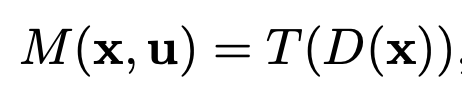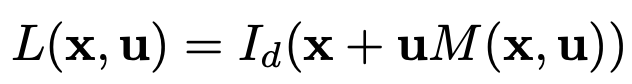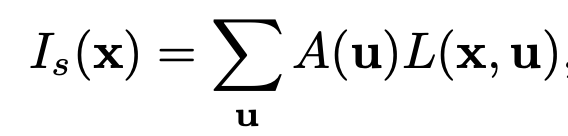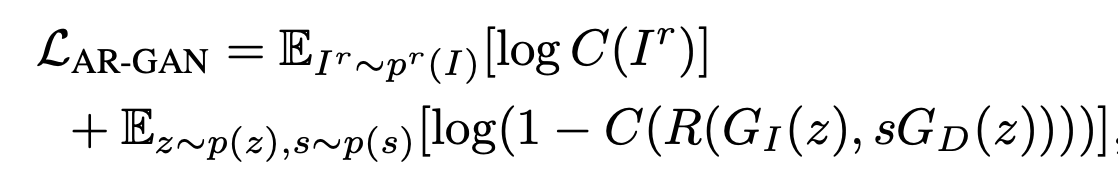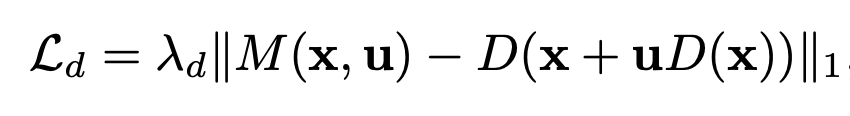**A Survey of Aperture Rendering with GANs and NeRF**
Emma Liu (emmaliu), Jason Xu (jiachenx), Joyce Zhang (yunyizha)
(#) Overview
(##) Introduction/Abstract
In our project, we survey three machine learning methods rendering shallow DOF images from deep DOF images: CycleGAN, NeRF, and ARGAN. We manipulated existing models to implement shallow DOF synthesis and implemented the aperture-renderer GAN (ARGAN) paper "Unsupervised Learning of Depth and Depth-of-Field Effect from Natural Images with Aperture Rendering Generative Adversarial Networks" from scratch to do this task end-to-end. In the end, we compare and analyze the advantages and disadvantages of each method.
(##) Background
In photography, depth-of-field (DoF) is the distance between the nearest and the farthest objects that are in focus in an image. A shallow depth of field, generated by a large aperture, is a desirable feature for many photos of objects and people, due to the beautiful blur in the background ("bokeh") that highlights and complements the subject. This effect is usually obtained by using large apertures, lightfield cameras, and more recently, also through computational photography techniques by fusing multiple camera outputs together.
Although technological developments have enabled shallow DoF photos on smaller sensors such as smartphones, the limitation that these photos have to be captured with a specialized camera system still remains, and changing the DoF after capture might be extremely difficult depending on the method of capture. Our project aims to tackle this limitation by finding a way to apply bokeh effects resulting from shallow DoF to any photo and enable easy adjustment of the amount of effect applied through GAN-based machine learning.
The three techniques we survey operate on different principles -- which will be elaborated in more detail in their own section -- here is a quick overview:
CycleGAN | NeRF based | ARGAN
-------|------|----------
Set-level Supervision | Image level supervision | Unsupervised
Easy to train | Difficult to train | ??
Synthesizes deepDOF -> shallowDOF | synthesizes lightfield of deepDOF -> composes shallowDOF | synthesizes lightfield of deepDOF -> composes shallowDOF
Easy to use | Difficult to use | ??
.
(##) Dataset
In our study, we use the [Oxford Flowers Dataset from the Visual Geometry Group](https://www.robots.ox.ac.uk/~vgg/data/flowers/). This data was chosen as it's an unlabeled dataset, and the assumption made by ARGAN, such as having center-focused foreground objects. Note that we did not use this data for NeRF-based approach, as NeRF models requires a long training process and beyond the scope of this project.
(#) CycleGAN
(##) Overview
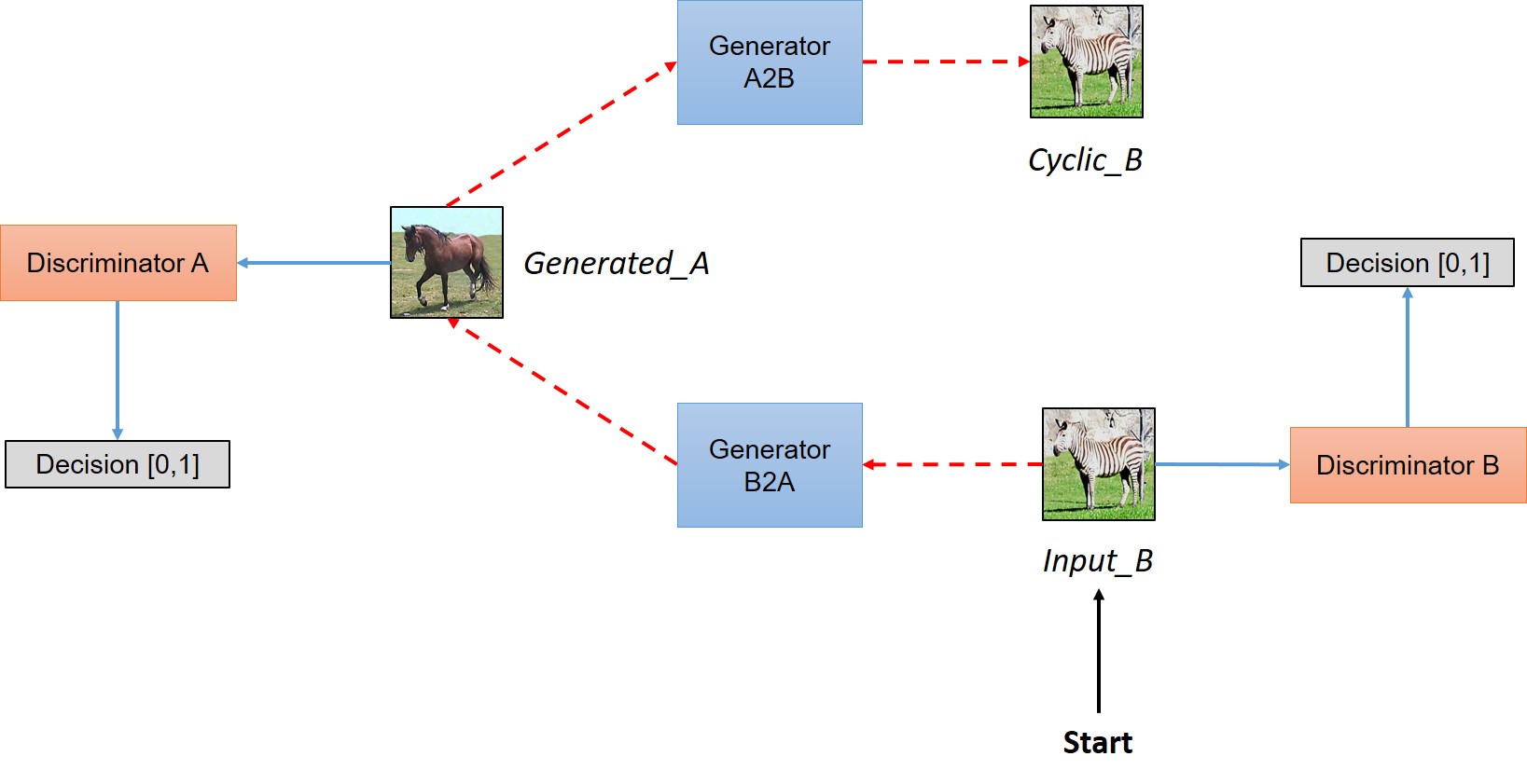
CycleGAN is a generative adversarial network (GAN) that allows for generates images from translate an image from a source domain X to a target domain Y in the absence of paired examples. The model consists of a generator G and a discriminator D, and maintains cycle consistency between X and Y.
image taken from official CycleGAN documentation
(##) Method & Results
In this project, we use the [Pytorch implementation of CycleGAN](https://github.com/junyanz/pytorch-CycleGAN-and-pix2pix) published by Dr. Jun-Yan Zhu. We also use the pre-trained model *iphone2dslr_flower* provided by the authors. The pretrained model goes from deep DOF images captured on iphones to shallow DOF images captured using a dlsr camera. We selected a set of flowers randomly from the dataset and run it through the model. The output is a generated image.
The generated models yield overall good results. Some parts of the image are blurred to simulate the bokeh effect, while foreground elements are kept in focus. From the randomly selected images, most of them were able to correctly identified the foreground element. The most visible artifact, from this method, is that results sometimes yield unnecessary color changes. It should also be noted that the shallow DOF image generated has a set DOF, that is, the user cannot adjust how much the image is blurred. This is because the model limited by the data it is trained on, and we would require several datasets to train the model if we wish to have different aperture sizes.
(#) NeRF
(##) Overview
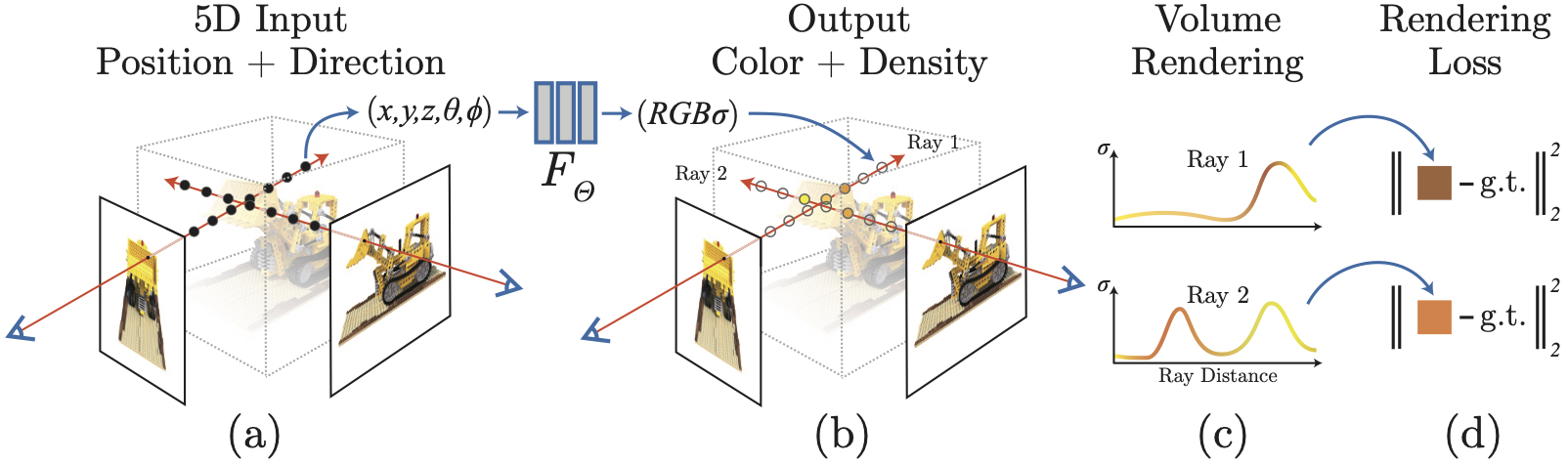
Neural radiance fields (NeRFs) are a state-of-the-art method for synthesizing a 3-dimensional view of an image from various captures at different angles by learning a function with 5-D inputs, $f(x, y, z, \theta, \phi)$, representing 3-D spatial coordinates in the image space and 2-D spherical coordinates representing view direction. Among the many uses for this learned function is simulating a lightfield grid, with which we can use to synthesize an image with shallow DoF.
(##) Lightfield from NeRF function
A lightfield image is captured by a camera system with lenslets in a rectangular grid, producing images offset from each other on the x-y plane (the plane parallel to the capture subject) by a set amount. Since NeRF functions are able to produce views from any position and viewing angle, we can simulate a lightfield capture by rendering the NeRF function repeatedly, using a grid of $x,y$ offset values simulating the position of each lenslet. Grouping all of these render results together yields an image array that can be processed with any lightfield processing algorithms, including the refocusing algorithm we discuss below.
(##) Refocusing with Lightfield Array
The lightfield refocusing algorithm relies on the fact that there exists many images of the same subject at slightly different viewpoints to render a new image by selecting images with an aperture, shifting each image, then averaging the images together to produce a new image. The idea is that by shifting every pixel in an image, we in reality shift farther elements of the image more and the closer elements less, due to the parallax effect. In addition, when averaging multiple images together, aligned pixels will be clear and unaligned pixels will be blurred. Additionally, we will see more intense blur and less areas in focus as we include more images in the averaging, due to more pixels being unaligned, and by a larger amount.
Using these intuitions, we can write the refocusing algorithm using the lightfield image array $L$, sub-image location on the lightfield grid $(u,v)$, pixel location on a sub-image $(s, t)$, pixel shift $d$, and the set of images included in the aperture, $A$, as: $$I(s, t, d) = \frac{1}{d} \int\int_{(u, v) \in A} L(u, v, s + d, t + d)\;du\;dv$$ where A is determined by sub-images within a specified radius from the center of the lightfield.
(##) Results and Discussion
We used a pre-optimized model of a fern provided by the authors of the NeRF paper in their codebase, generated a 5x5 lightfield to match AR-GAN's lightfield grid size, and generated a new image with the center of the fern in focus, as shown below.
Using this generated lightfield, we are also able to control the amount of blur and choose parts of the image in focus by changing our inputs of $d$ and $A$ into the refocusing algorithm.
Overall, we are greatly satisfied with the quality of the image that we obtained. The adjustability of the shallow DoF effect is also greatly beneficial. The only downside is that NeRFs take a significant amount of data and massive amounts of computing power to train, with every new capture requiring a new round of training, which makes generating shallow DoF images this way incredibly expensive and impractical. However, pre-trained models may use this pipeline easily and effectively.
(#) ARGAN
(##) Overview
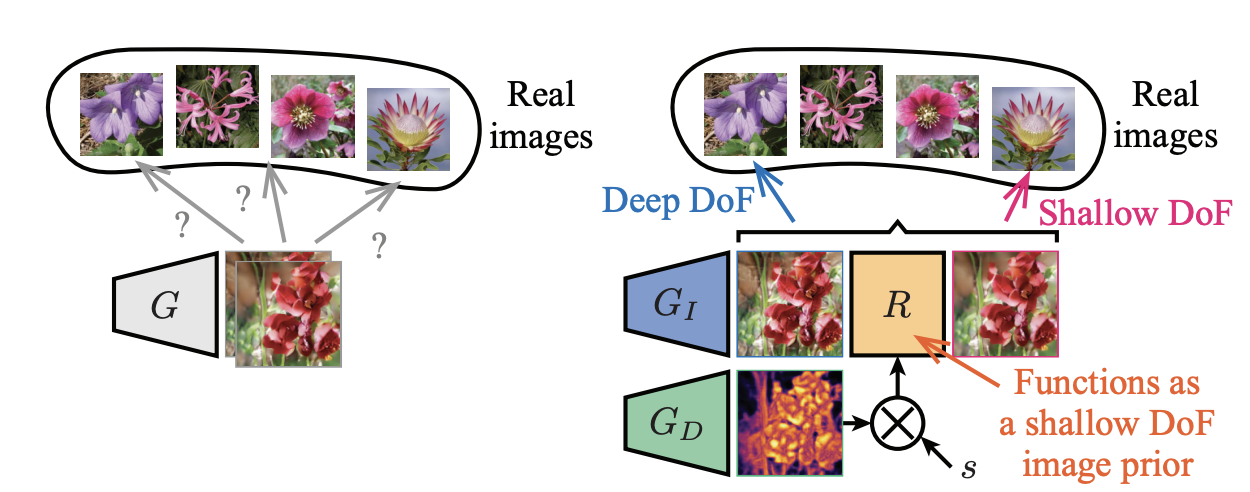
Unsupervised learning for this kind of task in the past have used viewpoint cues, which impose assumptions about the distribution of viewpoints of images. Alternatively, we can train GAN to directly learn the depth and DoF effect of natural images using focus cues, which will allow us to generate images with different DoFs.
(##) Pipeline
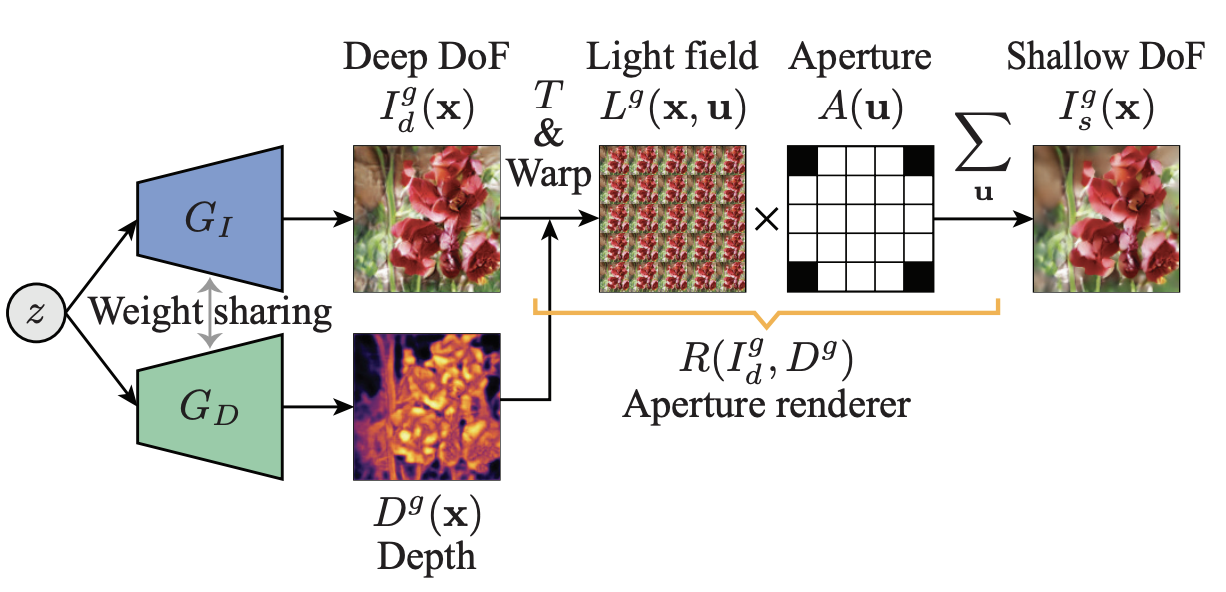
The general flow of the ARGAN pipeline is as follows (also depicted in the diagram above): given a deep DoF image $I_d(x)$ and $D(x)$ ($x$ refers to the 2D spatial image coordinates), render a shallow DoF image $I_s = R(I_d(x), D(x))$. We generate $I_d(x)$ and $D(x)$ using our GAN generator(s).
Instead of using the depth to warp $I_d(x)$ directly into a viewpoint view in the lightfield, which can cause visual holes, we will instead train another network $T$ that will learn this warped depth map distribution to produce a depth map for every view in the light field. For the sake of this project we assume we are operating with a 5x5 circular aperture, so we will have about 25 views of the light field.
We can then use this depth map per lightfield to index into the deep DoF image and generate a lightfield (warping an image for each view):
Finally, we can integrate over this lightfield in combinations with the 5x5 aperture mask to render a shallow DoF image. Lightfield rendering (integration) here amounts to summing up "shifted" lightfield images. This is key to our task; changing the DoF of an image can be done by shifting the focus (focal distance) and aperture size. The aperture controls what light rays can pass through the lense and hit the image. By summing over shifted images, we will effectively get an image that is more in-focus in one region (the center), and blurrier radially outwards; thus achieving a shallow DoF.
This integration step is $R$ depicted in the pipeline image above. It is implemented in the same manner as the renderer we used in the NeRF section, so we will not go into detail here.
(##) Learning Objectives
(###) DoF Mixture Learning
Since we want to learn the depth in tandem with the deep/shallow DoF images, we cannot just use loss only on the deep DoF image generator $G_I$. Instead, we use DoF mixture learning, where we compute the loss by applying the discriminator on the renderered shallow DoF image. In effect, we will be generating fake images with diverse DoF (a mixture of deep and shallow images) by manually adjusting the extent factor of the depth map. Thus the generator will be trained to represent the real image distribution which has varying DoF images. The image above depicts the difference between the standard GAN learning objective and our DoF mmixture learning objective. We can think of the aperture renderer, which functions as a mask over the incoming image light rays, as a shallow DoF prior.
So formally, to implement mixture learning, we simply change the way we calulate loss for the GAN as follows:
(###) Center Focus Prior
In images with a blurred blackground and shallow DoF, it is the most common case that the object in focus is in the center. This means that a depthmap of a shallow DoF image will most commonly have the smallest depth at the center, and gradually increasing depth towards the edges. For our project, this is true with our training data as well. Therefore, when training generation of the depth map, we implement a center focus prior so that the resulting depth map can have a realistic distribution of depth.
The center focus prior $D_p$ is a function defined by an in-focus radius threshold $r_{th}$ and a rate of depth increase $g$. We define the depth for all pixels within $r_{th}$ to be 0, and all pixels outside of $r_{th}$ to be increasing in depth at rate $g$, having depth $g \cdot (r_{th} - r)$. This prior can then be used to calculate a prior loss against a generated depth map, $\mathcal{L}_p=\lambda_p \|D^g-D_p\|^2_2$ , which becomes a weighted portion of the total generator loss.
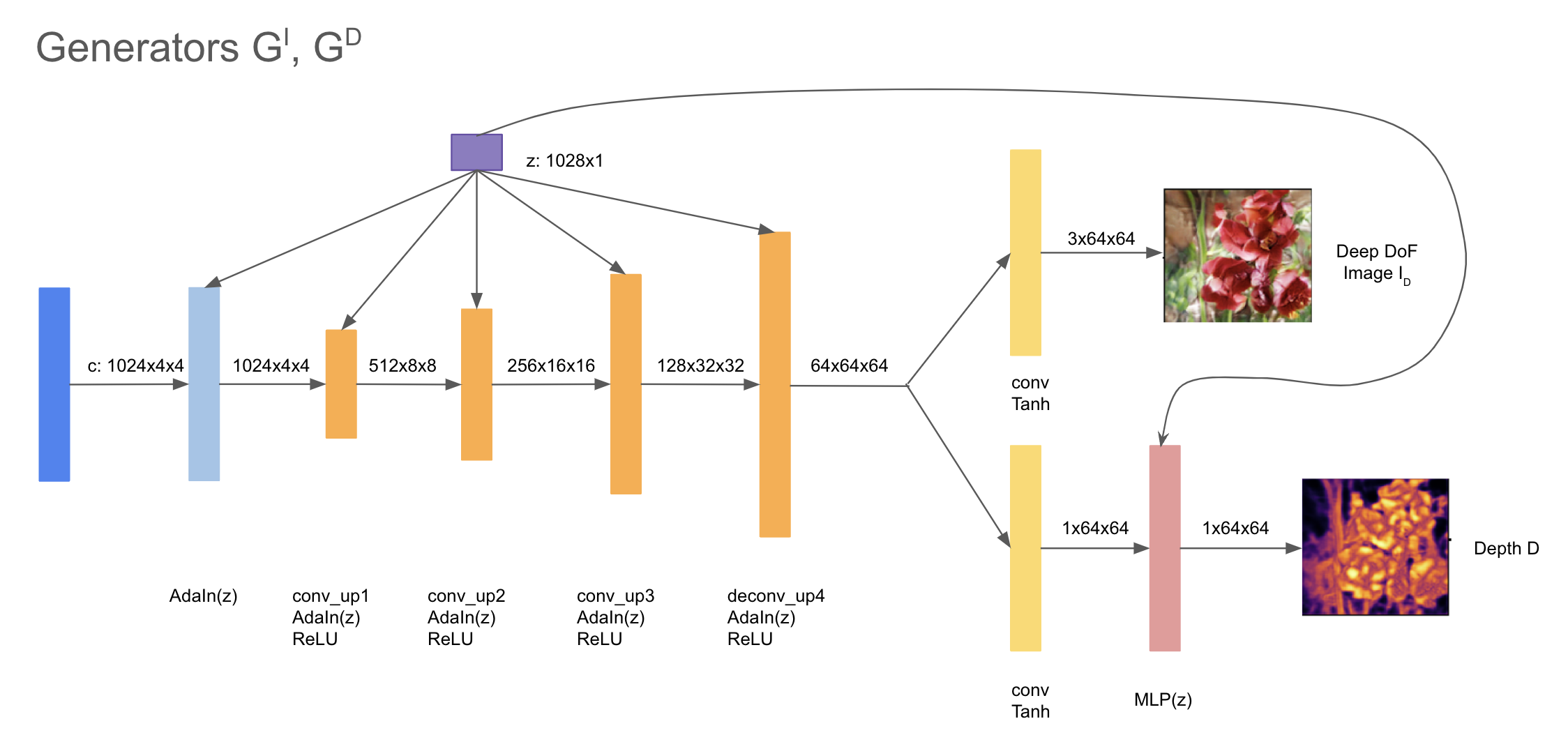
(##) Model Architecture
We modeled the architecture after the implementation details described by Kaneko. However, after experiencing a few ambiguities in his implementation notes, we modified a few details. Specificaly, we found that replacing $deconv$ layers shared between $G_I$ and $G_D$ with $up_conv$ layers, which we are more familiar with in GAN model generation thanks to HW3, produced more realistic-looking results.
(###) Generators
Given a random noise $z$, we first generate a deep DoF image $I_d^g(x)$ and corresponding depth $D_g(x)$ with two generators that share weights except for the last layer. We do this because the deep DoF image and depth image must reflect one another (i.e. exhibit a strong correlation). Effectively, we are learning a joint distribution between their domains.
Each of the initial shared layers has adaptive instance normalization (AdaIN), which tries to match the style feature's mean and variance. We pass in the latent vector z (random noise) as the same style feature for all these layers.
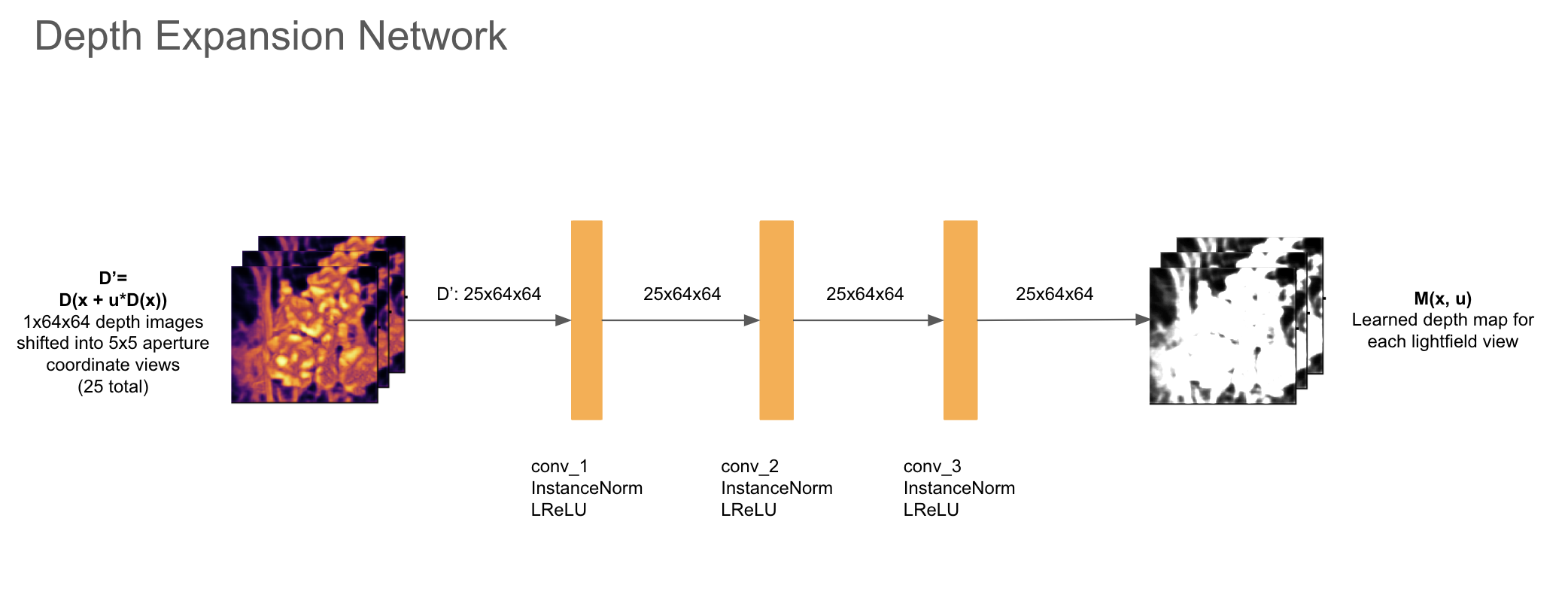
(###) Depth Training Networks
After the depth image is produced, the depth image is submitted to the neural network $T$ that is co-trained to expand $D(x)$ into a depth map $M(x,u)$ for each view in the light field. Note that in this notation, we are indexing into the depth map with a flattened 1D aperture coordinate $u$ (there are 25 channels in this depth map, one corresponding to each aperture coordinate $(u',v')$ and corresponding image coordinates $x$ (hence 64x64 image per channel). During each training loop iteration, we manually warp $D(x)$ into $D'(x,u) = D(x+uD(x))$ (creating shifted version of the depth map, indexing into the depth map image by shifting spatial x and aperture u coordinates by the depth in the image) and pass this into $T$ to get $M(x,u)$.
The architecture of this network $T$ is depicted in the diagram below. The image and channel dimensions remain constant here through each layer.
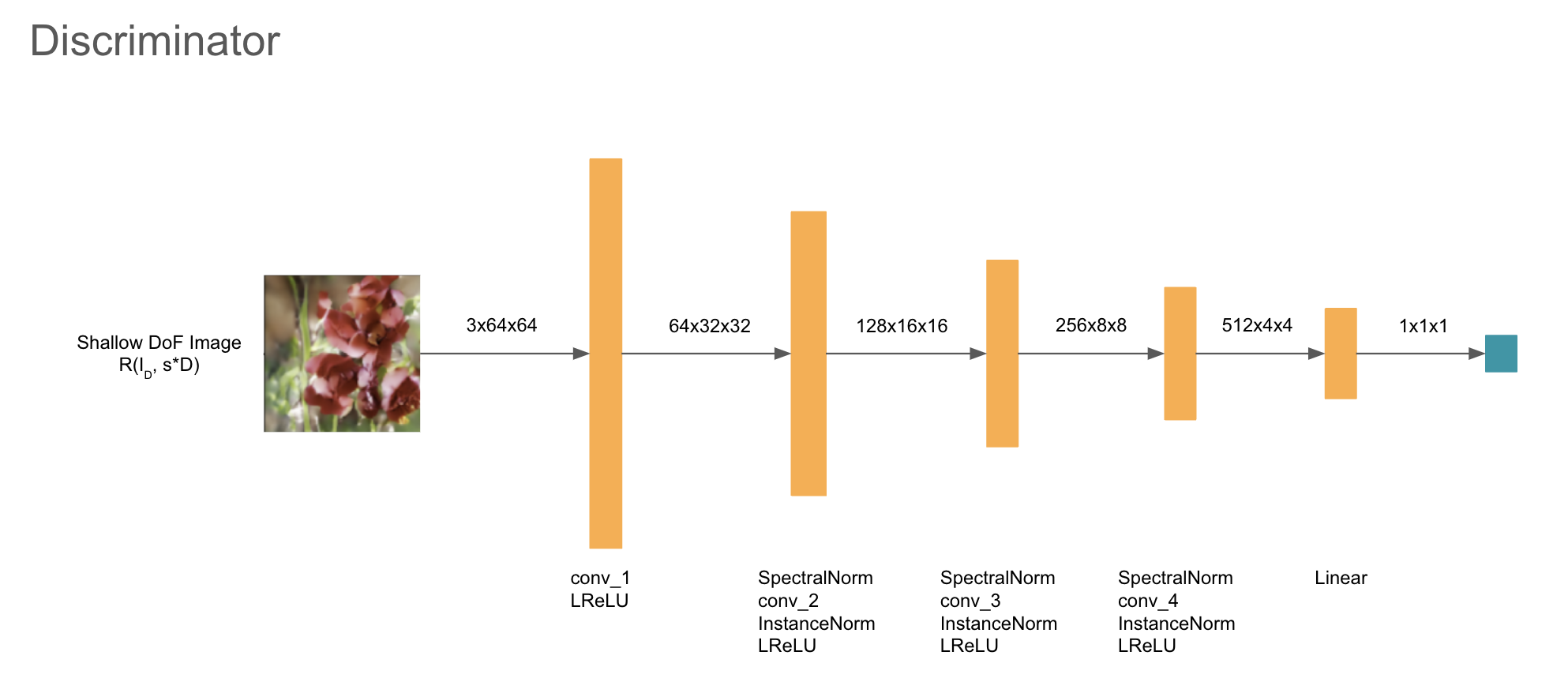
(###) Discriminator
The discriminator is applied on real images, as well as the rendered shallow DoF images rendered from the generated deep DoF image and its corresponding depth map.
(##) Training
We used the Adam optimizer with the standard learning rate and betas. We also apply differential augmentation suggested by the paper using the same operations of color jittering, translation, and random cutout, as was implemented in HW3. As before, our dataset is composed of 64x64 images. Random noise latents $c$ (Bx1024x4x4) and $z$ (128x1) were produced as needed.
The training loop follows the same standard style to train a GAN with non-saturing loss. We first train the discriminator (on real and fake images) and then the generator. To update the generator, we produce the deep DoF image $I_d$ and depth $D(x)$. Then as input to the network $T$ we first warp $D$; then we get $M$, which we can then use in our lightfield integration step to get $I_s$. The discriminator is applied to $I_s$ and the generator loss is computed.
At this point, we also contribute the center focus prior loss (explained above) as another form of loss (add it to the generator loss). We also regularize the depth expansion network so that the predicted depth map $M(x,u)$ approximates the manually warped $D(x)$. This is implemented by adding the following L1 regularization loss to the generator loss:
(##) Results
Results shown below after 5000 iterations of AR-GAN trained with DoF mixture learning, recommended parameters in the paper and the Oxford Flowers dataset, hand-picked for images with a central subject. We tried tuning a few hyperparameters without leading to any substantial differences.
Depth map produced by AR-GAN:
Generated deep DoF images by AR-GAN:
Shallow DoF images produced by AR-GAN's aperture renderer: