Return to the lecture notes index
Lecture 6 (January 27, 2011)
Hard Drives
Hard drives do the bulk of the heavy lifting in data storage. One day soon,
they may be replaced by a solid state solution. And, I do believe that.
But, I've also been hearing that my entire adult life. And, well, so have
people older than me. We're getting there...but hard drives are still
the top of the game when we need volume, speed, and persistence over time.
Hard drives are also the most repairable and recoverable of the storage
systems we've discussed. The only trick is that data recovery specialists
can do a dramatically better job than forensics specialists. Having them
repair a hard drive is expensive -- but not against the cost of any type
of significant legal exposure. Typically repair or recovery costs range from
about $650 - $3,000, with most repairs probably in the lower half of that
range. Data recovery is a booming industry.
How Hard Drives Work, An Overview
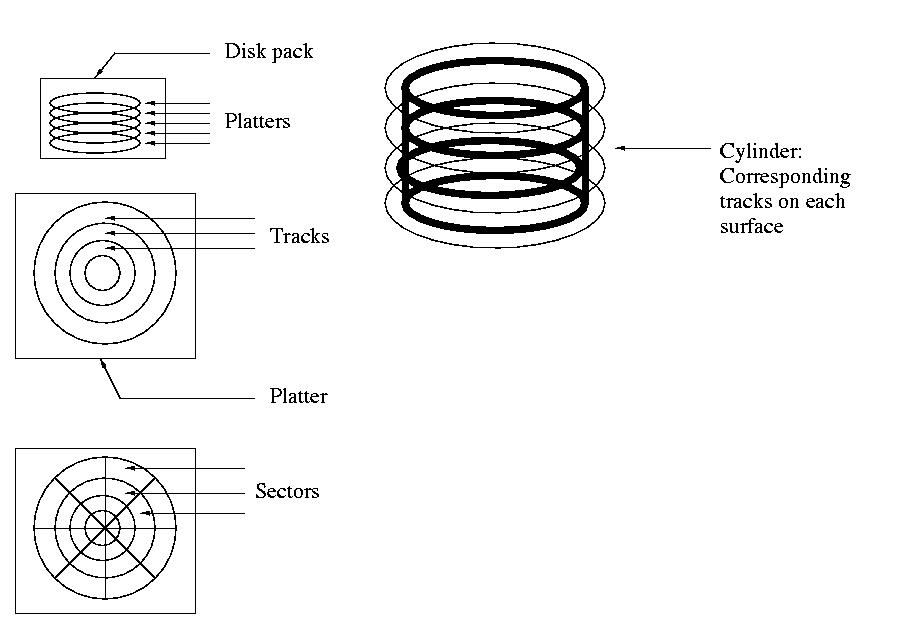
Hard drives are stacks of two-sided disks called platters. The disks
rotate at a constant rate of anywhere between 3600 RPM and 10,000 RPM.
Unlike CLV CDs, the rate of rotation for hard drives is constant. They are
said to be Constant Angular Velocity (CAV). This leads to an
organization of tracks that are concentric circles, rather than a single
spiral.
Instead of with pits and lands, the bits are encoded using magnetic polarity.
For the moment, you can imagine a north pole facing upward as a 1-bit and
a S-pole facing upward as a 0-bit. But, in reality, as was the case with
CDs, it gets more complex than that. A head is positioned
over a track and senses the flux resulting from the transition of a
north pole to a south pole or vice versa. This small electrical signal
is amplified, cleaned up, and interpreted to result in a the stream of 0s
and 1s that represent the data. Because coils of wire can sense changes
in magnetic fields, not constant magnetic fields, the bits are modulated,
similar to the way they with EFM. In this case, it is the transition from
a north to a south, or vice-versa, that carries the information. And,
as with CDs, the encoding schemes are designed to force transitions.
Modern hard drives use variants of a scheme called Run-Length Limited
(RLL) encoding.
The heads are actually stacked, so that there is one head for each surface,
or side, of each platter. For reasons of simplicity, cost, and efficiency,
the heads are not independent, they move together. Specifically, they
seek from track to track by moving in and out on the drive.
Technically speaking, they pivot in and out on an arc, rather than moving
straight in and out. But, you'll see that for yourself soon enough.
As was the case with CDs, and is the case for most any other storage
device or communiction system, disks aren't organized as endless streams
of bits. They need to have small, manageable parts so that they can be
easily addressed, and so that the data can easily be found, edited, and
checked for errors. Sectors, themselves, vary in size, with the smallest
at the inside, where the circumference is small, to the largest at the
outside, where the circumference is large. And, depending on one's
perspective, an outside track might be viewed as too large for convenient
management. So, these tracks are broken down into sectors.
In addition to the data, itself, sectors contain meta data, not dissimilar
with what we saw on CDs. This includes the sector number, synchronization
fields, ECCs, and status bits. A status bit might indicate if the
sector is in use or defective.
There are small gaps between the sectors. These, of course, allow
for tolerances, but they also allow for one sector to be processed
by the electronics, before the next one shows up. There is a similar
gap between tracks, also to allow for tolerances.
In the end, hard drives are much better at random access than are CDs.
The delay as they wait for a sector to fly by from another place
on the track is relatively small, because the disks are spinning quickly.
And, although seeking is tiem consuming, it is far better than the guessing
game spent to stabilize within a single CLV track.
A Historical Model of Sectors, Tracks, and Cylinders
Back in "The Day", when things were simple, it was easy to sketch
pictures of the organization of the data on a hard drive. The
picture below shows the old school organization, where each surface
contains concentric circle tracks. And, because the disk spins
at a constant rotational velocity, there are an equal number of them
on the inside and the outside. The bit-density is higher on the inside
and lower on the outside. But, since the bits pass under the heads at
the same rate, the electronics didn't know that, as they timed it out.
Beyond this, since the heads moved together, they moved across corresponding
tracks on each surface. There was a negligible delay to switch from one
head to another. As a result, data was often written from head-to-head,
then sector-to-sector. And, only then would the head move for a seek.
It is important to note that moving the heads was not, in the early days,
nor is it now, a fast thing to do. The head needs to be pushed past
the moment of inertia, speed up, coast, stop, and become stable. As it
stops, it oscillates. So, waiting for it to become stable, basically means
waiting for this to dampen out, and tuning it, if necessary. Reading takes
less stability than writing, because some error can be managed without
degrading future access. But, writes need tighter tolerances, to ensure
future reads will be doable.
The basic picture, in the old days, looked like this:
Modern Disks
In the early days of disk storage, the electronics were the limiting
factor. We could store bits as quickly as we could clock them flying
by. This meant that there was no loss in having a lower bit density
on the outside than on the inside, since the speed, not the density,
was the enemy.
Over time, disk heads, and especially the electronics for signal processing,
got dramatically better. We were now able to clock data flying by faster than
we could squeeze the bits together, at least on the inside of the disk. As
a result, it became inefficient to lose storage by keeping the same number
and size of bits on the inside and outside.
One can't make a flat, circular disk where all of the tracks are the same
size and store bits linearly. Varying the size of the sector is impractical,
because less-than-maximum size sectors would waste space in hardware and
system buffers, never mind force a lot of physical knowledge to organize
simple reads and writes.
So, modern disks vary what they can -- the number of sectors per track.
Outer tracks have more sectors than inner tracks. The adjacent group
of sectors that has the same number of tracks is called a zone.
So, we say that the surface is divided into zones, each of which have
the same number of sectors per track.
So, we now have a picture that looks like this:
Source: http://www.pcguide.com"

|
Because, in the push for increased capacity, tolerances have gotten smaller,
there is a delay associated with switching from one head to the next. It
is smaller than a seek delay, because head movement is usually not needed.
But, it does take time to tune the electronics to the signal from a
different head.
Rather than forming a cylinder for corresponding sectors, it is actually
formed as more of a spiral, with a skew from one platter to the next. This
allows the head time to get tuned to the track on the next surface, before
the logically sequential sector comes under the head. For example,
surfaces might be stacked as follows:
Source: http://www.pcguide.com"
 |
 |
Disks and Latency
Historically, disks are said to encounter three types of latency,
in order of significance:
- Seek: The time it takes to start the head moving, get it going,
slow it down, and let it settle into a single track.
- Rotational: The time it takes to wait for the disk, spinning at
a constant speed, to spin around to position the desired data
under the head for reading
- Transfer: The time it takes to read all desired adjacent sectors
on a track, once the first sector is under the head
In modern drives, things get somewhat more complex:
- Seek: The time it takes to start the head moving, get it going,
slow it down, and let it settle into a single track.
A very short seek might take 0.7mS to 2mS, whereas a "full stroke"
seek from inside to outside might take 10mS. An "average" seek
is said to typically be about 1/3 of a full seek, or about 3mS.
(The numbers vary, --a lot-- with the drive).
The reason for this is that sort moves encounter a lot of overhead
to break the moment of intertia and to stabalize the head. This
is amortized over larger moves. But, beyond that, since a head is
never perfectly still, sometimes it is possible to "settle" into
a nearby sector, without encountering the full overhead of even
a short seek. This is done through tuning the electronics to filter
the signal, and by a "bump-like movement" of the heads.
- Head switch delay: The time it takes to switch heads, to go
from paying attention to one surface to another.
Although on older drives, this wasn't an issue. With newer drives,
the tolerances are tight. Reading a track involves not only positioning
the heads "well enough", but also tuning the signal processing to
the signal that is actually being received, which will vary, even
within the tolerances that allow for the track to be read.
In general, a head switch delay is no greater than the track-to-track
seek time, and can be shorter. Depending on the drive times of
0.7mS to 1mS might be typical. As we discussed earlier, the penalty
of a head switch is partially hidden by skewing the tracks from
one surface to the next, to avoid paying both the head-switch delay
and a rotational delay for missing the next logical sector due to it.
- Rotational: The time it takes to wait for the disk, spinning at
a constant speed, to spin around to position the desired data
under the head for reading (Nothing strange here).
This is a function of the drives rotation. A full rotation, to
the sector before the one just read takes 1/DRIVE_RPM. For example,
a full rotational delay on a 3600RPM drive is 1/(3600/60 sec/min) =
16.7mS. On a 7200RPM drive, it is half this, 8.33mS. And, on a
high-performance 10,000RPM drive, it is 1/(10,000RM/60 sec/min) =
6mS. An average rotational delay is, as you might expect, half
a spin, or half of this maximum rotational delay.
- Transfer: The time it takes to read all desired adjacent sectors
on a track, once the first sector is under the head
- Effect of Buffering: Hard drives are heavily buffered, e.g. internally
cached. They can hold whole tracks in cache. And, some of their
buffers are write-back, rather than write-through. This means that
the only copy of the data is kept in volatile storage. But, to
mitigate this, these drives actually have the capacity to do the
write back as the drive spins down, despite the decreasing speed.
Obviously, only a relatively small buffer space can be managed this
way. But, by buffering whole tracks, much rotational delay can be
relieved in light of the way many applications "Keep coming back for
more". Buffering policies can be quite sophisticated.
Logical vs. Physical Geometry
Back in "The Day", drive manufacturers used to tell use the actual
number of surfaces, tracks per surface, and sectors per track. This
information could then be used by operating systems to tune disk
access.
These days, the actual configuration of the drive is too complicated,
e.g. zones, and proprietary. Instead, drives hide their actual
geometry and we can basically pretend that they have any logical
geometry that adds up to the capacity of the drive.
This, of course, means that the system software's assumptions about
the adjacency of sectors might be incorrect. But, in general, the
logical sectors are ordered in the same way as the physical sectors.
So, even if the system software can't predict exactly when a seek
might occur, nearby sectors remain, in the average case, much
faster to "seek" to than more distant logical sectors.
Pictures From Class
In class we looked at the inside of a disk, specifically the Seagate
Medalist 3221 (ST33221A) that you'll attempt to rebuild for the lab.
It is an old, circa 1993, 3.2G drive. But today's standards, it is
junk. But, back in the day, it had top specs: 5400 RPM, 11.5ms average
access time, 3.23GB (not TB).
Here are a few photos:
top/bottom (top, left and right, respectively) and side (bottom) views
 |
 |
 |
SMART Hard Drives
Manufacturers have included a bunch of monitoring within hard drives.
Drives with this capablility are said to have Self-Monitoring,
Analysis, and Reporting (SMART)technology. Although this monitoring
might be able to predict some failures, this should not be viewed as its
primary purpose. Instead it collects information that, in the event
the drive fails and is returned to the manufacturer, can be used by the
manufacturer to better understand field conditions and drive failure.
The reality is that most hard drive failures are not predicted by SMART
drives, and some SMART warnings may be innocuous (but don't bet on it).
Google has had ample opportunity to study hard drive failure, and the
information colelcted and reported by SMART drives. They found a few
strong indicators, but not many. They published a paper on the topic in 2007.
Wikipedia has a a good article on SMART drives. The only thing to which I want to call
your attention is that SMART stats always count down from 255. So, for
example, for reallocations 254 is a better number than 6.
But, for forensics professionals, here's the important thing. If you
weren't able to read sectors, that's obviously a problem. If you were, it
doesn't matter what SMART data the drive reports. Errors are squelched by
the ECCs. Don't let other experts hide behind these errors. The litmus
test is reading the data -- not SMART chatter.
Bad Sector Relocation
Hard drives are not perfect. They have bad sectors leaving the factory.
And, they can accumulate (or discover) bad sectors over time. In order
to make things easier for the operating system, disks hide these errors.
They do this by having a chunk of spare sectors that aren't normally
addressable. Bad sectors are reallocated to use these "spares".
The user asks for the same "physical sector", which we really know
is actually a logical sector, and instead gets its replacement.
This is achieved through the use of relocation lists, known as the
P-List and the G-List or the defect tables. The
P-ermanant list contains the defects mapped at the factory. The G-rowth
list contains bad sectors mapped after the fact, either by the controller's
firmware, or by disk repair utilities.
It is interesting to note that the controller only remaps bad sectors
upon write -- not upon read. Upon read it only notes that they are bad.
This is because nothing it to be gained by remapping a sector that can't
be read as there is no data to move -- and it could destroy data that
recovery software might be able to tease out later, and, at the least, is
a waste of time. Instead, these are known as pending sectors
or pending relocations. SMART attributes can tell you the number
of items on the G-List and the number pending, specialized software can
let you see and edit the G-List. And, can let you access the mapped-bad
sectors for forensic purposes.
Firmware
What many people don't realize is that a disk controllers firmware is
not entirely on the controller board. Instead, much, if not most, of it
is actually on a chunk of the disk that is not accessible by normal
means. The firmware on the controller gets things going -- and then
loads the rest from the disk. This reduces cost and increases agility
for the manufacturer. But, it also increases complexity for the user
in the event of a failure.
Problems that seem like electronics problems might actually not be
on the board, but instead on the on-disk firmware. There are usually
two copies of it on disk. But, none-the-less, it can be damaged by
all of the usual stuff, e.g. power failure or head crash while running,
drive wear, alpha-beta-gamma-omega-purple-rays.
This arrangement adds complexity to replacing the controller board,
because it means that the board must match not only the disk version,
but also the firmware version. For most of us that don't have the equipment
to coerce the drive to give us an image of its firmware, or to accept a
new image, this means boards need to be an "exact" firmware version and
model match to stand a good chance of working.
Prospects for Repair or Recovery
With hard drives, regardless of the failure mode, it is almost always
possible for a professional data recovery firm to recover significant
amounts of data. And, beyond the ridiculous, e.g, smashed with a
sledgehammer, data recovery is usually good, even from significant
failures.
Do-it-yourself repairs sometimes work -- but can also make things worse.
The four biggest reasons, beyond the need for great care, in no
particular order, are
- the dramatic damage that can be cause by contamination of the
disk area with dust
- the inability, without special equipment, to access the firmware area
of the disk
- The need for very detailed drive infromation from the manufacturer,
or by reverse engineering (or simply bit stealing), such as the
correct firmware to copy onto the disk, or whcih board and drive
versions are compatible
- The tremendous benefit of specialized tools, such as head rakes
and platter jigs.
So, if you are in the forensics business, and you are attempting data
recovery on a hard drive without all of the above, plus a track record of
experience, you might well be doing your clients a great disservice.
Unlike other media, where it is either (a) fairly straight-forward for
those with the skill, or (b) really challenging for anyone -- hard
drives are cost-effectively recoveredor repaired by professionals.
I repair and recover my own drives, because I have the data backed up
elsewhere -- getting it off the drive is a convenience. I might do it
for a client, but only if somehow time or expense or data sensitive make
no other solution a good possibility.
For the most part, the role of the forensics professional is to
educate the client about the condition of the drive, and educate the
client about data recovery services, and possibly helping to procure
those services.
Symptoms, Types of Failure, Firmware
Ask the Right Questions
Find out the circumstances of the drive's failure, or the discovery of
the failure. If it was dropped while off, it might have bent a spindle
or broken a head -- not likely to damage the platters. If it was
dropped while running, there is more likely to be media damage. Did it
get bounced at boot? When it might have been reading firmware? Or,
was did it die during a lighting storm that might have damaged the
controller? Was it powered down for years that might have allowed
bearings to dry out and seize? Or did it dlow down and slow down, until
it finally quit working, after years of service?
External and laptop hard drives tend to suffer the most drops. External
drives tend to be internal drives in an enclosure. If you get a 2.5"
disk, did it come from a laptop (probably)? If you get a 3.5" disk, was
it from a desktop or server system? Or a portable enclosure?
Check the Cabling. Check the Cabling. Check the Cabling Again (And, do the same for the lab equipment)
If a drive isn't cabled and/or jumped and/or terminated correctly, all sorts
of things might happen. It might not spin up. Lights might stay on
or not come on. It might spin up but not be detected. On older drives,
if improperly terminated, it might even run unreliably.
Always check, recheck, and triple check all of the cabling, including
replacing all of the cables with brand new ones -- not the beat up
old ones from your toolbox -- before getting too deeply into any
problem that isn't obviously something else. This applies to power
cables, data cables, jumpers, and terminators.
Also, try another drive, of the same general type, in the same situation.
Lab equipment does sometimes fail. Interfaces get burned up. Pins get bent.
It might have even happened as you were strinking after last case. Make
sure the subject drive is, in fact, bad, rather than some aspect of
the lab equipment or lab environment.
Do Your Homework Before Reading Any Further (Or At Least Using What You've Read)
Every drive model is different. Every drive model has different common
failure modes. Every drive model presents failure different. Check the
Web and with the manufacturer to find out what are common problems and
presentations for the subject drive model. Consult experts about the
specific model.
What comes below are just broad generalizations based on my experience
and research. They might or might not be accurate overall, or in any
specific case.
Suddenly Not Recognized by BIOS
If a drive is suddenly not recognized by BIOS, it probably has
either a bad controller board or corrupted firmaware. Look at the board.
Are there obvious signs of failure? Burn marks? Holes in ICs? Burning
smell? These point to a controller board failure.
Otherwise, if is the controller board, it might be meidated by heat.
Many electrical failures resulting from electronic wear will appear to go
away if the device is cooled. Check the drives specifications. It probably
shows an operating tempurature range that includes near-freezing
tempuratures. Set a refrigerator for its minimum operating tempurature,
use a dessicant to get rid of extra moisture, and then let the drive
cool in the refridge. Then, run a cable out, and try to get the data
off. If it works, it is a win. If not, nothing lost -- the drive has
always been maintained within spec, so no harm done. Some people
report using freezers, depending on the drive, this might be too cold.
If it gets the electronics going, it might still lead to read problems,
because of platter contraction and other dynamics, etc. This should
only be done as a "Hail mary".
If a "close" match controller board can be found, it might be worth
attempting the replacement. A "close match" matches the model and the
firmware version, and has a "close" date of manufacture. What is "close
date"? Honestly, I dunno'. Some say 2-3 months. I've certainly had success
with replacements with more separation than that.
When I do this, in order to minimize the risk, I usually try a reverse
replacement first. I first check function on the donor drive. Then, I swap
boards. If the donor drive still works, the problem is most likely
firmware. If paying for a professional is an option -- it is pretty
clear one is needed. If not, powering up the orgininal drive won't
likely work, but why not? If the donor drive doesn't work, I assume
I've isolated the abd part and give it a try.
If the original drive still doesn't work, either (a) the boards were not
a good match, or (b) there was both a firmware and board failure, which is
unlikely. If (a) was the case, I really should ahve been more careful about
finding a donor, I could have damaged the disk, even the on-disk firmware.
But, this is unlikely, so I try again -- this time being even more careful.
Incorrectly Recognized by BIOS
This could be a controller failure. But, it is most likely a firmware
failure. It is probably getting the drive family from the board, but
not paramaterizing it correctly with details. This really is a job for
the professionals. Anything here is just playing around, which could be
destructive. But, if you want to try a board replacement, and are very
conservative, the risk is low, and it could be a board failure.
Of course, do open your eyes and your nose. If the board is obviously bad,
then, well, see above.
Slowing, Read/Write Errors, Incrasing Relocation/Pending Counts
Get the data off -- fast. Immediately image the hard drive. These problems
are usually the result of aging of the mechanics or magnetic data. They
tend to be recoverable, but not fixable.
There is software that might be able to rejuvenate the drive. It basically
does a bunch of raw reads, ignoring ECCs, obtains statistical certainty,
if it can, and rewrites the secotr, more than once if needed. This type of
software can sometimes temporarily reduce or eliminate the symptoms. But,
it doesn't fix the root problem, probably aging. And, forensics people
tend to steer clear, at least before an initial imaging, because it
is a destructive procedure (recall our earlier conversation about these).
None-the-less, these are good options.
Repeated Clicking, Knocking, or Thrashing Sound (And can't get data)
A repeated clicking sound is usually the sound of the drive seeking for
a sector that it cannot find. This most often happens at boot, when the
drive needs to find its firmware. It is usually the result of bad heads.
But, it can actually be the result of bad firmware. If both copies are
corrupt, many drive will keep trying -- what else to do?
Griding or Siren Sound (Obviously, can't get data)
This is often caused by stuck platters. There are three common reasons for
this. One reasons is that the spindle motor is bad. Another reason
is that the heads didn't retract, seized to the platter, and are preventing
it from spinning up. The last common reason is that bearings have failed,
generating too much resistance for the drive to spin up.
Repairing this problem involves removing the platters and reinstalling them
after it has been corrected or into a donor drive. This involves a cleanroom
and the ability to maintain the exact alignment of the platters during the
surgery. The jigs to do this are expensive. And, well, don't forget the
cleanroom bit. Resolving this is certainly a job for the professionals.
Having said that, if you aren't willing to pay a dime, you can try a "Hail
Mary". Disconnect the drive. Hold it 6" above a solid surface, board down.
Slam it straight into the surface. See if it works. Repeat until it does,
or until you feel better. There is a very small chance it will release a
stuck bearing or let a stuck head retract. There is a greater chance it'll
break things worse.
Unstead spinning sound (And can't get data)
This is probably a spindle or spindle-head problem, as described above.
It is just that, instead of being totally stuck, it can't get up
to speed and steady. It might be stopping and starting due to software
attempts to reset or hardware current limits.
Drive won't spin up
Check for power. Check for power again. Check for power again.
Then check for BIOS recognition. If it recognizes the model, it
demonstrates that the controller is getting power, at the least.
If not, it might be a bad controller board. You could try replacing
the controller, regardless. The power gets to the drive via the board.
See the discussion about replacing a controller.
It isn't going to be a firmware problem, because the drive has to spin
up to get to the firmware. At least firmware isn't the only problem.
It could also be stuck platters. See that discussion.
Rumbling or squeeking sound while drive runs
If the drive is producing data, this is most often worn bearings.
I'd recommend getting the data quickly. But, most of the time bearings
fail very slowly, especially if it is an older drive. Newer drives
shouldn't make bad sounds, so it might be more serious.
If the drive isn't producing data, but otherwise is recognized by BIOS,
etc, it could be that bad bearings are preventing things from stabalizing.
Or, it could be a seized platter or head dragging sound.
Keep the Focus on The Role of the Forensics Professional
If you haven't gotten the idea, yet...data recovery professionals can
really get most, if not all, of the data back nearly 100% of the time.
Unless there is a really good reason, e.g. budget, they really should
be considered.
Firmware problems can only be addressed by professionals. And, they can
present themselves in many ways. They are often, for example, confused
with bad heads or a bad board. And, remember the need for cleanrooms,
special jigs, and special tools.
Honestly, I suspect that full half, or more, of all drive problems
that (a) result in the inability to read any data, (b) aren't explained by
some acute event, like being dropped, (c) aren't explained by a power
event or problem, (d) aren't explained by a cabling problem, and (e) produce
no abnormal noises, other than clicking are probably firmware.
So, why do we care? We've got the drive. We've got to do our job and
analyze it. Or, we've got to work with those who are relying upon us
to help them to understand (a) what's wrong, (b) how it can be fixed,
(c) the liklihood of success, (d) the cost in time and money, and (e) when
repair is irreversable changing the evidence.
We've got to work with them to find data recovery professionals who
can do the job, and to maintain the chain of evidence, if necessary, along
the way. We've got to document the initial state of the device, and the
state upon receiving it back. Once repaired or recovered, we've got to
be able to report back on the actual impact of the process on data
forensics.
Drives Can Fail Anytime -- Even on Your Bench
Drives can fail at any time, even on your bench. It is rare, but it
happens. Take obvious precautions. Use filtered power and only
equipment in good condition. Use a UPS, if possible. Copy the data
-- immediately. Make two copies, not one. Record your initial
imaging, if appropriate. Inspect the drive, and all equipment,
before beginning. Document everything.
If a drive fails in your custody, you will likely be blamed by some.
That can't be helped. The best medicine is prevention, which doesn't
always work. The next best medicine is forthrightness and detailed
documentation. Note any abnormality and the time.
Note any mistakes you make that might compromise the data. If you get
lucky, and the swapping of that cable didn't break anything, then it
isn't important. If you drop the drive, and it turns up with bad sectors,
it is best that you note the details of the drive's fall. It'll be
embarassing. It might cost you credibility. But, it is the Right Thing
to do. And, your forthrightness is the only thing that will protect
your credibility, if the other side finds out (as by that ding on the
side you didn't notice, but wasn't there in their photo).
You never want you, or the other side, to be surprised by something you
did! Document everything!
Warning to all Readers
These are unrefined notes. They are not published documents. They are
not citable. They should not be relied upon for forensics practice. They
do not define any legal process or strategy, standard of care, evidentiary
standard, or process for conducting investigations or analysis. Instead,
they are designed for, and serve, a single purpose, to help students to jog
their memory of classroom discussions and assist them in thinking critically
about the issues presented. The author is certainly not an attorney and
is absolutely not giving any legal advice.