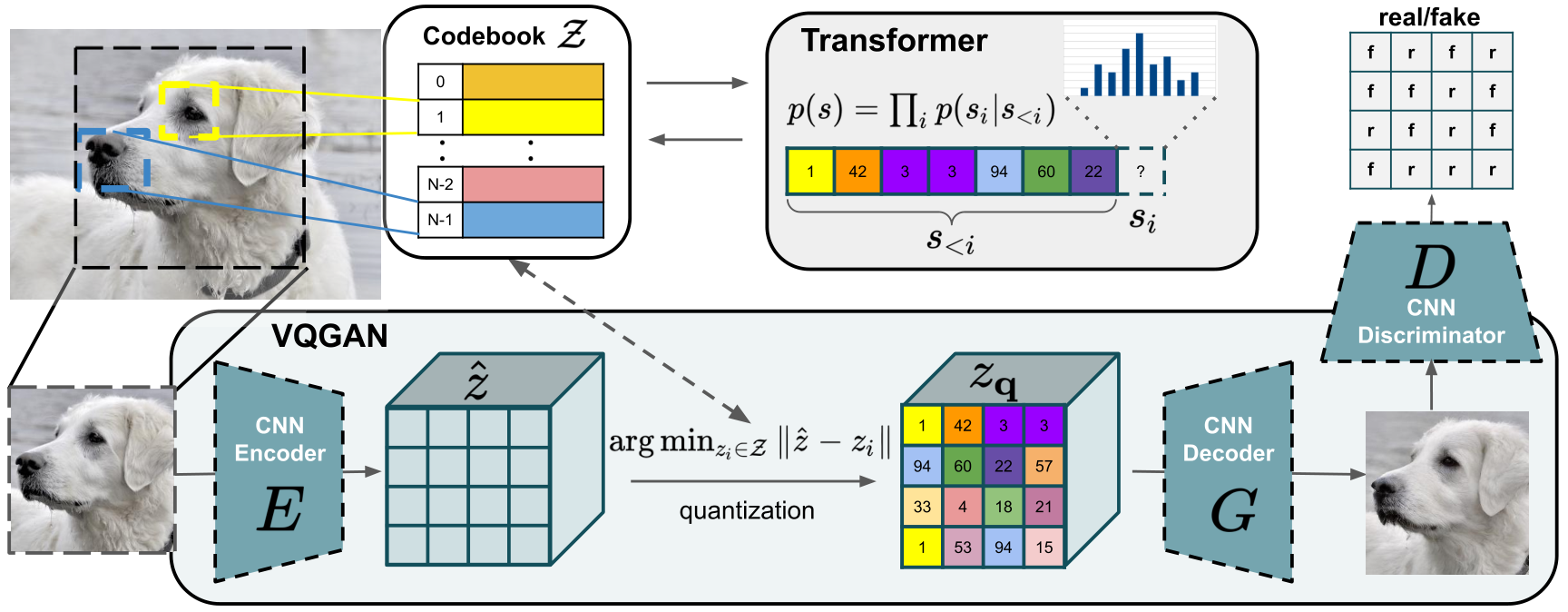
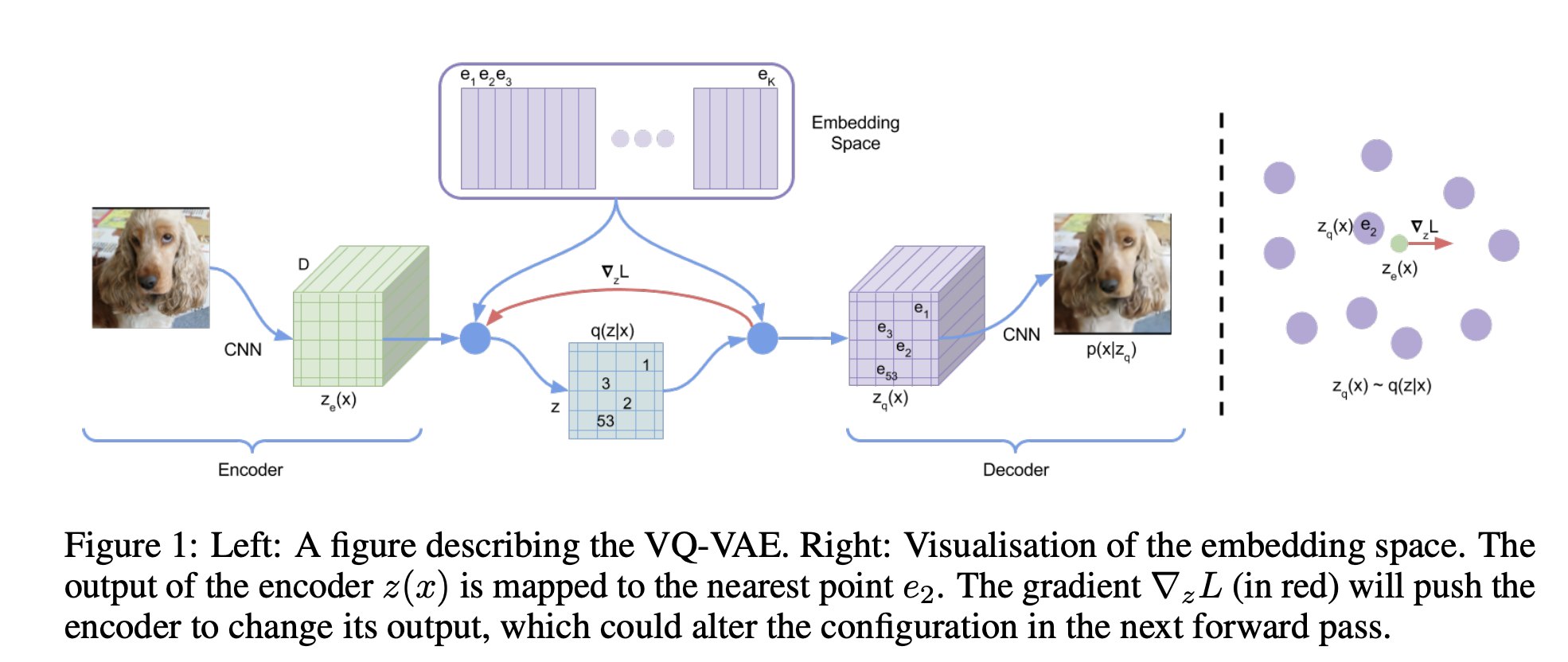
The Vector-Quantization method is taken from the Vector-Quantized Variational AutoEncoder (VQVAE)
paper. Instead of learning a continuous distribution for priors, it quantized the problem by first learning a codebook of embeddings that can be retrieved easily. VQGAN employs a similar method.
CLIP
Contrastive Language-Image Pretraining (CLIP) is a deep learning model that has been trained on millions of image-text pairs. The novelty of this model is that it employs contrastive learning. Therefore, on top of teaching to model to learn to find the most similar image and text pairs, it forces to model to distance a particular embedding from its non-pairs. Concretely, the model first extracts embeddings from the dataset of images and text descriptions. The exact information about encoders used is not important, but the paper experimented with ResNet/Transformers for the image encoder and Transformers for the word encoder. The model then compared each image embedding to each text embedding, creating an N-squared matrix. The objective functions is to maximize the similarity between the correct image-text pairs, e.g. I1 and T1 and minimize the similarity between all others, e.g. I1 and T2. One can use many different similarity metrics, but the paper mentioned that it used cosine similarity.

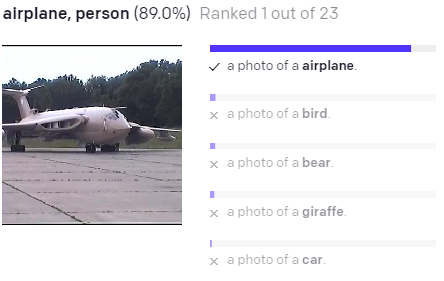
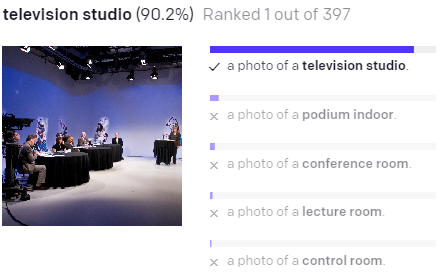
The strength of CLIP as compared to other image-text models can be seen with the example below. Not only did CLIP correctly associate the images and
texts, but CLIP predicted that the other options has very low probability. A model that is not trained contrastively might still have the same
highest scoring result, but the other options might still have relatively high probability. This capability is important to use because we are repurposing
CLIP for our keyframe generation is a zero-shot fashion, i.e. we have not re-trained for fine-tuned the CLIP model to our inputs, therefore having a strong
understanding of image and text embeddings is important. This also allows the fine-tuned optimization to our lyrics, producing outputs that are visually different
even though semantically adjacent lyric segments can be similar. This avoids mode collapse in the generative model, making sure our music video is interesting.
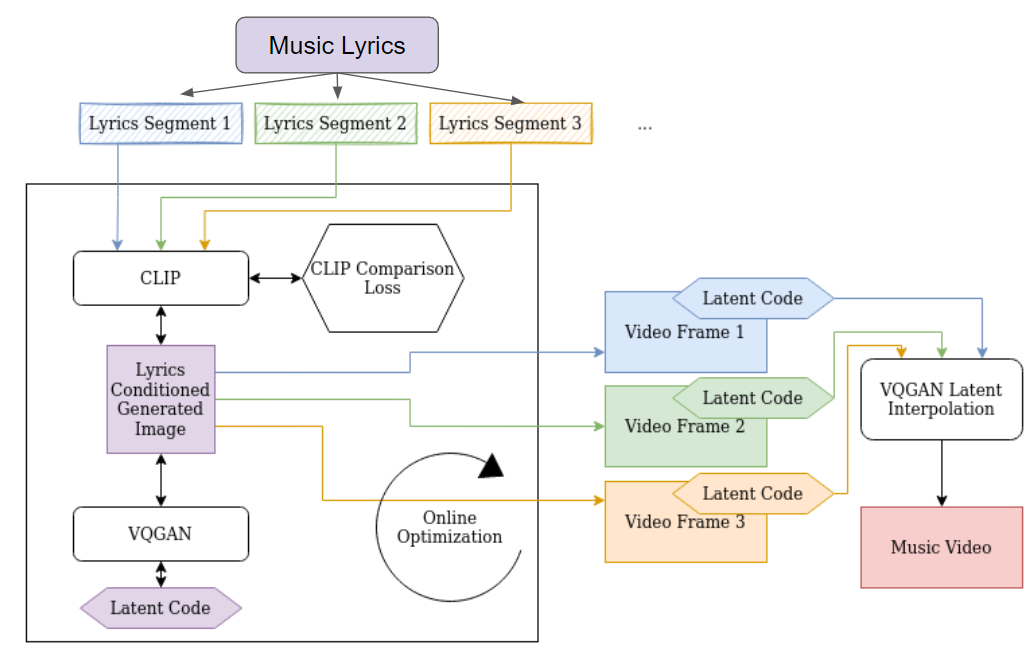
Our Pipeline
Our pipeline starts off with the entire lyric text of a song. We then break the lyrics apart into segments based on semantics, such as
"I see skies of blue, and clouds of white" and "The bright blessed day". The timing information from the original song audio is taken into account to
know the temporal length of each lyric segment, so that we can sync the keyframes generated to the song audio. We then use an initial latent code z
and use it to generate an image from the VQGAN. The two are used as input to CLIP to generate a similarity score for our online optimization. One trick
we used is to use the previous frame latent code z as an initial latent code for the next frame, as such we maintain some temporal consistency between the
keyframes as they will not be optimized from random samples everytime, only the very first keyframe. Once we have obtained the keyframes for all the lyric
segments along with their latent codes, we used the temporal length of each lyric segments to interpolate between consecutive latent codes at the correct
granularity to create enough intermediary frames to be stitched together as a music video.
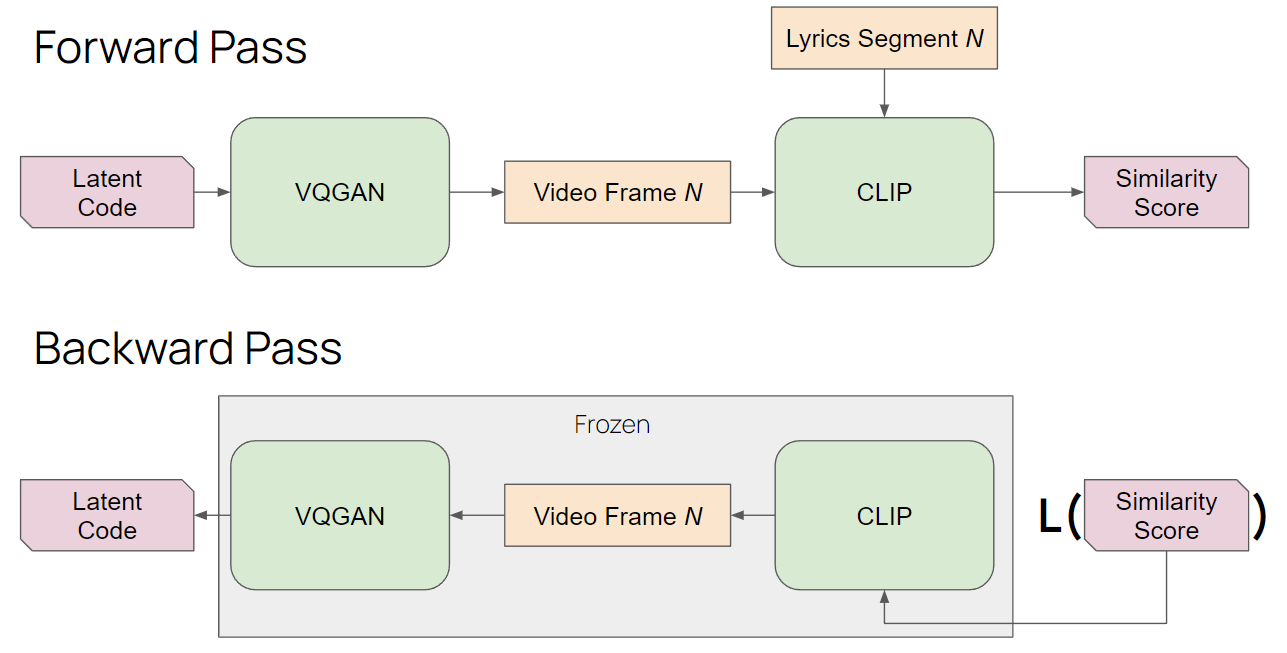
During our forward pass through the network, we will randomly sample a latent code z to generate an image from the VQGAN and pass that output image to
CLIP along with the lyric segment to generate a similarity score. During the backward pass, we freeze the VQGAN and CLIP weights as we do not want to optimize
their parameters anymore. The gradient descent optimization will only affect the latent code z which we randomly selected at the start. The end result of the
online optimization will be a generated image that is conditional on the lyric segment.
We used the .lrc file format standard to indicate the timing of each lyric segments. This allow for automatic processing with an
attacked .mp3 file to create the music video without manual post-processing or editing. Below is a sample of an .lrc file, users
can create their own music video by simply creating another .lrc file and its corresponding audio file.
[length:02:17.51]
[re:www.megalobiz.com/lrc/maker]
[ve:v1.2.3]
[00:06.34]I see trees of green, red roses too
[00:13.97]I see them bloom for me and you
[00:19.80]And I think to myself what a wonderful world

