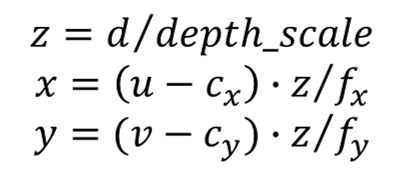
The project aims to evaluate the performance of deep neural network models in 3D point cloud reconstruction given different types of input. 3D point clouds are a popular representation to capture the geometry and motion of objects of interest from a scene in the physical world, due to its advantage of requiring less storage space for computer memory compared with other representations such as mesh and voxel. However, obtaining high fidelity 3D point cloud representation of objects in the physical world often requires costly sensors with high accuracy (e.g., lidars). To find solutions to mitigate this challenge, this project investigates whether/how much deep learning approaches can alleviate sensor data dependency in the task of 3D point cloud reconstruction from 2D imagery data. The particular task studied in this project is described as follows.
Given an RGB image which describes a vehicle driving scene (as seen from the driver’s perspective), this project uses deep neural network models to reconstruct 3D point clouds that represent the vehicles on the road. By using only the RGB image as input, we would like to simulate the scenario where the expensive lidar sensor in a vehicle detection system is replaced by a less expensive camera, and see whether/how the task of vehicle detection can still be fulfilled with the help of neural network models. Two different approaches were used to perform such task. In the first method, the point clouds are reconstructed from a depth map predicted by a state-of-the-art transformer model which takes the RGB images as input. In the second method, the point clouds are directly predicted by an auto-encoder model trained on Chamfer distance loss functions. More details about those two methods, along with their corresponding experimental results, are shown in the following parts of this report.
For a comparison, the following two neural network-based methods are used to reconstruct 3D points clouds.
Method 1 - Point Cloud Reconstruction Using Predicted Depth Map
Theoretically, the point clouds can be exactly reconstructed using a depth map as follows.
where are the coordinates of the point cloud, is the depth at pixel location , are the location of the camera center, and are the focal length parameters of the camera. Therefore, the task of point cloud reconstruction can be reduced to a problem of predicting the depth map given the RGB image. Following this strategy, a state-of-the-art depth prediction model, named the Dense Prediction Transformer [1] (DPT), is used in Method 1 to predict the depth map. DPT is a dense prediction architecture that is based on an encoder-decoder design that leverages a tansformer as the basic computational building block of the encoder. Unlike fully-convolutional networks, the vision transformer features a backbone module foregoes explicit downsampling operations and a global receptive field at every stage. Those properties are especially advantageous for dense prediction task such as depth map prediction.
Method 2 - Direct Point Cloud Reconstruction from RGB Image with Masks
To train the DPT model used in Method 1, the high-definition ground truth depth maps are needed. In practice, such ground truth data may be expensive to obtain since the data collection process could require high-performance sensors like a high-resolution lidar. A possible alternative to reduce the cost of data collection is to make a neural network model directly predict the point cloud representation of object of interest in the input scene. The sparser point cloud data (compared with depth map) can be obtained from low resolution range sensors which are more practical under budget constraints. In Method 2, the point cloud prediction model is chosen to be an autoencoder model which follows the architecture design in [2]. The encoder module is a Resnet-50 [3] model, and the decoder module is a multi-layer perceptron model. In addition to the RGB image, this autoencoder also takes as input a binary mask of foreground objects to aid the point cloud prediction. In practice, the binary masks could be generated by a deep learning model such as Mask-RCNN [4] a weighted combination of Chamfer distance and 2D reprojection loss are used in model training. The exact definition of the 2D reprojection loss can be found in [2].
Dataset and Data Preprocessing
The training data was created using the Virtual KITTI dataset [5], a photo-realistic synthetic video dataset of driving scenes. A dataset of vehicle pointclouds was created using the RGB images, the foreground masks and the depth images from the Virtual KITTI dataset, as shown in the following figure. The procedure to create the training data.
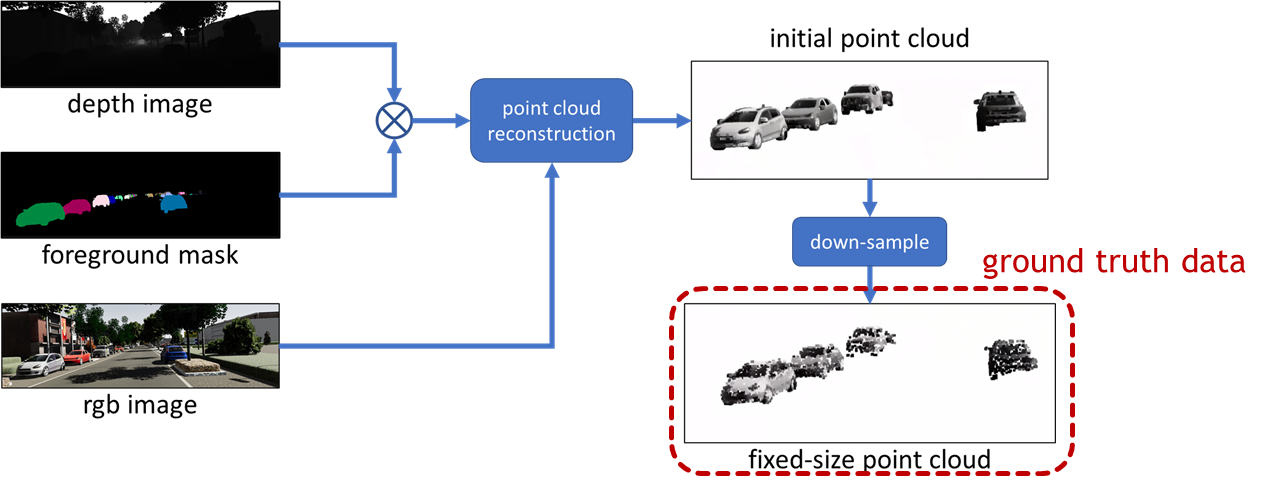
Figure 1. The procedure of creating the training dataset.
Experimental Results
The point cloud reconstruction result using Method 1 is shown in the following figure.

Figure 2. Point cloud reconstrution result using Method 1. (From left to right) The first column is the input RGB images, the second and third columns are the ground truth point cloud reconstruction result computed using the ground truth depth map (complete point cloud and vehicle point cloud, respectively), and the fourth column is the point cloud reconstruction result using the DPT model.
As shown in Figure 2, Method 1 accurately reconstruct the shape of the ground truth point clouds. One limitation of this method is that there is a scale difference between the predicted point clouds and the ground truth point cloud. This difference is possibly because there exists a bias on the camera intrinsic parameters of the images used to train the DPT model. To resolve this issue, a scale compensation function can be applied to the predicted point cloud in order to adjust its scale. Such compensation function can be a parametric function where the parameter values are optimized by minimizing the scale difference between the ground truth and the predicted point clouds.
Unfortunately, up til the last day before the project due date, I couldn't use the proposed autoencoder model for Method 2 to generate an adequate point cloud reconstruction result. A sample of the generated point clouds are shown in the following figure.

Figure 3. Point cloud reconstrution result using Method 2. The left column is the ground truth point cloud reconstruction result.
The right column is the point cloud reconstruction result using the autoencoder model.
0.250579 to 0.027727, and the 2D reprojection loss has also reduced from 0.0022660377 to 0.0021253091 (scale with respect to the Chamfer distance). Should there be more time, two approaches would be tried out to improve the results. 1. Change the model architecture. Despite that the same autoencoder architecture has been used to successfully recosntruct point clouds from a single RGB image on the rendered image of the ShapeNet dataset and the Pixel3D dataset, as reported by [2], the ResNet-50 model may not be an ideal choice for image encoding. The original size of the input RGB image from KITTI dataset is (H: 375, W: 1242). Before sent to the encoder, the RGB image was reshaped to (H: 224, W: 224) in order to accomodate to the ResNet-50. Such large change of image shape might affect the quality of image encoding. Therefore, an updated network architecture that can directly process the RGB image in its original size might be needed to improve the results. 2. Change the loss function. The descrepancy between descreasing training loss and unimproved prediction quality might indicate that the current loss function is not adequate to evaluate the shape difference between the generated point clouds and the ground truth point cloud. Hence, a Generative Adversarial Network (GAN) loss might be needed to better evaluate the shape difference. To implement the GAN loss, a discriminator based on the PointNet [6] model could be considered.
In this project, the problem of reconstructing point clouds from a single image is studied. Two different methods, namely the depth map prediction method and the direct point cloud prediction method, were tried to solve the problem. Experimental results show that the first method is capable of generating the desired point cloud shape despite a small scaling error, while the second method did not yield a successful outcome and requires more improvement to achieve the goal. In some sense, it is expected that using the second method would encounter more challenge than using the first one, since the mapping from the image domain to the point cloud domain requires the neural network model to be order-invariant for the point sets. Nevertheless, using the second method has the potential advantage of relaxing the requirement on high-definition ground truth depth maps for model training. Therefore, I think it is worth further study in the future.
[1] Ranftl, René, Alexey Bochkovskiy, and Vladlen Koltun. "Vision transformers for dense prediction." In Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 12179-12188. 2021.
[2] Zou, Chuhang, and Derek Hoiem. "Silhouette guided point cloud reconstruction beyond occlusion." In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pp. 41-50. 2020.
[3] He, Kaiming, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. "Deep residual learning for image recognition." In Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 770-778. 2016.
[4] He, Kaiming, Georgia Gkioxari, Piotr Dollár, and Ross Girshick. "Mask r-cnn." In Proceedings of the IEEE international conference on computer vision, pp. 2961-2969. 2017.
[5] Gaidon, Adrien, Qiao Wang, Yohann Cabon, and Eleonora Vig. "Virtual worlds as proxy for multi-object tracking analysis." In Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 4340-4349. 2016.
[6] Qi, Charles R., Hao Su, Kaichun Mo, and Leonidas J. Guibas. "Pointnet: Deep learning on point sets for 3d classification and segmentation." In Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 652-660. 2017.