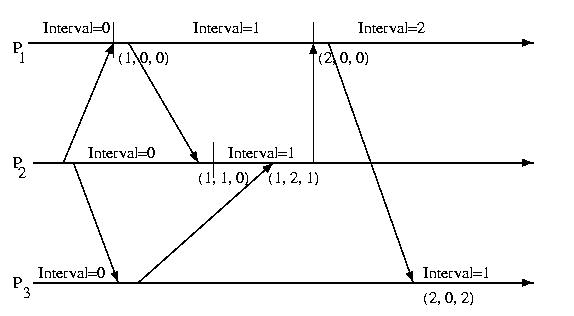
The approach that we'll discuss makes use of direct dependency vectors. Before defining a DDV, we need to define an interval. An interval on a processor is the period of time between receiving two messages. The intervals on a particular processor are sequentially numbered and given an interval index. Each time a processor sends a message, it also sends its current interval.
On the receiving process, a direct dependency vector is associated with the event. This vector contains the processor's understanding of the interval on all processors. This information may be out of date, and does not take gossip into account. One processor is only informed about another processor's interval, if it directly receives a message from that processor. It is important to pay attention to the fact that the interval must be directly communicated from one process to another -- it is not transative and cannot be communicated indirectly. A message from processor X to processor Y only contains X's interval, not the DDV present on X.
The diagram below illustrates gthe intervals and DDVs associated with each processor.
We can define the global state of the system at any point in time to be the collection of the DDVs at each processor. We can organize this state into a Global Dependency Matrix (GDM). We'll follow your textbook's nomenclature and give this the somewhat misleading label GDV.
The diagram below shows the GDV at two different points in time:
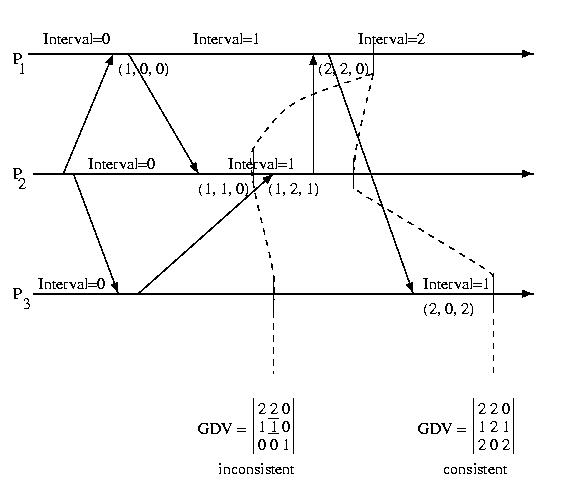
Notice that the first GDV is inconsistent. The DDV component of the GDV from Processor 1 indicates that Processor 1 has received a message from Processor 2 indicating that Processor 2 is in Interval 2. But the DDV vector within the GDV from Processor 2 indicates that Processor 2 is in Interval 1. This indicates an inconsistent recovery line. The second GDV does not have any inconsistencies -- it is consistent recovery line.
We can check to see if a GDV is valid, by looking at each DDV one at a time. For each entry in a consistuent DDV, the interval shown for another procesor must be less than or equal to the interval that that processor's DDV within the GDV contains for itself.
GDV(p)[q] <= GDV(q)[q], 1<=p, q<=M
In other words, no processor can have received a message from another processor originating in an interval in advance fo that processor's current interval.
So, we know what an inconsistent state looks like, but how do we find a recovery line? We start out with the initial state of all processors composing a valid recovery line. We store this in a vector, RV, that contains the interval index for each processor -- these will initially be 0.
Then each time a procesor commits enough log entries or checkpoints to make a new interval stable, it sends this information to a central server that tries to advance the recovery line.
To find the recovery line, the coordinator keeps a matrix with the current recovery line, and a bin of recent interval updates that are are not a part of the current recovery line. The coordiantor then applies the recent update to the matrix and checks for consistency. It also attempts to include as many of the other recent updates from the bin as possible. If it is unable to incorporate the most recent update into a consistent recovery lines, it adds it to the bin -- a future update may make it usable.
For those who would like a more formal look at one possible implementation of this algorithm, the following pseudo-code might be helpful:
find_recoverable (RV, p, k)
TRV = RV // Make a copy of the current recover line (RV)
TRV[p] = k // advance the interval for processor p to k
// in this temporary copy -- a candidate
// that needs to be check for inconsistency
// Compare the DDV for each processor to the entries in TRV,
// a temporary and optimistic GDV. Record inconsistencies
// in Max
for q = 1 to M // M is the number of processors
Max[q] = max(TRV[q], DDV(p,q)[q])
// Try to resolve inconsistencies by looking at stable intervals
// that we haven't been able to use, yet (previously other
// processors weren't stable in sufficiently advanced intervals)
While there is a q such that Max[q] > TRV[q]
Let l be the minimum index such that l >= Max[q] and stable(l)
If no such l exists // if we can't fix the problem with these states
return (fail) // we're going to have to try again later to advance
TRV[q] = l // If we can fix this problem, optimistically
// add this interval to the TRV
for r = 1 to M // And recompute the Max matrix so that we
// can check for new incocnsistencies
Max[r] = max(Max[r], DDV(q,l)[r])
// There are no inconsistencies, sThere are no inconsistencies,
// so make the candidate recovery line, the real thing.
RV = TRV
return (success)