Return to the lecture notes index
March 28, 2007 (Lecture 26)
Reading
- Chow and Johnson: 5.1 - 5.4
- Coulouris, et al: N/A
An Introduction to Processor Allocation
One interesting aspect of distributed systems is that we can choose
upon which processor to dispatch a job. This decision, and the associated
action of dispatching the job onto the processor, is known as processor
allocation.
Depending on the environment, different factors may drive our decision.
For example, many environments consist largely of networks of (personal)
workstations (NOWs). In these enviornments, it may be advantageous
to "steal" cycles from other uses while they are away from their
machines leaving them idle. This is especially attractive since some
studies have shown that the typical workstation is idle approximately
70-80% of the time. Of course we would only want to do this if our
own workstation is substantially busy -- otherwise we would be paying the
price of shipping our job, and perhaps user interaction, &c, both ways
and gaining little or nothing. It is certainly forseable that the
unnecessary use of a remote processor can increase (worsen)
turnaround time.
In other cases, we may have pools of available "cycle servers" and
underpowered personal workstations. If this is the case, we can
organize our system so that it always dispatches jobs to a remote
processor. But, in either case, we want to make sure that we make
a careful choice about where we should send our work -- otherwise
some poor machine may get smashed.
Transparent processor allocation is different than simple remote
execution, as might be provided by something like rhs. The
biggest difference is in transparency -- the user need not known that
the job is executing other than locally. The second difference is that
processor allocation can lead to migration, or the movement
of a job after it has begun executing.
A Centralized Approach: Up-Down (Mutka & Livny '87)
The first technique that we'll talk about is named Up-Down. The
goal of the Up-Down approach tries to be somewhat fair to users in the
way that it allocates processors. It does this by giving light weight
users priority over "CPU hogs". Users earn points when their workstation
is idle. This is, in effect, credit for allowing others to use their
processor. Users lose points when they consume the idle CPU on remote
hosts. The points are accrued or spent at a fixed rate. This approach
assumes that a user is associated with exactly one workstation (his or
her workstation).
When a processor becomes avaialble, it gives it to the requestor with the
greatest number of points. This favors those users who are net providers
of CPU and penalizes those who are net users. In effect, it ensures that
if you only need processor time occasionally, you get it right away. But,
if you have used tons of CPU, you yield to those who have been less
demanding recently.
Obviously it is impossible for everyone to be a net consumer of CPU,
since one can't use more CPU than is available. Everyone can, however be
a net supplier of CPU, since it is possible for all hosts to be idle.
Hierarchical Approach
It requires some overhead to determine where a process should be run.
This overhead can grow quite large, especially if many machines are
assumed to be busy. An alternative to the approach described above
is to use a hierarchical approach. Instead of assuming the
peer-to-peer workstation model as we did above, we are going to assume
a model with many "worker" workstations, and a smaller number of
"manager" workstation.
We organize these workstations into a tree, with all of the workers
as leaves. The leaves are then collected into groups and each group is
given a manager. Each group of workers becomes the children of their
manager in the tree. These manager's in turn are grouped together and
given a directory. These directors have a common parent, which is the
root of the tree. One alternative is to use a "board of directors"
instead of a single root.
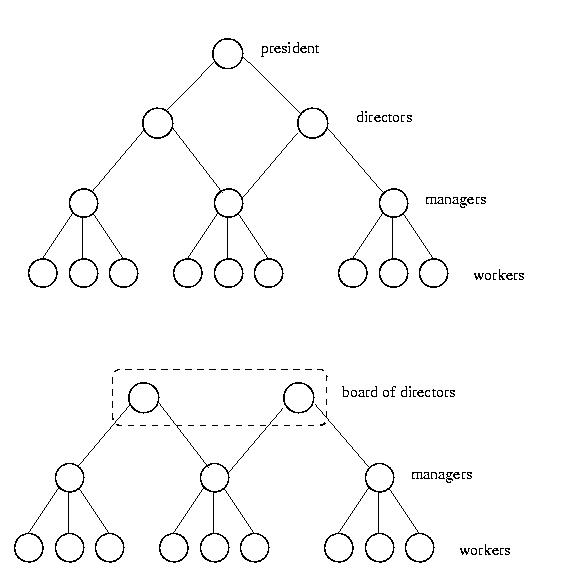
Under this organization, a worker tries to maintain its load between
a high and low watermark. If it gets too much work or too little work,
it tells its manager. Its manager will then use this information to try
to shift work among its workers to properly balance the load. The managers
themselves have quotas. If they find themelves with either a shortage or
surplus of cycles, they tell their directors, who in turn try to balance
the load among their managers, and so on. If the top level is a committee,
instead of a signle node, this provides for some level of fault tolerance.
If each member of the committee knows everything, it may be possible for
a decision to be made, even if one fails.
The goal of this approach is to reduce the amount of information that
must be communicated across the network in order to balance the load.
Let's Talk About Loads
If workstations are to cooperate and share work, they must somehow,
directly or indirectly, communicate their work levels to each other.
Obviously, this leads to a trade-off between perfect information and a
tolerable level of communication. We need to have a protocol that will
give us "good enough" information.
One nieve approach is to have processors "yell out" to everyone when
they are idle. But this approach has a big problem. If a processor
"yells out" to all of the other processors, they might all send work its
way. The previously idle processor suddenly is heavily loaded. Then,
another processor, perhaps one that recently off-loaded work becomes idle,
and "yells out". Well, that processor gets slammed with work. If a facility
for process migration exists, things get even worse. This probelem is
known as thundering herds.
In order to solve the thundering herds problem, we can use a different
form of this receiver initiated technique. Instead of broadcasting
to everyone, an idle processor can "ask around". As soon as it finds
work, it stops asking. If it doesn't find work after asking some fixed
number of hosts, it sleeps, while waiting for more of its own work,
and tries again after a dormant period, if it remains idle. This
approach leasds to hevy communications overhead when the processors
are mostly idle.
Another and complimentary approach is known as sender initiated
processor allocation. Under this approach a host which notices that its
queue of waiting jobs is above some threshold level will "ask around" for
help. If it can't find help after asking a fixed number of hosts, it
assumes that everyone is busy and waits a while before asking again.
As was the case with receiver initiated processor allocation, it is
good to poll a random collection of hosts to keep things balanced.
Unfortunately, this approach leads to heavy communications overhead when
the processors are mostly busy.
Hybrid approaches are also possible. These try to balance the costs
of the above two approaches. They only "yell out" if they are substantially
overworked or under worked. In other words, a processor won't yell out
for help, unless it has a really, really long run queue. And it won't
advertise that it has cycles available, unless it has been idle for
some time. Typically, under hybrid approaches, processors can operate
in both sender-initiated or receiver-initiated modes, as necessary.
Processor Allocation and IPC
When processors are interconnected with each other via IPC, this becomes
a consideration for processor allocation. If the processes are cooperating
very heavily and cannot make progress without IPC, it might make sense
to run them in parallel. Co-scheduling (Ousterhout '82) is
one technique for resolving this. It schedules groups of cooperating
processes to run in parallel, by useing round-robin style scheduling,
and placing the cooperating processes in corresponding time slots
on different processors.
Another technique, known as Graph Theoretic Deterministic
scheduling builds a weighted graph of all of the processes. The edges
are IPC channels, weighted by the amount of communication. The basic idea
is that it is best to have processes that require a great deal of IPC
running on the same host, so that the latency associated with the IPC
is minimized. These approaches work by partioning the graph into one
subgraph for each processor in such a way as to minimize the weight of
the disected edges.
Although the complexity of these approaches makes them poor choices for
real-world systems, they are a rich area of theoretic research. It is
also common place for humans to keep IPC vs. network traffic in mind
when making this type fo decision by hand.
A Microeconomic Approach
I have to confess that this approach, Ferguson, et al, in 1988, isn't
the most practical, and it isn't of much theoretical significance --
but I love the free market. I can't help myself.
The basic idea is that processes are given money, perhaps in accordance
with their priority. They take this money and buy the resources that
they need, including a processor and the communication channels to
move there and back.
When a processor becomes available, it holds a bid. The high bidder wins.
Processes bid for a processor by checking a bulletin board to see what
the processor's last selling price was. They also consider the cost
of the network connection to move there and back. Once they've done
that, they decide which processors they might be able to afford, and
make a bid on one them. They bid on the processor that wil give them
the best service (fastest clock?), while leaving them with enough
of a surplus that they can still afford to get back, if the communication
channel goes up in price.
They bid the last winning bid, plus a piece of the surplus that would be
left over if they won the bid. This surplus is what's left over after the
processor wins the bid and buys the network, &c. The surplus is important,
because the network could go up in price -- the surplus may prevent
the process from becoming stranded for a long time.
This approach isn't very practical -- it requires a great deal of overhead.
And it isn't clear to me how money should actually be handed out. But
it does provide an efficient use of resources. It might also be useful
in cases where resources can provide distinctly different qualities of
services. In these cases, the free market system might ensure that they
are allocated in an efficient way. Of course, the efficiency would have
to be sufficient to justify the very high overhead of this technique
-- not likely.