Return to lecture notes index
January 16, 2008 (Lecture 2)
Reading
- Coulouris, et al: Chapters 1-3
- Chow and Johnson: Chapters 1-2
What is a Distributed System?
A Distributed System as an abstraction. It is a way of organizing and
thinking about a collection of independent and possibly distant or
weakly connected resources as if they were all part of the same tightly
coupled package.
In his textbook, Andrew Tannenbaum, a famous pioneer in distributed
systems, defines it this way:
"A distributed system is a collection of independent computers that
appear to the users of the systems as a single computer.
--Andrew Tannenbaum, Distributed Operating Systems (1995), Pg 2.
Distributed Systems vs. Parallel Systems
Often we hear the terms "Distributed System" and "Parallel System."
What is the difference?
Not a whole lot and a tremendous amount -- all at the same time.
"Distributed System" often refers to a systems that is to be used by
multiple (distributed) users. "Parallel System" often has the connotation
of a system that is designed to have only a single user or user process.
Along the same lines, we often hear about "Parallel Systems" for
scientific applications, but "Distributed Systems" in e-commerce or
business applications.
"Distributed Systems" generally refer to a cooperative work environment,
whereas "Parallel Systems" typically refer to an environment designed to
provide the maximum parallelization and speed-up for a single task.
But from a technology perspective, there is very little distinction.
Does that suggest that they are the same? Well, not exactly. There are
some differences. Security, for example, is much more of a concern in
"Distributed Systems" than in "Parallel Systems". If the only goal of
a super computer is to rapidly solve a complex task, it can be locked
in a secure facility, physically and logically inaccessible -- security
problem solved. This is not an option, for example, in the design of
a distributed database for e-commerce. By its very nature, this system
must be accessible to the real world -- and as a consequence must
be designed with security in mind.
System Model
When I teach 15-412, Operating Systems, I begin with a picture
that looks like the one below. If you didn't take OS, please don't
worry -- everything on the picture, almost, should be familiar to
you. It contains the insides of a computer: memory and memory
controllers, storage devices and their controllers, processors, and
the bus that ties them all together.
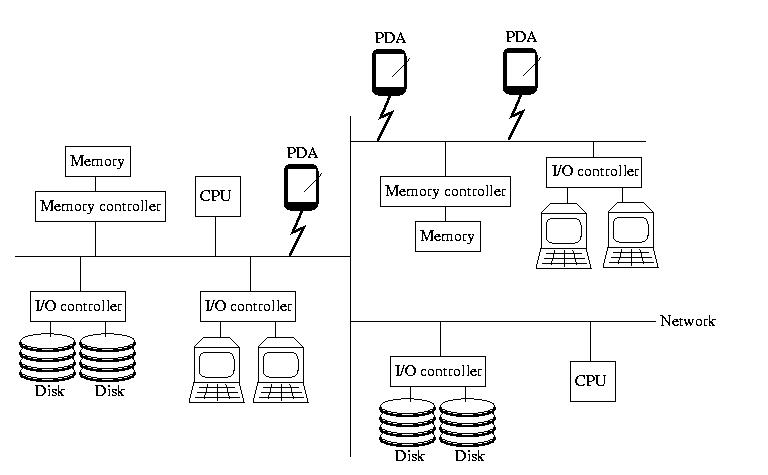
This time however, the bus isn't magical. It isn't a fast, reliable,
predictable communication channel called that always works and maintains
a low latency and high bandwidth. Instead, it is a simple, cheap,
far-reaching commodity network that may become slow and bogged down
and/or lose things outright. It might become partitions. And, it might
not deliver messages in the same order that they were sent.
To reinforce the idea that this is a commodity network, like the
Internet, I added a few PDAs to the picture this time. Remember,
the netowrk isn't necessarily wired -- and all of the components
aren't necessarily of the same type.
Furthermore, there is no global clock or hardware support for
synchronization. And, to make things worse, thr processors aren't
necessarily reliable, and nor is the RAM or anything else. For
those that are familiar with them, snoopy caches aren't practical,
either.
In other words, all of the components are independent, unreliable
devices connected by an unreliable, slow, narrow, and disorganized
network.
What's the Good News?
The bottom line is that, despite the failure, uncertainty, and
lack of specialized hardware support, we can build and effectively
use systems that are an order of magnitude more powerful. In fact we can
do this while providing a more available, more robust, more convenient
solution. This semester, we'll learn how.
Measures of Quality
In building a distributed system to attack a particular problem,
what are our specific measures of quality? What are the
characteristics of a good system?
Just as there isn't one "perfect fod" for all people and all occasions,
our goals in implementing a distributed system may vary with the
particular problem. But, the following are some very typical and common
measures of quality in distributed systems:
- Efficiency: Resources should perform productive work whenever
possible.
- Convenience: The user should be free to apply the system to one
or more tasks, with as little overhead as possible.
- Robustness: The system should be resiliant to failure. Failures
should have as little an impact on the system's
ability to perform useful work as possible.
- Availability: A user should be able to harness the utility of
the system with as few barriers as possible.
For example, users should not be bound to an
unavailable instance of a resource, when an equally
capable resources is available.
- Consistency: see below
- Coherency: see below
- Transparency: see below
Consistency vs. Coherency
Although these two terms actually mean very different things, they
are often interchanged or used as synonyms. Although this practice
isn't descriptive, it is common place -- please don't be surprised.
Different processes are said to have a consistent view of
data, if each process sees the same value. If different processes
see different values, they are said to have an inconsistent
view of the data. Inconsistencies often arise as the result of
replication. For example, if each process uses its own private
replica of the data, one process might not see another process's
changes. This could result in an inconsistent view.
Later we'll see that constantly maintaining atomic consistency,
a.k.a. perfect consistency, is very, very expensive, and often
not required in a particular application. For this reason, we often
will select a more relaxed consistency model that describes
when the data values can diverge, without generating incorrect results.
But more on this later in the semester...

Data is said to be incoherent if it is the result of a collection of
operations that make sense sense individually, but not collectively.

Transparency
A distributed system should hide the machinery from the user and present a
unified interface that provides the features and hides the complexity.
To the extent that this illusion is achieved, we say that transparency
is achieved. No useful real-world system achieves complete transparency,
so we often talk about the transparency of particular characteristics or
features of a system. And even when discussing a particular feature
or characteristic, there are many shades of gray.
A few examples are given below:
- access transparency -- the user should have the same view of
the system regardless of how she or he
access it. For example, consider a
user accessing the system locally versus
remotely, or on her or his workstation
versus another machine on the system.
- location transparency -- the user should need to know or care
where resources are located -- they
should just be accessible.
- migration transparency -- user's should know or care if
resources or processes move -- they
should function exactly as they did before.
- concurrency transparency -- concurrent operation should not result
in noticable side-effects.
- failure transparency -- the user should not notice failures. The
system should function as before (fail-safe)
or should suffer only in performance
(fail-soft).
- revision transparency -- software and hardware upgrades should not
interrupt service or generate user-visible
incompatibilities.
- scale transparency -- the system should be able to grow without
noticable side-effects. It should be as good
for small systems as large ones.
A Very Quick Look at Networks
Some of you have taken a course in networks, such as 15-441. But since
many have not, I'm going to take a really quick look at networks
before moving on to middleware, which will occupy most of next
week. Middleware is the software layer that hides the network
from the application programmer, by providing an API that is targeted
more directly for the problem domain.
When talking about the problems faced in connecting multiple computers
or other devices, we often discuss the problem using the OSI/ISO
Reference Model. It presents the challenges of network communication
by breaking them down into seven (7) different layers as below:
| Application |
| Presentation |
| Session |
| Transport |
| Network |
| Data Link |
| Physical |
In a technical sense this model, which was developed in the 1980s by the
International Standards Organization is the standard model
for discussing the Open System Interconnect (OSI) environment.
But, more broadly, it is a good roadmap for discussing networks -- and,
in fact, implementations conforming to the OSI/ISO standard are pretty
obscure and of little commercial impact.
The Physical Layer
At the bottom is the physical layer. This layer is the abstraction
for the network protocols that define the physical media and devices,
themselves. It governs the types of cabling and the use of the
electromagnetic spectrum for example. This might include the shape of
the conectors, the voltages and impedence levels on the interface cards,
the shape of the waveforms, the color of light used for fiber optics,
or the RF space and use thereof.
Examples of physical layer protocols include IEEE 802.11b or IEEE 802.3b
The Data Link Layer
Above this is the data link layer. The data link layer
manages the use of the physical media. Typically, this layer
performs framing. In other words, it breaks large streams
of data into smaller, manageable pieces known as frames.
Each frame is easier to manage, and can include error correction and/or
error detection codes. These make it possible for the link layer
to detect and drop bad frames. Some link layers use error correction
codes to correct many errors. Additionally, link layers provide
some way of identifying stations within a LAN.
Some physical layers implement sharing via a static technique, such
as time-division multiplexing (TDM) or frequency-division
multiplexing (FDM). In other words, each station gets its very own
piece of the network -- either by taking turns (TDM) or by dividing
up the frequency space (FDM). This allows sharing without any special
treatment by the link layer.
But other networks, use what is known as statistical multiplexing
or broacasting. In other words, the physical layer allows
any station to transmit at any time -- if they collide with each other
and destroy each others transmission -- it becomes the link layer's
problem to recover.
The Medium Access Control (MAC) layer, which is a sublayer
within the data link layer, is charged with implementing the
policies for managing collisions in broadcast networks.
One common example of a link-layer protocol is Ethernet. The undlerlying
physical layer for which it was designed allows collision to occur,
but provides tools to detect it and to sto transmitting if it occurs.
But, it is up to Ethernet, the data link layer, to implement the
policies that reschedule the transmissions, as needed.
The data link layer allows stations within the same
Local Area Network (LAN) to communicate with each other.
The Network Layer
The Network layer is responsible for the movement of packets
of information among LANs. As LANs are connected together, getting a
packet betwen them isn't trivial. There might not be a direct path between
two LANs, in which case, the packet might have to cross one or more
intermediate networks to get to its final destination. To make things
work, at any step of the game, the might be more than one network
that could be a "next step" to the final destination -- internetworks
can have significant redundancy. Among other things, the network layer
must also provide a way of identifying each network, such as a
network number.
The network layer is responsible for routing a packet between
the source and destination network. In other words, it is charged with
finding the path, through other networks, between the source and
the destination network. As discussed above, the link layer
is responsible for getting the packet from its source to the
router on the source network, and then from the router
on the destination network to the final destination station.
The Transport Layer
The network layer contains a lot of machinery that application
programmers need not care about. Instead, programmers often want
to think about network programming in terms of endpoints -- the
source and destination, for example, the client and server. The
transport layer hides the details of the network layer
and provides this abstraction.
Different link layers might provide different types of service,
for example reliable service versus unreliable service,
or stream service versus a message-oriented service,
or a connection-oriented service versus a connection-less
service. We'll talk more about these in just a few minutes.
The Session, Presentation, and Application Layers
In the OSI/ISO model, the session, presenation, and application layers
are three separate layers, but they are often rolled into one
and simply considered the application layer. The TCP/IP protocol suite,
for example, takes the "rolled into one" approach. The reason for this
is that instances of these layers are often not very generally applicable
-- they often only fit one particular application.
The session layer is resonsible for managing the session, or
persistent connection between two hosts. It, for example, might
be responsible for the recovery of the session, if the transport
layer breaks down, as might occur if one host fails and reboots.
The presentation layer is responsible for converting data from
the format used by one host to that used by another host. The "classic"
eample here is the conversion of IBM's EPCDIC representation of
characters to ASCII, and vice-versa. More modern examples might
include adjusting floating-point data for Endian-ness, or converting
between ISO character set standards.
And, last, but not least, is the application layer, which arguably
incorporates the other two. This layer is the interface between
the network and the rest of the application program. It, for example,
defines the messages that can be sent between a HTTP Web server and
client, or the structure of a MIME encoded email message.
Service Types and Quality at the Transport Layer
The transport layer can provide many, many different types of services
and offer many, many different levels of quality, specified in all sorts
of different ways. For our purposes, we're just going to take
a look at some of the most basic characteristics.
Some transport layers offer stream-based service, whereas others
are message-oriented. Streams-based services don't distibguish
between message boundaries -- they just provide a queue of bytes.
The sender enqueues the bytes, the receiver dequeues them.
message-oriented services provide a message abstraction. Think of a
message as an envelope or package. An envelope is filled, and then
delivered unopened to the recipient. The recipient gets one envelope
at a time.
For our purposes, the link layer will throw away any frames that
become corrupted. They never make it to the network or transport layers.
The question at the transport layer is, what should be done about the
lost pieces of information. Unreliable transport layers
do nothing -- the missing pieces are simply never delivered and,
in the case of stream protocols, anything that arrives out of order
is discarded.
Reliable transport layers attempt to retransmit seemingly
lost pieces of information, until they are confirmed as delivered.
They also ensure that everythign stays i order by bufferign or
dropping pieces of information that arrive out of order.
It is important to realize that reliable protocols do not guarantee
that information will make it from the sender to the receiver, and
they certainly can't guarantee that the information will arrive
within some finite amount of time. For reasons we'll talk about
a little later -- this guarantee can only be made if the transmission
media, itself, is perfect.
Because reliable protocols require continued cooperation between
the sender and the receiver, they must be connection-oriented.
In other words, they are like a phone call: a connection is intiated,
used, and then broken. When the connection is "live" both parties
know about each other and can maintain information about the status
of the session -- such as what has arrived and what should be expected
next.
Connection-less protocols don't maintain the continuous session,
or shared state, between the endpoints. Connectionless protocols
are often used for unreliable message-oriented communications.
This is basically the U.S. Postal Service model. You pack an
envelop, mail it out, and hope for the best. If it never arrives,
the other side never knows it missed out -- and hopefully it
didn't matter too much.
The TCP/IP protocol suite provides two transport-level protocals:
the Transmission Control Protocol (TCP) and the
User Datagram Protocl (UDP). TCP provides reliable, connection-oriented
stream service. UDP provides unreliable, connectionless, message
(datagram) service.
When reliable message-oriented service is required, many applications
use TCP, but encode message boundaries in the application-level protocol.
In other words, parsing the TCP stream will yield individual messages.
Other applications create "ACKed UDP" protocls, by using UDP to send
messages, but keeping shared state and managing retransmission at
the application level.
What If This Whole Discussion Has Been Confusing?
Relax! I know this is probably a bit blurry to those who haven't taken
a course in networks. That's okay. A blurry understanding is good
enough for us. 15-213 covered the socket API, which is all one need to
know to do network programming. And, aside from that, we'll use middleware
for most of our project work (you can pick your own weapon for Project #3).
We talked about this today just so you'd have a general understanding
of these issues when they come up on occasion during the semester. Please
remember that if things ever come up that you don't understand, you
should ask -- we're here to help. That includes anything related to
network issues. For now, just get the "big picture" landscape -- and
you'll be fine.