Return to lecture notes index
February 8, 2011 (Lecture 9)
Distributed Concurrency Control: An Introduction
We discussed concurrency and concurrency control in 15-213, and beat
the topics to death in 15-410. So, right now, I'm just going to give
the "Nickel tour".
Life is simple if we all have our own kingdom. Everything is ours.
There's never a reason to share. No compromises ever need to be
made. We get what we want, whenever we want it.
But, in the real world, this isn't always the case. Often time -- like
it or not -- we have to share. And, how we share is particularly
important. If we don't do it well, feelings get hurt and things get
broken.
The situation is more-or-less the same for software. In many cases,
different things are going on and these things need to share certain
resources. We call these different, independent, things threads
of control, which includes traditional threads, traditional
processes, and other models for work-in-progress. A resource
is an abstraction for anything that we might have to share. Another
way of viewing a resource is an abstraction for any reason to wait.
Some resources might be associated with physical things, such as
printers, terminals, the user, or the network. Other reasons to
wait are more abstract resources -- pieces of software that model
objects not present in the physical world.
When we've got the potential for more than one thread of control to
be chasing the same resource, we need to have some way of resolving
contention. In other words, we need some way to figure out
who gets the resource and when. Not only do we need such a policy,
but we also need some mechanism to enforce it.
Concurrency Control: Mutual Exclusion and Other Policies
The policy that is used to divy up a recource among its contenders
depends largely on the resource and the application. From the
perspective of the resource, it might onyl be possible for one
user to use it at a time. Or, it might be possible for a certain
fixed number of users to access it at a time. Or, the number of
users might depend on the character of the users.
From the perspective of prioritizing the users, there might be all
sorts of different scenarios. Perhaps certain users are more important
than others and, as a consequence, should be given priority. Or,
perhaps it is more efficient for users to be scheduled in a certain
order. Or perhaps fairness is our goal and users should be scheduled
in exactly the same order as the request is made. Or, perhaps it
doesn't matter, and any order will do.
Although the potential policies are endless, we are going to focus on
only one of them -- the most important in practice. We are going to
focus on finding a mechanism to implement mutual exclusion
without priority. Mutually exclusive access to a resource implies
that all of the users agree (hence mutual) that the use of the
resource by one exludes the concurrenct use by another (hence
exclusion). Given a mechanism to implement mutual exclusion, we can
actually construct much more complex systems.
Characteristics of a Solution
We often like to say that, for a policy and corresponding mechanism,
to ensure mutual exclusion in a meaningful and useful way, it must ensure
three things: mutual exclusion, progress, and
bounded wait.
The first of these three is meaningful on its face: If more than one
user can access the resource at the same time, we are clearly not
ensuring correct concurrency control.
The second, progress, though it takes a bit of explaining, is very
common sense. A good solution to concurrency control allows the
resource to be used, if available. It is not meaningful to declare,
"We're implementing mutual exclusion -- no one can use the resource."
Satisfying the progress requirement means that, if the resource is
available, and if there is at least one user, someone should get
the resource.
The third characteristic also makes sense: If someone wants a resource,
they should eventually get it. Again, its not quite fair to declare,
"Sure, we're implementing mutual exclusion -- only process 0 can use
the resource. This condition means that, among other things, deadlocks
and live locks should not occur.
Mutual Exclusion: Why Re-Invent the Wheel
Okay, great, so we're building distributed systems. Why re-invent
the wheel? In 15-213 (and 15-410), we discuss many techniques. The
least common denominator of which includes simple mutexes and
semaphores.
The problems with these tools in the context of distributed systems
is that they included shared state. In the case of a simple mutex,
a boolean variable. In the case of a semaphore, a shared queue. These,
in turn imply some type of shared memory.
The problem with this is that shared memory requires synchronization,
a type of concurrency control. The problem is that each of the multiple
parties must see the same queue and value before any decisions can be
made. This type of synchronization is exactly what we are trying to
construct.
As a result, we are going to construct a new set of tools. By comparison,
they'll seem a bit crude. But, in practice -- they work. And, we can
build more convenient tools from them (at some expense), if we so desire.
Base Case: Centralized Approach
Although centralized approaches have their standard collection of
shortcomings, including scalability, fault-tolerance, and accessibility
they provide a useful starting point for discussions. So we'll begin by
discussion a centralized approach to ensuring mutual exclusion for a
critical section:
- A Central Coordinator is needed.
- This coordinator can be appointed or elected
- The coordinator is responsible for granting requests
to enter the critical section
- It ensures that only one thread is in the critical section
at a time.
- If the critical section is in use, the request is enqueued
otherwise, the request is immediately granted
- Enqueued requests are granted when the critical section
becomes available
- Want into the CS?
- Ask the coordinator & wait for permission.
- Done with the critical section?
- Tell the coordinator
- The coordinator will then let the next thread in, if any.
- Good Traits
- It does guarantee mutual exclusion
- It only requires 3 messages per critical section entry
(request, permission, done)
- Shortcomings
- The coordinator dies...then what?
- Thread dies in the critical section
- In either of the above cases, it is hard to tell what has happened
- Standard centralized problems
Leases
When possible, especially in distributed environments, which are
inherently failure-prone, we don't want to give a user a permanant
right to a resource. The user might die or become inaccessible, in
which case the whole system stops.
Instead, we prefer to grant renewable leases with liberal terms.
The basic idea is that we give the resource to the user only for
a limited amount of time. Once this time has passed, the user needs
to renew the lease in order to maintain access to the shared
resource. Within the last ten years or so, almost all mutual
exclusion and resource allocation systems have taken this approach,
which is expecially well suited for centralized approaches.
The amount of time for the lease should be long enough that it
isn't affected by reasonable drift among synchronized physical clocks.
But, it should be short enough that the time wasted after the end
of the task and before the lease expires is minimal. It is also
possible to allow the user to relinquish a lease early.
The other problem is enforcement -- the user must be unable to
access the resource after the credential expires. There are basically
two ways of doing this. The leasing agent can tell the resource of
the leasee and the term, or the leasor can give the leasee a copy
of the lease to present to the resource.
In either case, cryptography is needed to ensure that the parties
are who they claim to be and that the lease's content is not altered.
We'll discuss how this can be accomplished in more detail later. But,
for now, let me just offer that it is often done using public key
cryptography.
This can be used to authenticate the parties, such as the leasor
the leasee, or the resource, and it can also be used to make the
lease unalterable by the leasee.
Timestamp Approach (Lamport)
Another approach to mutual exclusion involves sending messages to all
nodes, and ordering requests using Lamport logical time. The first such
approach was described by Lamport. It requires that ties be broken using
host id (or similar value) to esnure that there is a total ordering among
events.
This approach is based on the notion of a global priority queue of requests
for the critical section. This queue is ordered by the logical time of the
request. Unlike the central algorithm we discussed as the "base case",
this approach calls for each node to maintain a copy of this queue. The
copies are maintained in a consistent way using a request-reply protocol.
When a node wants access to the critical section, it sends a REQUEST
message to every other node. This message can be sent via a multicast
or a collection of unicasts. This message contains the logical time of
the request. When a participant receives this request, it adds it
to its priority queue and sends a REPLY message to the requesting node.
The requesting node takes no action until it receives all of the replies.
This ensures that the request has been entered into all of the queues,
and that, at least with respect to this request, the queues are consistent.
Once it receives all of the replies, the request is free to go -- once its
turn arrives.
If the critical section is available (the queue was previosuly empty),
the request can go as soon as the last REPLY is received. If the critical
section is in use, the request must wait.
When a node exits the critical section, it removes itself from its own
queue and sends a RELEASE message to every other participant, perhaps by
multicast. This message directs these nodes to remove the now-completed
request for the critical section from their queues. It also directs them
to "peek" at their queue.
If the first request in a hosts queue is itself, it enters the critical
section. Otherwise, it does nothing. A host can enter the critical
section if it is at the head of its own queue, because the REPLY ensures
that it will be at the head of every other node's queue.
The RELEASE message does not need an ACK or a REPLY, because it does
not matter if its arrival is delayed. Since we are assuming a reliable
unicast or multicast, the RELEASE will eventually reach each participant.
We don't care if it arrives late -- this doesn't break the correctness
of the algorithm. In the worst case, it is delayed in its arrival to the
next requestor to enter the critical section. In this case, the critical
section will go unused until the RELEASE arrives and is processed by the
host. In the other cases, it delays the host in "peeking" at the queue,
but this is without consequence -- the delayed host wasn't going to
enter the critical section, anyway.
But wait! Why do we need the REPLY to the REQUEST, then? Can't we just
get rid of that. Well, not exactly. The problem is that a reliable
protocol guarantees that a message will eventually arrive
at its destination, but makes no guarantees about when. The
protocol may retransmit the information many, many times, over
many, many timeout periods, before successfully delivering the message.
In the case of the RELEASE message, timing is not critical. But this is
not the case for the REQUEST message. The REQUEST message must be
received, before the requesting node can enter the critical section.
This is the only way of ensuring that all nodes will see the same head
node, should a RELEASE message arrive. Otherwise, two different hosts
could look at their queues, determine that they are at the head, and
enter the critical section -- disaster. This disaster could be detected
after-the-fact when the belated REQUEST arrives -- but this too late since
mutual exclusion has already been violated.
This approach requires 3(N - 1) messages per request: REQUEST, REPLY, and
RELEASE must be sent to every other node. It isn't very fault-tolerant.
Even a single failed host can disable the system -- it can't REPLY.
Timestamp Approach (Ricarti and Agrawala)
The Lamport approach described above was improved by Ricarti and Agrawala.
Ricarti and Agrawala observed that the REPLY and RELEASE messages could
be combined. This is achieved by having the process that is currently within
the critical section delay its REPLY until it exists the critical
section. In order to do this, each process must queue REQUESTs
while within the critical section.
In many respect, this change converts this approach from a "global
queue" approach to a "voting" approach. A node requests entry to
the critical section and enters the critical section as soon as
it has received an OK (REPLY) vote from every other node.
The details of this approach follow:
Requestor Request
- Build a message
- Send message to all participants
Paritipants
- If not in CS and don't want in, reply OK
- If in CS, enqueue request
- If not in CS, but want into the CS, and the requestor's
time is lower, reply OK (messages crossed, requestor was first)
- If not in CS, but want into the CS, and the requestor's
time is greater, enqueue request (messages crossed, participant
was first)
Exit
- On exit from CS, reply OK to everyone on queue (and dequeue each)
Requestor Entry
- Once received OK from everyone, enter CS
This approach requires 2*(n - 1) messages, that is one message to and
from everyone except self. This is an (n - 1) improvement over
Lamport's approach.
But it fails to address the more serious limitation -- fault tolerance.
Even a single failure can disable the entire system. Both timestamp
approaches require more messages than a centralized approach -- and
have lower fault tolerance. The centralized approach provides
one single point of failure (SPF). These timestamp approaches have
N SPFs.
In truth, it is doubful that we would every want to use either approach.
In practice, centralized coordinators and ring approaches are
the workhorses. Centralized coordinators can be made more fault
tolerant using coordinator election (comming soon).
But these timestamp approaches are the most distributed -- they involve
every host in every decision. They also illustrate some important
examples of global state, logical time, &c -- and so they are a
valuable part of this (and any) distributed systems course.
Mutual Exclusion: Voting
Last class we discussed the Ricarti and Agrawala approach to ensuring
mutual exclusion. It was much like asking hosts to vote about who
can enter the critical section and allowing access only upon unanimous
consent. But is unanimous consent necessary? Can't we get away with a simple
majority since two hosts can't concurrently win a majority of the votes.
In a simple form, it might operate similarly to a democratic election:
When entry into the critical section is desired:
- Ask permission from all other participants via a multicast,
broadcast, or collection of individual messages
- Wait until more than 50% respond "OK"
- Enter the critical section
When a request from another participant to enter the
critical section is received:
- If you haven't already voted, vote "OK."
- Otherwise enqueue the request.
When a participant exits the critical section:
- It sends RELEASE to those participants that voted for it.
When a participant receives RELEASE from the elected host:
- It dequeues the next request (if any) and votes for it with an
"OK."
Ties and Breaking Ties
So far, this approach is looking nice, but it does have a problem:
ties. Imagine the case such that no processor gets a majority of the
votes. Consider, for example, what would happen if each of three processors
got 1/3 of the votes. Ouch!
Ties can, in fact, be broken at a somewhat high cost. If we use Lamport
time with total ordering via hostid, no two messages will have concurrent
time stamps. Messages that would otherwise be concurrent are ordered by
hostid.
Recall that a host votes for a candidate as long as it has no outstanding
votes. This becomes problematic if its vote turns out to be premature.
This occurs if it votes for one candidate to later receive a request,
bearing an earlier timestamp, from another candidate.
At this point, one of two things might be occuring. The system might be
making progress -- the "wrong" host might have gotten more than 50%
of the votes. If this is the case, we don't care. It might not be fair,
but it is an edge case.
Another possibility is that no host has yet received a majority of
the votes. If this is the case, it could be because of deadlock.
It might be that each candidate got the same number of votes. This
is the case that requires mitigation.
So, upon discovering that it voted for the "wrong" candidate, a host
needs to determine which of these two situations is the case. It
sends an INQUIRE message to the candidate for who it voted. If this
candidate won the election, it can just ignore the INQUIRE and
RELEASE normally when done. But, if it hasn't yet entered the critical
section, it gives back the vote and signals this by sending
back a RELINQUISH. Upon receipt of the RELINQUISH, the voter is free
to vote for the preceding request.
Analysis and Looking Forward
This approach certain has some nice attributes. It does, in fact, guarantee
mutual exclusion. And, it can allow a host to enter the critical section
even if 1/2 of the hosts are down or unreachable.
But it has non-trivial costs. Nominally, it takes 3 messages per entry to
the critical section (request, vote, release), about the same as a timestamp
approach. And, in the event that votes arrive in exactly the wrong order,
an INQUIRE-RELINQUISH pair of messages can occur for each host.
What we need is a way to reduce the number of hosts involved in making
decisions. This way, fewer hosts need to vote, and fewer hosts need to
reorganize thier votes in the event of a misvote.
Mutual Exclusion: Voting Districts
In order to address to reduce the number of messages required to win an
election we are going to organize the participating systems into voting
districts called coteries (pronounced, "koh-tarz" or "koh-tErz"),
such that winning an election within a single district implies winning the
election across all districts.
Coteries is a political term that suggests a closed, somewhat
intimate, and conspiring collection of actors (persons,
states, trade organizations, unions, &c), e.g. a "Boy's Club".
This can be accomplished by requiring that elections within any district be
won by unanimous vote and then Gerrymandering each processor's district to
ensure that all districts intersect. Since the subset of processors that
are members of more than one district can't vote twice, they ensure that
only one of the districts can gain a unanimous vote.
Gerrymandering is a term that was coined by Federalists in the
Massachusetts election of 1812. Governor Elbridge Gerry, a Republican,
won a very narrow victory over his Federalist rival in the election of 1810.
In order to improve their party's chances in the election of 1812, he and
his Republican conspirators in the legislator redrew the electoral
districts in an attempt to concentrate much of the Federalist vote into
very few districts, while creating narrow, but majority, Republican
support in the others.
The resulting districts were very irregular in shape. One Federalist
commented that one among the new districts looked like a salamander.
Another among his cohorts corrected him and declared that it was,
in fact, a "Gerrymander." The term Gerrymandering, used to describe
the process of contriving political districts to affect the outcome
of an election, was born.
Incidentally, it didn't work and the Republicans lost the election.
He was subsequently appointed as Vice-President of the U.S. He
served in that role for two years. Since that time both federal law
and judge-made law have made Gerrymandering illegal.
The method of Gerrymandering disticts that we'll study was developed by
Maekawa and published in 1985. Using this method, processor's are
organized into a grid. Each processor's voting district contains all
processors on the same row as the processor and all processors on the same
column. That is to say that the voting district of a particular processor
are all of those systems that form a perpendicular cross through the
processor within the grid. Given N nodes, 2*SQRT(n) - 1 nodes will compose
each voting district.
Using this approach, any pair of voting districts will intersect via
at least one node, so two disticts cannot be one unanimously at the same
time.
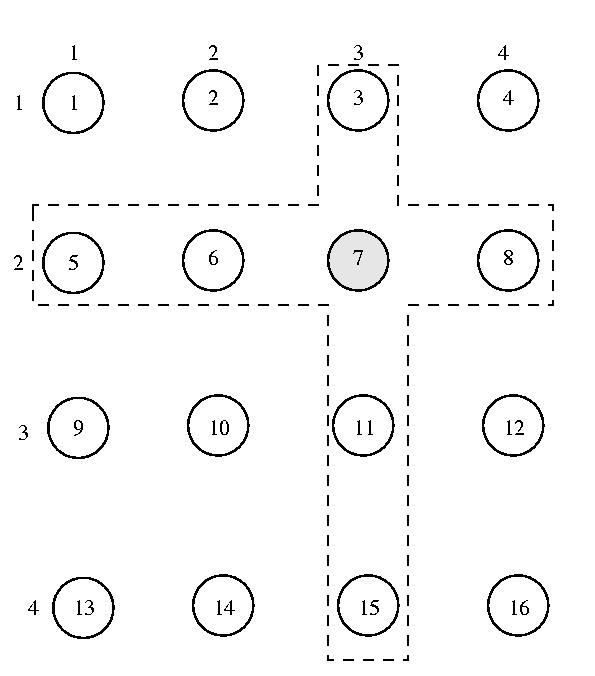
The voting district of processor 7
Here's what a node does, if it wants to enter the critical section:
- Send a REQUEST to every member of its district
- Wait until every member of its district votes YES
- Enter the critical section
- Upon exit from the CS, send RELEASE to each member of its district.
If a node gets a REQUEST, it does the following:
- If it has already voted in an outstanding election
(it voted, but hasn't received a corresponding RELEASE),
enqueue the request.
- Otherwise send YES
If a node gets a RELEASE:
- Dequeue oldest request from its queue, if any. Send a YES vote to
this node, if any.
As we saw with simple majority voting last class, this approach can
deadlock if requests arrive in a different order at different voters.
This can allow different voters within overlapping districts to vote
for different candidates. In particular, it can allow for a "split"
between the two voters that are the overlap between two districts.
Fortunately, we can use the same approach we discussed last class
to recover from this situation if it becomes problematic:
- A node records Lamport time w/total ordering before it sends
a request. It sends this time with the request to all members of
its district (the same time).
- Each voter uses a priority queue based on the time of the request.
- If a node receives a request with a time-stamp more older than the
timestamp of a request for which it already voted, but for which
it has not received a RELEASE, it attempts to cancel its vote. It
does this by sending the candidate an INQUIRE.
If this node hasn't won the election, it forgets about our vote
and sends us a RELINQUISH. Once we receive the RELINQUISEH, we
vote for the older request and enqueue the candidate for which we
originally voted.
If the candidate was already in the CS, no harm was done -- deadlock
did not actually occur. When it goes out, we can vote for the other
candidate. In this case, the processors may not have entered the
CS in FIFO order, but that's okay -- deadlock didn't happen.
This approach requires about 3*(2*SQRT(N)-1) messages -- much nicer than
3*N messages. But it is not very fault tolerant, since a unanimous
victory is required within a district. (Some failure can be tolerated, since
failures outside of a district don't affect a node).
Token Passing Approaches
At this point, we've considered several different ways of approaching
mutual exclusion: a centralized approach, a couple of timestamp approaches,
a voting approach, and voting districts. Another approach is to create
a special message, known as a token, which represents the right
to access the critical section, and to pass this around among the hosts.
The host which is in possesion can access the shared resource -- the
others cannot. Think of it as the key to the gas station's bathroom.
Since there is only on key, mutual exclusion is ensured.
Token Ring Approach
The first among these techniques is perhaps the simplest -- and certainly
among the most frequently used in practice: token ring.
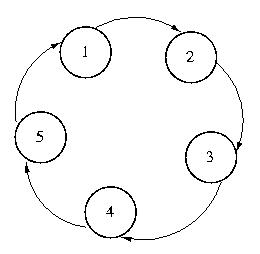
With this approach, every system knows its successor. The token moves from
system to system through the list. Each system holds the token until it
is done with the CS, and then passes it to its successor.
We can add fault tolerance to this approach if every host knows the
mapping for all systems in the ring. If a successor dies, then the
successor's successor, and successor's successor's successor, and
so on can be tried. A host assumes that a system has failed if it cannot
accept the token.
What happens if a system dies with the token? If there is a known time-out
period, the origin machine can regenerate the token and start circulating
it again. Depending on the nature of the CS, this could be dangerous, because
multiple tokens could exist. If only one has access to the resource, this
might be a problem.
The number of messages required per request is very interesting. Under
high contention, the number is very, very low -- as low as one. If every
system wants entry to the CS, each message will yield another entry. But
if no one wants access to the CS, messages will occur for no reason.
But in general, we are more concerned about traffic when congestion is high.
That makes this algorithm particularly interesting. It is especially
interesting in real-time systems, because the worst-case behavior is
well-bound and easily computed.