16-726 Project: GANs for Coarse Style and Scene Data Augmentation
In many outdoor and in the wild image classification problems there is a challenge in
producing generalized models that do not overfit to the specific dataset they were trained on.
For example, in agriculture, a classifier trained on data of a specific crop taken in the field
on one day will perform poorly on data collected from a different field, or even on the same
field on a different day. This is because the current state of the art data augmentation
methods are unable to reproduce the varying illumination and texture changes. This is a major
issue because every time the same classification task has to be run on similar datasets,
a model has to be trained or fine-tuned.
Recently, generative models have demonstrated exceptional ability to create realistic looking
photos of outdoor scenes. Additionally, recent work on style-mixing, latent space perturbations,
and texture encoding substitutions have shown that GANs can effectively alternate coarse style,
texture, and scene representation in images.
In our project, we would like to apply these recent works on generative models towards augmenting
data, with the ultimate goal of improving the classification task across datasets. We would like
to demonstrate that using GANs to augment data by altering coarse details will allow classifiers
to better generalize and not overfit the training data.
Our code can be found here.
It is a forked repo of
Swapping AutoEncoder
with changes to run our pipeline.
Related Work
Controllable Image Generation and Manipulation
StyleGAN allows for a separation of high-level attributes allowing for the control of both coarse and fine details of the generator output. Works on separating style and content space for neural style transfer are built upon in Deep Photo Style Transfer by applying affine color transformation constraints to generate more reallistic images. Lastly, a swapping autoencoder architecture is proposed in Swapping Autoencoder for Deep Image Manipulation which allows independent style and content image components to be swapped for realistic image synthesis.
StyleGAN Architecture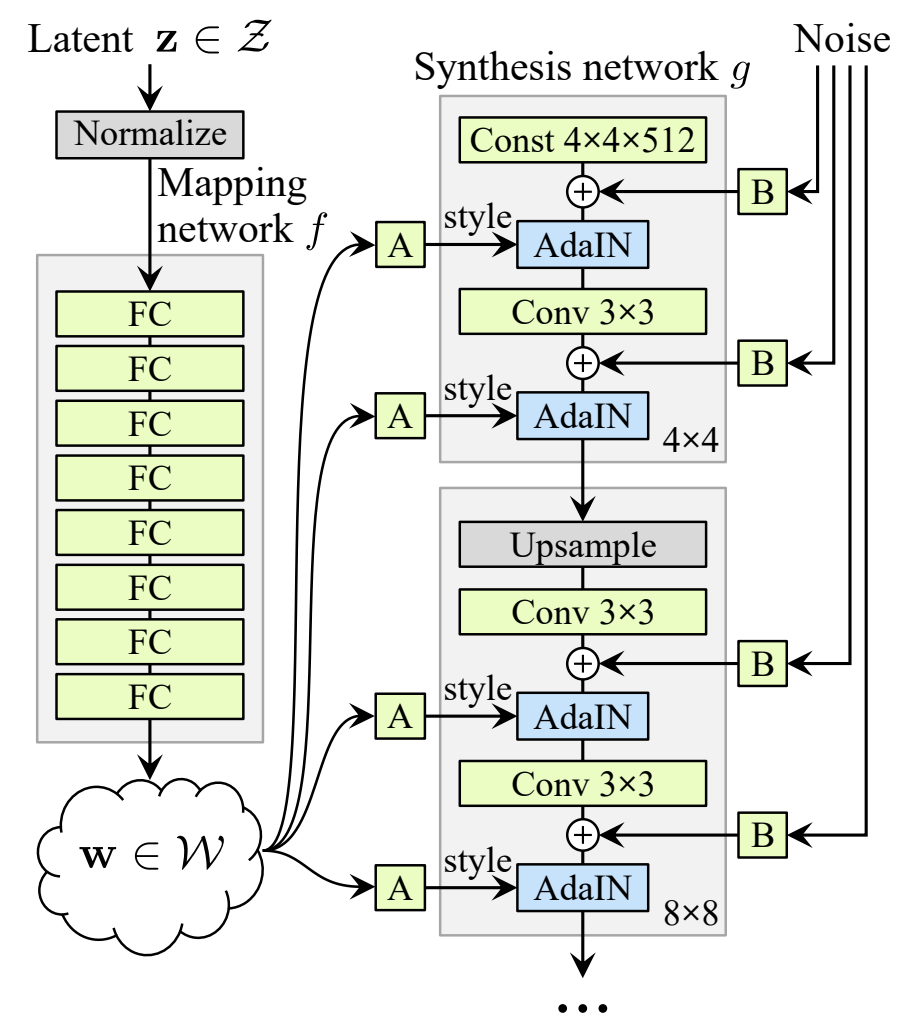
Data augmentation
Data Augmentation Using GANs addresses using GANs for data augmentation, but the data is numerical and does not relate to image generation or classification. DCGAN and ACGAN are used for medical image augmentation for liver lesion classification in this work; however, it is for a very specific application that does not require content control. Data Augmentation Generative Adversarial Networks presents a Data Augmentation Generative Adversarial Network, where the concept of conditional GANs are extended towards the task of augmenting data. Yet, there is no control over the style or coarse features of the synthetic data. Similarly, Ensembles of GANs for synthetic training data generation use multiple GANs to generate synthetic data for medical imaging to further cover the data distribution, but have no method to control the style or texture of the outputted images. Lastly, Ensembling with Deep Generative Views use GANs to synthesize data by injecting alternations into the latent code. However, they focus on more object specific alterations rather than background scenery changes. As well, they use GANs to improve classification during inference, as oposed to augmenting data for training.
Ensembling with Deep Generative Views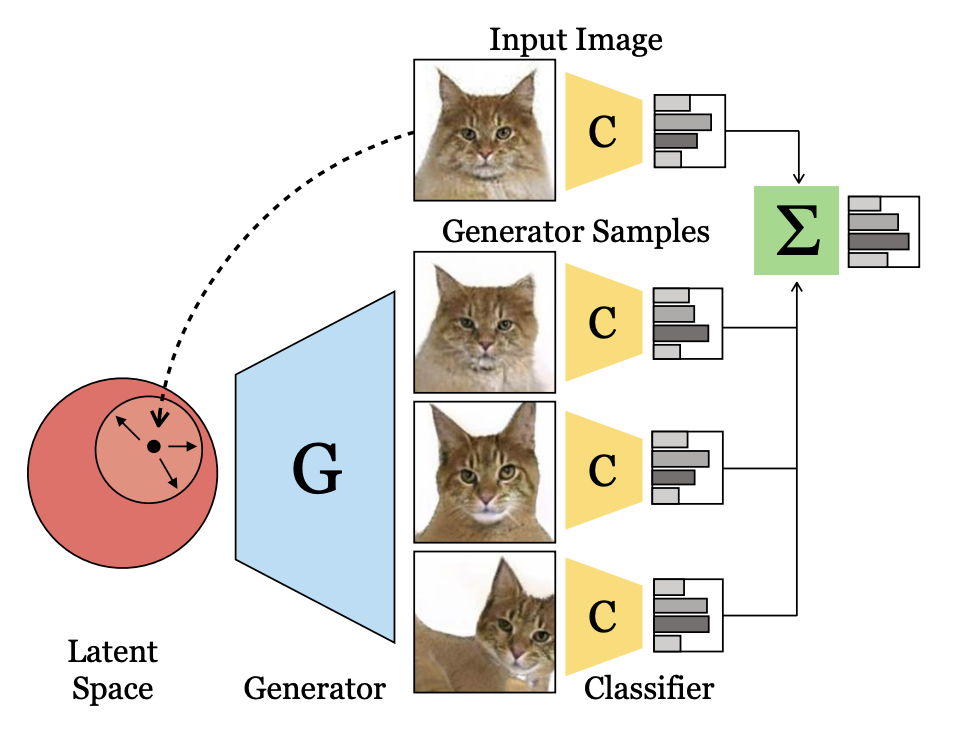
Task Definition and Data
In this work, we evaluate the effectiveness of the generative data augmentation method through the image classification task.
Specifically, we collect images from the following four classes, forest, mountain, sea, and desert, and trained a model to
classify input images as one of these four classes.
In this work, we focus specifically on landscape, scenic images. We noticed that top ranked images follow a similar distribution.
For instance, a query of forest returns forest images in the spring that are mostly in vibrant green. A query of desert
returns images of desert during the day. This distribution does not encompass a full representation of these landscapes in the wild.
For example, it does not capture seasonal change for forest, such as forest during the winter or forest during autumn.
It also lacks data for desert during the night. We tackle this issue by augmenting our training data with generated images
of the above missing aspects.
Forest
 Mountain
Mountain Desert
Desert Sea
Sea
For our experiment, we collect two sets of data. The first dataset - Common Scene Dataset - contains images of the four classes under more common scenario.
These include sunny sea, daytime desert, spring forest, and daytime mountain. We manually collected
approximately 200 images for each class from scrapping the Internet. Our goal is to train a model that can better generalize
across the same class under different scenarios. To evaluate this, we collect a second test dataset, which includes images of the
same four classes under different scenarios. This second dataset - Uncommon Scene Dataset - includes images of
sunset sea, nighttime desert, winter forest, and autumn mountain. We manually collected 75 images
for each scenario for testing purposes.
Winter Forest
 Autumn Mountain
Autumn Mountain Nighttime Desert
Nighttime Desert Sunset Sea
Sunset Sea
Lastly, we also needed to collect style images to augment the training data. These images are used to augment the background texture
of the Common Scene Dataset to represent in the Uncommon Scene Dataset. There are four classes of style images which include
snow, autumn, nighttime, and sunset . We manually collected approximately 75 images for each class
for augmentation.
Snow
 Autumn
Autumn Nighttime
Nighttime Sunset
Sunset
Model Architecture
Image Classification Model
For the image classification model, we used a pre-trained VGG-19 backbone to extract the features of the input image. The extracted feature is fed to a 3-layer MLP, whose final layer outputs a prediction of the class label for that image.
Image Classification Model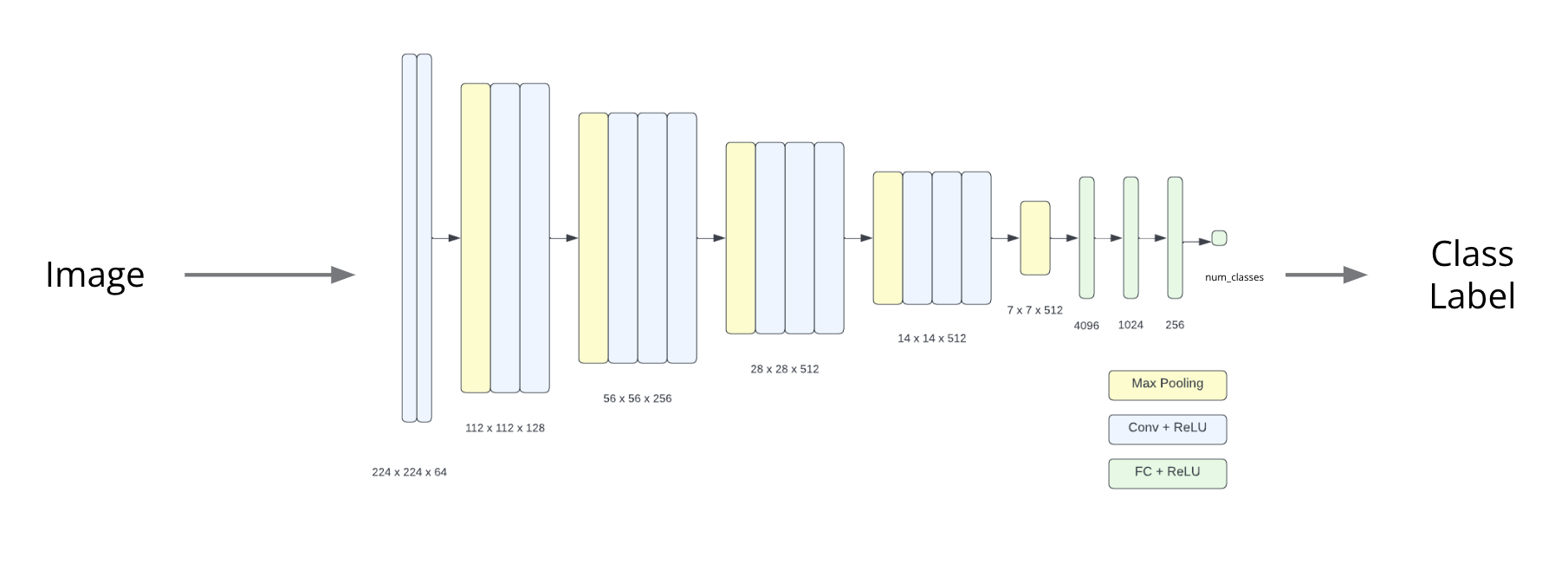
Generating Augmentation Data
To generate augmented training data, we used the pretrained mountain model from Swapping Autoencoder for Deep Image Manipulation. The encoder was used to extract structure and texture codes. The decoder was used to create augmented training images from the structure code and interpolated texture codes from the structure and style images.
Swapping Autoencoder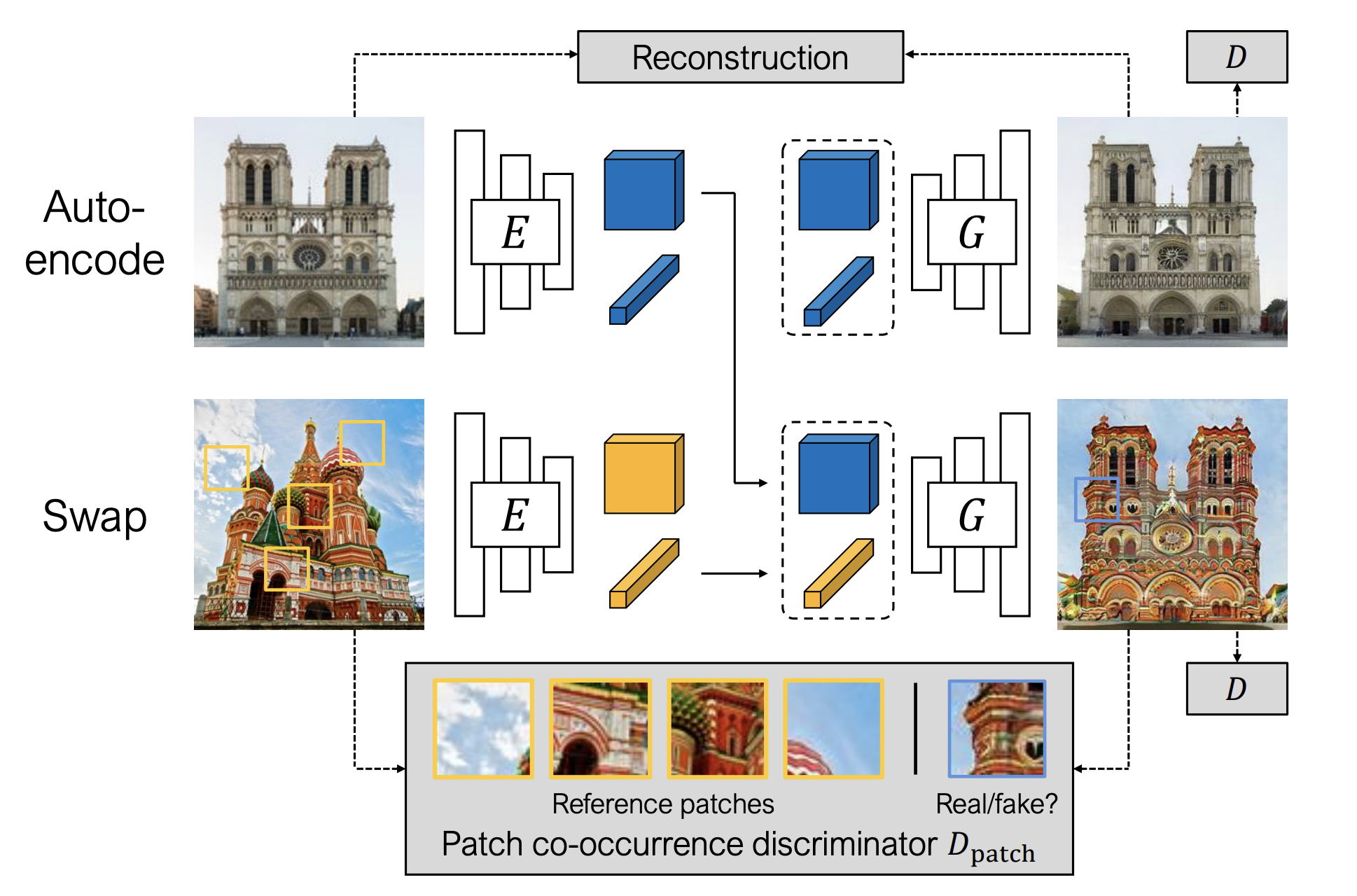
Training Pipeline
Extracting Style Texture Latent Codes
The first step in the pipeline is extracting the texture latent codes for all of the images in the style dataset. Each image is resized to 512x512 and normalized with 0.5 mean and 0.5 standard deviation for each channel. It is then passed to the encoder where the texture codes are saved for future augmentation.
The texture codes are single dimension feature vectors of size 2048. To verify the separability of the latent codes across the style classes, pca is run on the texture codes to reduce the dimensionality for visualization. Below are the results using two and three dimensions. It is evident that is separability across style classes. As well, there is the most overlap between night and sunset, which is expected as there are typically a lot of similarity between those two scenes.
PCA 2D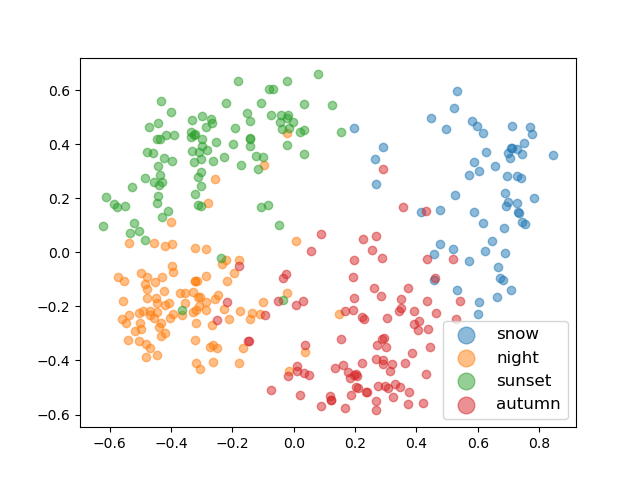 PCA 3D
PCA 3D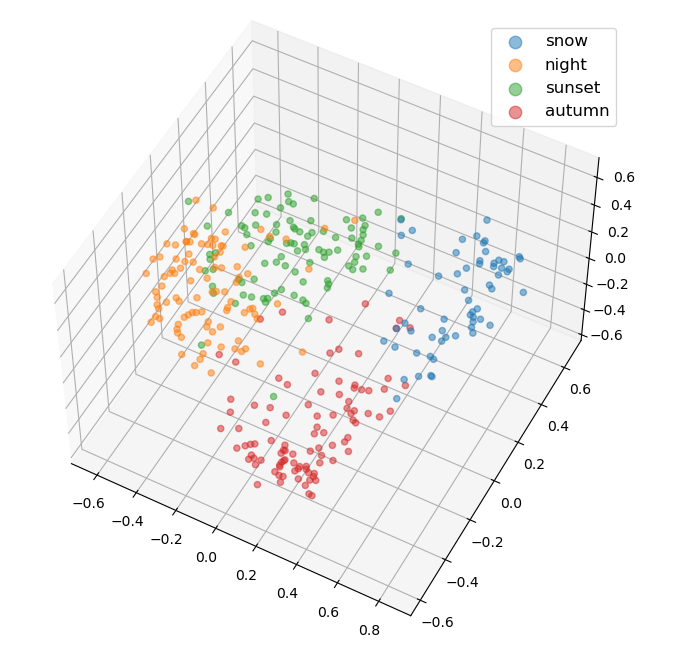
Augmenting the Training Data
The next step is augmenting the training data. First, the Common Scene Dataset is dividing into training and testing sets. Only the images in the training set are augmneted. Each image is resized to 512x512 and normalized with 0.5 and 0.5 standard deviation for each channel. The encoder then extracts the structure and texture codes.
Next, for each desired style augmentation, a random style texture is selected from the previously extracted style texture latent codes. Then, a new texture code is linearly interpolated from the original image's texture code and the randomly sampled style texture code. Lastly, an augmented image is generated by the decode using the original image's sturcture code and the interpolated texture code.
Through experimentation, we found the best inerpolation weight to be 0.9 in favour of the style texture. A weight of 1.0 made the resulting image look too much like the style image. This is a result of using a pretrained swapping encoder model that was not trained on our specific dataset. Lowering the weight resulted in less noticeable augmentations.
Structure Image
 Style Image
Style Image
0.25 Interpolation Ratio
 0.5 Interpolation Ratio
0.5 Interpolation Ratio 0.9 Interpolation Ratio
0.9 Interpolation Ratio 1.0 Interpolation Ratio
1.0 Interpolation Ratio
Below are a few more augmentation examples.
Original Forest
 Original Mountain
Original Mountain Original Desert
Original Desert Original Sea
Original Sea
Snow Augmented
 Autumn Augmented
Autumn Augmented Night Augmented
Night Augmented Sunset Augmented
Sunset Augmented
Original Forest
 Original Mountain
Original Mountain Original Desert
Original Desert Original Sea
Original Sea
Autumn Augmented
 Sunset Augmented
Sunset Augmented Sunset Augmented
Sunset Augmented Snow Augmented
Snow Augmented
Training the Classifier
After all the data is generated the classifier is ready to be trained. Before being passed to the network, each image is is resized to 224x224 and normalized with means (0.485, 0.456, 0.406) and standard deviations (0.229, 0.224, 0.225) as per VGG convention. As well, each image is randomly flipped about the horizontal access. Cross-entropy loss is used to train the network, which outputs logits representing the log-likelihood of the image class.
Inference
The last step in the pipeline is running inference on the specified test set. Note that there are no augmented images in the test set. Each image is preprocessed the same way when training except without the horizontal flipping.
We implemented two types of inference: standard and gan-ensembled. Standard inference uses the model to predict the class of each image and calculates the accuracy accordingly. Gan-ensembled inference is our variation of Ensembling with Deep Generative Views. In this paper, the authors perterb the latent space of the image and pass it to a generator to obtain additional prediction samples. The predicted logits of the original and synthesized images are then weighted to obtain a final class score. We follow a similar course of action; however, instead of perturbing the latent space of the image, we use the swapping autoencoder model to generate additional samples. For each test image, a random style image is selected for each style class, and the test image's texture is swapped using the same 0.9 interpolation weight. Then, we use the same enseble classifier decision to determine the true class prediction. Through experimentation, we found the best ensemble α to be 0.8. Because we use four style classes, this results in an equal weighting between the original image prediction and the synthesized image predictions.
Trained Classifiers
Training Details
Each classifier was trained using an Adam optimizer with a batch size of 16 and learning rate of 0.0002. The number of training epochs was 250, however if the loss fell below a certain threshold for a specified number of consecutive iterations then training terminated early. Each model was trained using an NVIDIA GeForce RTX 3070.
The images used to train were selected from the Common Scene Dataset. The dataset contained a total of 660 images and were split into 526 training images and 134 test images (80:20 split).
Base Classifier
The Base Classifier was trained only on the training images. No additional augmentation was performed except for random horizontal flipping. Below is a plot of the training loss.
Base Classifier Training Loss
Simple Augmentation Classifier
The Simple Augmentation Classifier was also trained only on the training images. However, in addition to random horizontal flipping, the image was scaled to size 246x246 and then randomly cropped to 224x224. Below is a plot of the training loss.
Simple Augmentation Classifier Training Loss
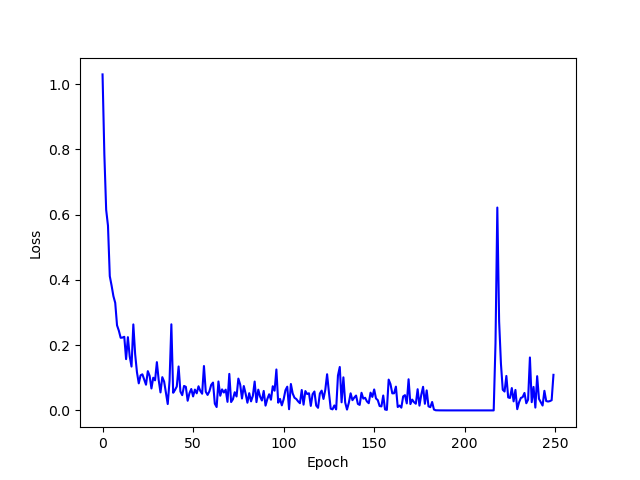
Diffaug Augmentation Classifier
The Diffaug Augmentation Classifier was also trained only on the training images. It uses the cropping augmentation method desribed above in addition to differential augmentation. Differential augmentation includes adding random brightness, saturation, and contrast; randomly translating the image; and randomly cutting out sections of the image. Below is a plot of the training loss.
Diffaug Augmentation Classifier Training Loss
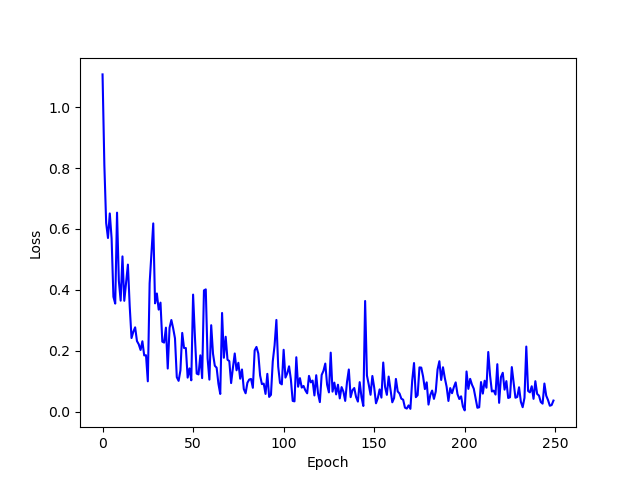
Single GAN Augmentation Classifier
For the Single Augmentation Classifier, swapping autoencoder augmentation was used. However, only forest images were augmented using the textures from the snow style images. Each forest image was augmented using one randomly selected snow style image. Below is a plot of the training loss.
Single GAN Augmentation Classifier Training Loss
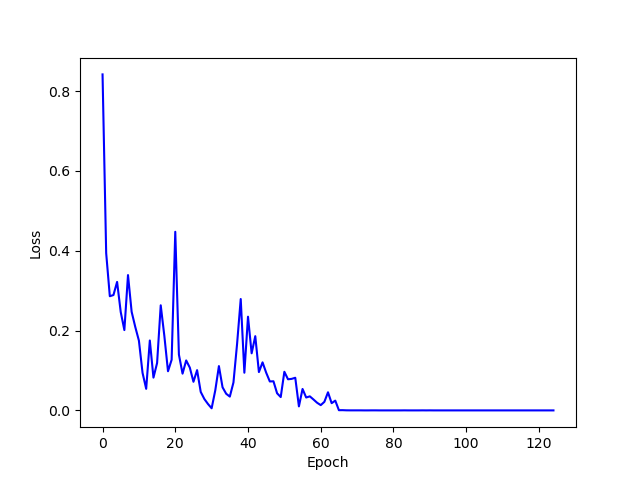
Full GAN Augmentation Classifier
For the Full GAN Augmentation Classifier, all training images were augmented using textures from all four style classes. Each image was augmented using one randomly selected style image from each class, meaning there were five times as many training images after augmentation compared to the Base Classifier. Below is a plot of the training loss.
Full Augmentation Classifier Training Loss
Experiments and Results
Common Scene Dataset
We first ran inference for all models on the Common Scene Dataset test split. All classifiers use standard inference. The results can be seen below.
Accuracy on Common Scenario Test Set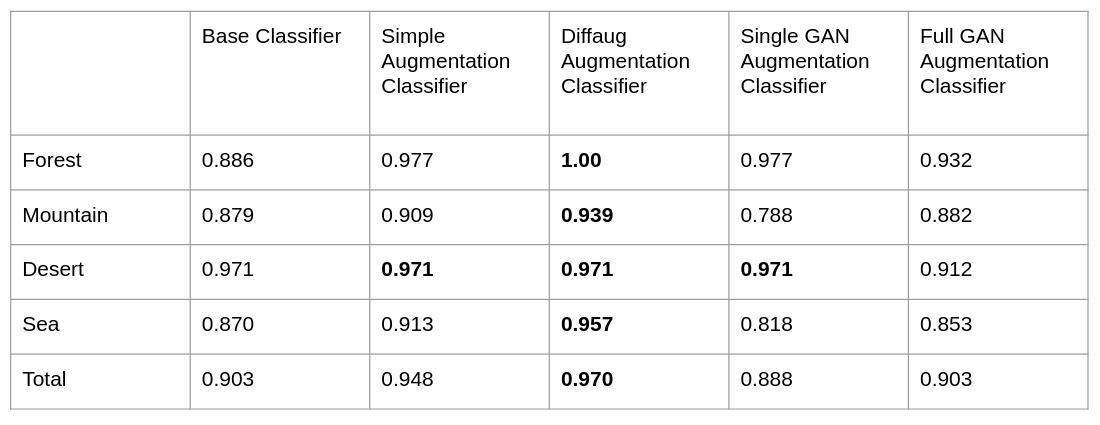
All classifiers perform well on the test split. This validates that the models were trained correctly, and are able to accurately classify images with similar characteristics as the data they were trained on. The Base Classifier, Single GAN Augmentation Classifier, and Full GAN Augmentation Classifier all perform similarly overall, with the Single GAN Augmentation Classifier performing the worse, but not by much. It is expected that these clasifiers perform similarly as the uncommon textures used to augment the gan classifiers are not prominant in the test set. What is also interesting is that the Single GAN Augmentation Classifier performed better at detecting trees at the cost of doing worse in other classes, particularly mountatins. This can be explained by the fact that this model was trained on only augmented forest data, and as such it will be more likely to predict forests over other classes.
What is most note worthy is that the Simple Augmentation Classifier and Differential Augmentation Classifier performed much better than the rest, with the Differential Augmentation Classifier demonstrating the best result among every class. This is the expected result as augmentation is performed to allow models to better generalize. However, we are curious to see how well these augmentation methods fair with significant scene changes that were not present in the training set.
Winter Forest Dataset
Next, we evaluate the performance of select models only on winter forest images. As described above, many forest datasets, including our Common Scene Dataset, do not capture seasonal changes, such as forests in the winter. As a result, the expectation is that the Base Classifier, Simple Augmentation Classifier, and Diffaug Augmentation Classifier will not perform well on the winter forest images. However, the Single GAN Augmentation Classifier should, as it was augmented by using the swapping autoencoder with interpolated snow style textures. Below are the results.
Accuracy on Winter Forest Test Set
As expected, there was a drops in performance for the Base Classifier, Simple Augmnentation Classifier, and Differential Augmentation Classifier, with the performance of the Differential Augmentation Classifier dropping 15%. As well, the Single GAN Augmentation Classifier performed the best. Utilizing snow image textures to augment forest images was able to acheive a 95.6% accuracy, despite no winter forest images in the original training set. This demonstrates a succesful first proof of concept test that our method can be effective in improving classifier performance across datasets.
Uncommon Scene Dataset
Finally, we evaluate the performance of all models on our Uncommon Scene dataset. The Full GAN Augmentation Classifier is evaluated using both standard and gan-ensembled inference. Below are the results.
Accuracy on Uncommon Scene Test Set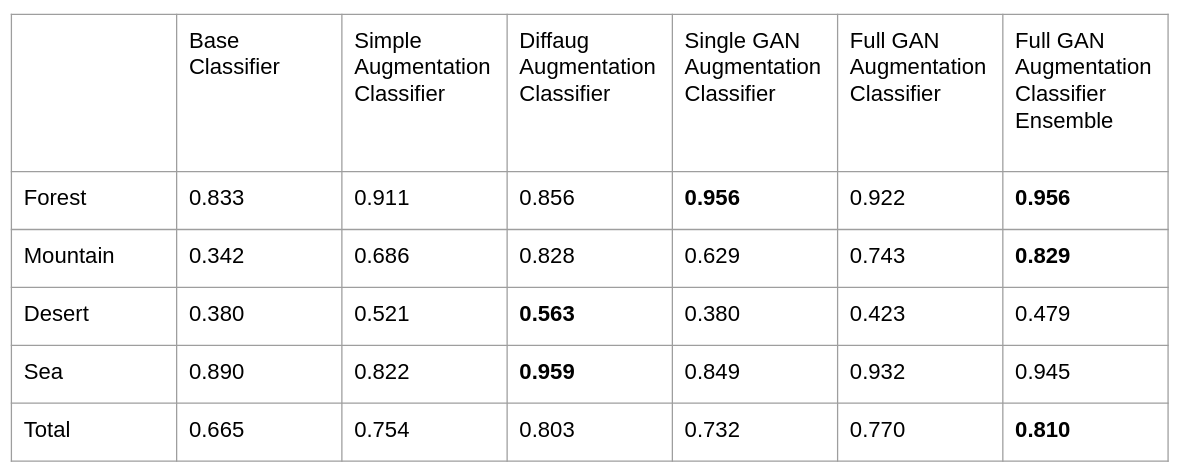
From the table, we see that using Full GAN Augmentation Classifier Ensemble showed better performance over the baseline classifier on all four classes. It showed the most improvement over the mountain class and least improvement over the desert class. We noticed that Diffaug Augmentation Classifier outperforms Full GAN Augmentation Classifier Ensemble in the desert class. After taking a closer look at the misclassified images, we noticed that most of the misclassified desert images were categorized as forest. Within these images, there are recognizable instances of branches of trees or cactus, which could be a salient feature for the forest class. One potential explanation is that an improvement on the forest classifier also lead to over-classifying images as forest class. From the improvement from the baseline classifier, we definitely see an improvement towards a more generalized classifier. One future step is to consider intra-class similarities and seek ways of tackling misclassification in that aspect.
Common Failure Cases
As demonstrated in our results, each network struggled the most with classifying desert images. This is because desert images in our dataset quite often had either mountains in the background or agriculture resulting in them being misclassified as mountains or forests. The next worse performing class was mountains. Again, this is because mountain images often have trees, resulting in them being classified as either forests. Below are a few example images which failed to be properly classified with each model.
Misclassified desert images:
Classified as mountain
 Classified as mountain
Classified as mountain Classified as forest
Classified as forest Classified as forest
Classified as forest
Misclassified mountain images:
Classified as forest
 Classified as forest
Classified as forest Classified as forest
Classified as forest Classified as forest
Classified as forest
As well, some failure cases are just a result of poor model performance. Below are common misclassifications from the all models.
Forest as Mountain
 Mountain as Forest
Mountain as Forest Sea as Desert
Sea as Desert Desert as Sea
Desert as Sea
Conclusion
In this work, we applied generative models towards augmenting data. Specifically, we would like to demonstrate that using GANs to augment data by altering coarse details will allow classifiers to better generalize and not overfit the training data. To do so, we manually collected two datasets: Common Scene Dataset and Uncommon Scene Dataset. Both of these dataset contains images from these four classes: forest, mountain, desert, and sea. The Common Scene Dataset contains images under more commonly seen environment, where the Uncommon Scene Dataset contain instances such as winter forest and night desert. To evaluate our results, we performed experiments on a baseline classifier, traditional augmentation classifier, and GAN augmented classifier. We noticed that GAN augmented classifier outperforms the baseline classifier on all classes, and also outperforms the traditional augmentation classifier on average. One challenge we noticed is that GAN augmented classifier suffers more from inter-class similarities. Overall, we demonstrated the potential to use generated images to assist classifiers to generalize across less common scenarios.
Images are Fun!
For this assignment we had to generate many gan-augmented images. We thought it would be fun to showcase what a few looked like. Not all are reallistic looking, which is a result of both using bad style images and using the prained swapping autencoder. But some do look pretty interesting.
Original Images:




Augmented Images (autumn, night, snow, sunset):















