Return to the lecture notes index
January 25, 2008 (Lecture 6)
Reading
- Coulouris, et al: N/A
- Chow and Johnson: N/A
Motivation
XML is here. XML is not a fad. XML is not hype. If you haven't already,
I predict that you will write an XML application within the next few
years. I fear that the only ways out are a change of vocation, prison,
or death.
Extensible Markup Language (XML): Overview
The Extensible Markup Language (XML) is a text mark-up language
similar in appearance to HTML. Both HTML and XML, for example, use
<tags>. But, despite the cosmetic similarity, XML and HTML have
very different missions in the world.
Despite recent revisions that blurr its purpose, HTML is basically a
presentation language. Although only loosely, it allows a document author
to describe how various elements of a document should appear when
interpreted by the client-agent. For example HTML can describe the font's
size, style, and color, or the placement of an image. It also allows the
author to describe the structure of a document, including such things as
paragraphs and headers, so that the client-agent can display them
appropriately. It also allows documents to be linked to each other
through the now ubiquitous hypertext links.
XML, by contrast, describes the structure of the document and the meaning
of its elements, not how they should be displayed. In many cases, XML
documents are only processed and never displayed. In those cases where
they are displayed, the XML document, which contains the annoted data,
must be further described, for example by XSL or CSS, to allow for its
meaningful presentation.
Some people like to suggest that XML is a language for describing the
semantics of data. I, for one, think that this type of language might
be a little strong. Yes, a well-formed XML document can often, without
any further information, be meaningfully interpreted by a human reader.
But, this isn't only the case -- and is almost never the case in
situations where the context of the data isn't already known to the
reader. Proper XML can always be parsed by an ignorant machine -- but
nothing meaningful will happen unless the machine has been programmed
to solve a problem with the given data.
Suggesting that XML describes the semantics of data is correct -- but
no more so than suggesting that well-formed and well-named data
structures describe the semantics of a program.
Why is XML important?
XML is critically important, because it is what it promises to be,
an extensible way of describing data, while remaining light-weight
portable and transferable, and human-friendly.
One of the most critical problems is the representation of data. It
appears any time data is acquired, stored, or interchanged. XML is
"one solution that fits all". Plain text can be represented everywhere
and interchanged among environments without much difficulty. Furthermore,
since XML tags are defined by the document author, not the standard
writer, and because XML supports namespaces, XML is truly extensible.
Additionally, standards have evolved around XML to handle all of the
peripheral challenges of producing real-world solutions using XML.
For example, applications can be created rapidly using DOM or SAX-2,
and the presentation of XML can be described using XSL or CSS. Futhermore
DTDs and Schemas can be used to describe XML formats. As a result
DTDs and Schemas are natural tools for describing the protocol between
components of an application and validating the compliance of the
implementation.
A Few Details of the XML Language
A full discussion of XML is beyond the scope of 15-498. There are
tons of great resources at the local bookstore and on the Web. But,
here are a few observations that will get us through the 15-498 material:
using XML as a tool for marshalling RPC.
Metadata: ?xml
Unlike HTML documents, there are no tags to begin or end the document.
There isn't a header, per se, either. Instead XML documents begin with
a simple prologue. Althought this prologue is technically option, in practice,
it is almost alwasy used -- as it should be.
This is a minimal prologue, identifying only the version of XML.
<?xml version="1.0">
Here is another one, this time it also indicates the character set.
<?xml version="1.0" encoding="ISO-8859-1">
Metadata: target Specification
The same data type might be used by different types of applications.
For example, a data type describing a customer order might be
processed by either a sale application, a refund application, or
a backorder application. In some cases, the target application
can be encoded into the data type. But, in other cases, the type
is an established standard and cannot be changed.
To solve this problem, XML provides the ?target tag. It specifies
application specific metadata that is not part of the document:
<?target BLAH BLAH?>
Open Tags Must Be Closed
Unlike HTML, open tags must be closed. In other words, each
<tag> must have a corresponding </tag>. No, really
-- you must do this. Anything is is an error and will be recognized
as such by the parser at the other end. In those cases where a tag
stands by itself, rather than denotes a boundary, a slightly different
form is used: <tag/>. This type of tag does does not need to be,
and should not be, closed.
Namespaces
In HTML, valid tags were defined by the standard. In XML, programmers
can define their own elements and attributes. This definition usually
takes the form of a DTD or Schema specification, which
we'll discuss shortly.
One consesequence of this is that different applications might use
the same tags in different ways. As a result, the name space
can't be global -- it would be polluted without effort. To address this
potential problem, XML implements name spaces. Name spaces are
simply defined using a locator, such as a URL.
A namespace can be set within the beginning tag of an element. It then
applies as the default to that element and to all elements nested within
it:
<elementName xmlns=http://www.myplace.com/app>
When a particular instance of an element should use another namespace,
the namespace can be named explicitly within the tag. This is done
using the : operator as shown below. "ns" is the name of the namespace.
Notice how it is used as the prefix of the elementName and specified through
a URL via the "xmlns" attribute.
<ns:elementName xmlns:ns=http://www.myplace.com/app>
Hyper-links
XML's mechanism for specifying the queivalent of HTML HREFs is the "xlink:
attribute. It can be applied to any tag. Notice the example below which
link's my first name and last name, nested within the person element, to
by Web page:
<person xlink:type="simple" xlink:href="http://www.cs.cmu.edu/~gkesden">
<firstName>Gregory</firstName>
<lastName>Kesden</lastName>
</person>
The link above is a one-to-one link, much as is provided in HTML. In
addition, XML can actually provide a one-to-many link, as is shown
below. In the example below, there are three different links from
"phone" -- to a cell phone, office phone, and home phone.
<person xlink:type="extended"">
<firstName>Gregory>/firstName>
<lastName>Kesden>/lastName>
<phone xlink:type="locator" xml:label="cell" href="cell.html"/>
<phone xlink:type="locator" xml:label="office" href="office.html"/>
<phone xlink:type="locator" xml:label="home" href="home.html"/>
</person>
Related Technologies: Specifying an XML format
Many, many technologies have sprung up around XML. We certainly can't
even mention all of them today, never mind discuss them in detail. But,
I do want to give you a quick lay of the land, just so you'll be a little
more conversational and have some sense of the tools that are available.
One of the most critical aspects of making XML applications work is
describing the data format. This is, in effect, the protocol that will
be used between the components. A good specification will serve not only
as a document for the programmer, but also as a device for the application
to validate its input. There are two common approaches to this task:
Document Type Definitions (DTDs) and Schemas.
My favorite of the two is also the least powerful, the DTD. To dilute the
value of my opinion, I will tell you that DTDs only all the specification
of the structure of an XML document, but not the type associated with
the elements. Some people also consider the syntax of DTDs to be a bit
overcomplicated. What to say in my defense? One is comfortable with what one
has used -- and many, many people do use DTDs.
The other alternative is to use an XML Schema. Schemas, as a tool
for describing the structure and type of data, are a very old tool -- they
are a popular device in database design, for example. There is an adopted
standard language for specifying schemas for XML. This language allows
the writing of a specification, similar in function to a DTD, but
it is typed and somewhat more flexible in structure. The increased
flexibility, as you might imagine, can result in a much looser and less
manageable specification.
Related Technologies: APIs
Application programmers don't need to write their applications from
scratch. Two popular technologies make this task much easier:
The Document Object Model (DOM) and the Simple API for
XML (SAX-2).
Of these two, DOM is my less favored. This is because DOM builds and
keeps in memory a tree representing the entire XML document. For example,
consider the document shown below:
<?xml version="1.0">
<person>
<fname>Greg</fname>
<lname>Greg</lname>
<phone>
<home>412-687-6198</home>
<office>412-268-1590</office>
</phone>
</person>
This can be represented as the tree below:
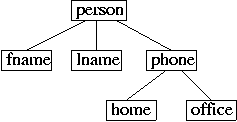
DOM builds this tree as the XML document is being processed, and then
uses the tree to process the document -- this can take up a huge number
of resources, especially for large documents. And, it is especially
wasteful if only a small component of the document is actually of concern.
For most of the limited work I've done with XML, I've found SAX-2
(the second version of SAX), to be a much more user-friendly model.
It works very, very loosely like yacc. It ties the recognition of
features of an XML document to code that should be activated when they
are found. For example, if some action should be taken when a first name
is located, SAX is an excellent tool. But, there are no absolutes here
-- we can all think up plenty of examples that require the state of
multiple parts of the document to act -- in which case DOM becomes
a reasonable model.
XML-RPC
XML is an excellent tool for representing RPC calls or RMI invocations.
All of the important pieces of information, including the
method name, paramters, and return values, can be specified using
XML. XML-RPC is a standard for doing that and is supported in many
languages and evnironments through libraries.
XML-RPC is a fairly intuitive serialization of method invocations,
returns, and faults. These messages are typically sent via HTTP's POST method.
The format of the messages is readily seen by example.
A Simple Example of an RPC Call
The only thing in the example below that isn't intuitive is that there
is no specification of the return value. This is because one isn't needed.
The reason is that the format for the return value is known a prior.
Programs know whether or not a function will return a value and, if it does,
what type it will be. As a result, there is no reason to specify this.
POST /RPC2 HTTP/1.0
User-Agent: SomeRPCClient/1.0.0 (HostOSName)
Content-Type: text/xml
Content-length: 184
<?xml version="1.0">
<methodCall>
<methodName>somebject.someMethod</methodName>
<params>
<param>
<value><int>32</int>
</param>
<param>
<value><boolean>32</boolean>
</param>
<param>
<value><string>32</string>
</param>
<param>
<struct>
<member>
<name>name</name>
<value><string>Gregory Kesden</string></name>
</member>
<member>
<name>Street</name>
<value><string>Forbes Avenue</string></name>
</member>
<member>
<name>Building number</name>
<value><string>5000</string></name>
</member>
</struct>
</param>
<param>
<array>
<data>
<value><intgt;10</int></value>
<value><string>Greg</string></value>
</data>
</array>
</param>
</params>
</methodCall>
A Simple Example Of An RPC Response
There isn't much suprising in this example of the return of
an RPC procedure:
HTTP/1.1 200 OK
Connection: close
Content-length: 180
Content-Type: text/xml
Content-length: 184
Date: Fri 24 Jan 2003 04:04:02 GMT
Server: SomeRPCProgram/1.0.0-HostOSName
<?xml version="1.0">
<methodResponse>
<params>
<value><int>5</int></value>
<value><string>Greg Kesden</string></value>
</params>
</methodResponse>
A Fault During An RPC Call
The example below shows how XML-RPC specifies the failure of an
RPC call. The return contains a short fault code, and a more meaningful,
more intuitive explanation:
HTTP/1.1 200 OK
Connection: close
Content-length: 180
Content-Type: text/xml
Content-length: 184
Date: Fri 24 Jan 2003 04:04:02 GMT
Server: SomeRPCProgram/1.0.0-HostOSName
<?xml version="1.0">
<methodResponse>
<fault>
<value>
<struct>
<member>
<name>faultCode</name>
<value>Client.Authentication</value>
</member>
<member>
<name>faultString</name>
<value>Bad things happen to good people, but who are you?
</value>
</member>
</struct>
</value>
</fault>
</methodResponse>
The Simple Object Access Protocol (SOAP)
Another XML-based technique for implementing RPC is through the
Simple OBject Access Protocol (SOAP). Although this protocol
was initially conceived to solve exactly this problem, it has
grown into a much more general-purpose protocol. As it stands now,
it can be used to send almost any type of message within an application
or among applications in a networked environment.
A SOAP message consists of an optional header and a body
contained within an envelope. The header contains metadata needed for
processing the message and the body contains the message itself. SOAP
messages can pass through intermediaries on their way to the final
destination. As a result, the header might, for example, contain
information about how intermediaries should interact with the message.
RPC via SOAP doesn't require a header.
In general, a SOAP message has the form:
<soap:Envelope xmlns:soap="http://schemas.xmlsoap.org/soap/envelop/">
<soap>
<soap:Header>
<! the header >
</soap:Header>
<soap:Body>
<! the body >
</soap:Body>
A SOAP HEADER
RPC via SOAP doesn't require a header, but let's take a look at an
example, anyway, just for completeness. The header below includes
the mustUnderstand attribute. This instructs the processor
that it must understand a nested SOAP message, or it should fault.
There are other options within a header, as well.
<soap:Header>
<soap:soapRPCrequest soap:mustUnderstand="1"
soap:actor=http://www.myplace.com/rpcservice/>
</soap:Header>
A SOAP RPC Procedure Call
The example below illustrates how SOAP can be used to marshall an
RPC call. For the most part, it is pretty intuitive, but there
are a couple of things that I'd like to point out.
First, please notice the SOAPAction: line in the HTTP header.
This line is option. It provides the URL of a plain-language description
of what the SOAP body is trying to accomplish, for example, invoking
a remote method.
The second is the the use of the xsd name space and the related
type definitions. "xsd" is an abbrevation of XML Schema Datatypes.
These data types are contained, no surprise, within the "xsd" namespace.
The xsd data types serve much the same purpose for RPC within SOAP
as XDR serves for ONC RPC and CDL serves for CORBA.
POST /NameOfService HTTP/1.1
Content-type: text/xml
Content-length: 500
SOAPAction: "http://www.someplace.com/document#callSomeProcedure"
<soap:Envelope xmlns:soap="http://schemas.xmlsoap.org/soap/envelop/">
<soap:Body>
<ns:someProcedure xmlns:ns=http://www.somewhere.com/>"
<ns:someParameter xsi:type="xsd:string">SomeString</ns:someParameter>
<ns:someOtherParm xsi:type="xsd:int">10
</soap:Envelope>
The Return of a SOAP RPC Call
The code below shows the return from an RPC call. It should be very
self-documenting:
HTTP 1.1 200 OK
Content-type: text/xml
Content-length: 500
<soap:Envelope xmlns:soap="http://schemas.xmlsoap.org/soap/envelop/">
<! SOAP RPC doesn't need a header -- this piece is just for conversation>
<soap:Header>
<soap:soapRPCrequest soap:mustUnderstand="1"
soap:actor=http://www.myplace.com/rpcservice/>
</soap:Header>
<soap:Body>
<ns:someProcedure xmlns:ns=http://www.somewhere.com/">
<ns:someReturn xsi:type="xsd:string">ReturnValue</ns:someReturn>
</ns:someProcedure>
</soap:Body>
</soap:Envelope>
Problems During an RPC Call
As is the case with any RPC call, bad things can happen. And, as is
the case in any remote invocation facility, SOAP's RPC needs to be
able to handle this. It does this by returning a fault as shown below.
I think the format is pretty self-documenting.
HTTP 1.1 500 Internal Server Error
Content-type: text/xml
Content-length: 500
<soap:Envelope xmlns:soap="http://schemas.xmlsoap.org/soap/envelop/">
<soap:Body>
<faultcode>soap:Server:serviceDown</faultcode>
<faultstring>Bad things happen to good people.</faultcode>
</soap:Body>
</soap:Envelope>
Some Good Reading Material on the Web