Return to the lecture notes index
January 25, 2011 (Lecture 5)
Message Passing
Early and rudimentary distributed systems communicated via message
passing. This form of communication is very simple. One side packages
some data, known as a message and sends it to the other side where it
is decoded and further action may be taken. The format of the message and the
way in which it will be processed by the receiver are application dependent.
In some applications the receiver may respond by sending a reply message. In
other cases, this might not happen.
It is important to realize that the messages carry only data and are
typically represented in a way that is known only by the sender and receiver
-- there is nothing standard about it. Unless mitigating action is taken by
the designer of the message format or the implementer of the application,
the communication might not be interoperable across platforms, because
of representation differences (e.g. big-endian vs. little-endian).
This approach also makes it hard to reuse components of one distributed
system in other distributed systems, because there is really no concept of
a common library -- everything is "hand rolled".
Remote Procedure Calls (RPC)
Although message passing can be effective, it would be nice if there
were a more uniform, reusuable, and user-friendly way of doing things.
Remote Procedure Calls (RPCs) provide such an abstraction. Instead of
viewing the communication between two systems in terms of independent
exchanges of data, we back up a step and examine the overall behaviors
of the systems.
Often times the services of the system can often be decomposed into
procedures, much like those used in traditional programming. These
procedures accept certain types of information, perfomr some useful
operation, and then return a result. The RPC abstraction allows us to
extend this paradigm to distributed systems. One system can provide
remote procedure calls for use by other systems. From the applications
point of view, it can use these remote procedure calls much like local
procedure calls. Behind the scences, the RPC is actually connecting to
a remote host, sending it the parameters, performing an operation on that
remote host, and then returning the result.
This is very similar to a very specific use of message passing. In fact the
function invocation is a message from the client to the server. This message
names the function and also provides the parameters. After receiving this
message, the server performs the operation and sends a message back to the
client with a result. The client then treats this result as if it were the
return value from a local procedure call.
The important charachteristics of RPCs are these:
- They provide a very familiar interface for the application
developer
- They one way of implementing the commonplace request-reply primitive
- The format of the messages is standard, not application dependent
- They make it easier to reuse code, since the RPCs have a standard
interface and are separate from any one application-proper.
Limits of RPCs
From the perspective of the application programmer, RPCs operate much like
local procedure calls, but there are some important differences:
- A "call be address (reference)" is not possible, because the
two processes have different address spaces. Parameters that
otherwise might be passed by address are often passed by "in-out"
instead. In-out paramters are copied by value on procedure invocation,
and again upon return. The end result is that the calling procedure
has the new value of the data item. The difference in semantics
is that paramters passed by in-out retain their old value until
the function returns. Parameters that are passed by reference
can change value, even from the perspective of the calling function,
throughout.
- Addresses and other large objects are typically passed by address,
these need to be copied.
- Byte ordering issues (big-endian/little-endian) might need
correction
- Representation issues, sucha as ACII vs. EPCIDIC might
need mitigation.
- "Calls by (C++, et al) reference" require more work as does the
return of an object reference. This is because both sides don't
share either the same address space or the same mapping tables.
Marshalling and Stubs
The process of preparing and packaging the information for transmission
is known as marshalling (think of the marshal leading people at a
wedding). This often involves translating non-portable representations
into a portable or canonical form. In the case of Sun's implementation
of RPC, a set of conventions known as eXternal Data Representation (XDR)
is used.
In order to hide this process from both the application programmer and the
author of the RPC library, it is often implemented using automatically
generated stubs.
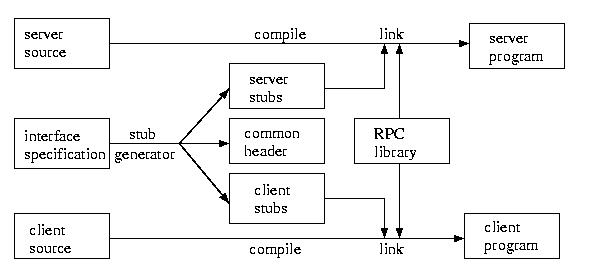
The process basically works like this. The programmer develops the
interface for the RPC. The stub generator takes this
interface definition and creates server stubs and client
stubs, as well as a common header file. The server stubs and
client stubs take care of the marshalling and unmarshalling of the
parameters, as well as the communication and procedure invocations.
This is possibly, because these actions are well defined given the
procedure's identity and parameterization. Once this is done, the
programmer can build the RPCs and the application. Each is linked
against the RPC library which provides the necessary code to
implement the RPC machinery.
This process is shown in the figure below:
RPC and Failure
The failure modes of RPCs are different than those experienced by
local function calls -- there are common failure modes! When was
the last time that you can remember a local function call failing?
I'm not asking when it was that you most recently observed a bug in
a function. I'm asking when it was that you most recently observed
the actual transfer of control fail. My point is that in conventional
systems this doesn't happen -- and if it should ever happen, it is
acceptable to do nothing, but roll over.
But this isn't the case in a distributed system. The communication to
the RPC server can fail. The reply from the RPC server can fail. The server
can crash. The client can crash. And worst of all, even if we know
that asomething bad happened, we may not know when. What to say?
Bad things happen -- but good software is prepared.
Please consider the situations shown below:
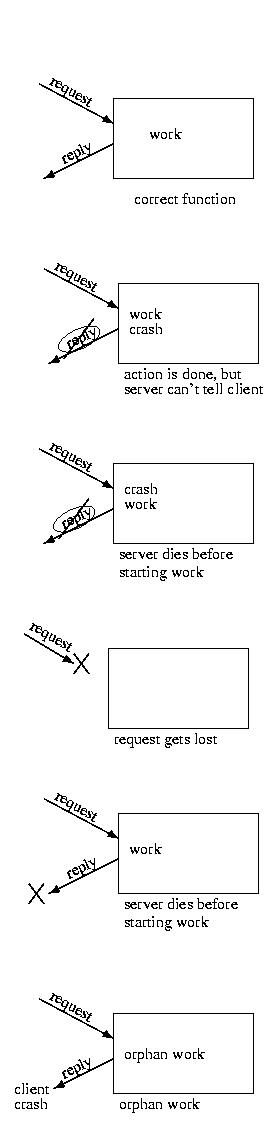
These failure modes lead to different semantics for RPCs in light of failure:
- exactly once -- the RPC will be executed exactly once -- never more,
never less. Althoguh this is most like local function calls, it is
very expensive to implement
- at most once -- if all goes well -- "Hurray! It worked!" Otherwise,
no big deal. The important thing is that the operation is never
repeated.
- at least once -- if all goes well -- "Hurray! It worked!" Otherwise,
keep repeating the operation -- even if there is a risk that
it might have happened already (e.g. lost ACK).
- idempotent -- The operation can be repeated without any change.
Often times at least once semeantics leads to the design of
idempotent operations.
Finding an RPC
RPCs live on a specific host, at a specific port. The port mapper
on the host maps from the RPC name to the port number. Typically when
a server is initialized, it registers its RPCs, and their
version numbers with the port mapper. A client will first connect to
the port mapper to get this handle to the RPC. The call to the
RPC can then be made by connecting to this port.
"Hello World!" RPC
Below are the source files for a simple "Hello World!" RPC program.
The server has a function which returns the string "Hello World!".
The client invokes this function remotely, and then prints out the
string that it received.
The helloworld.x file was fed to rpcgen, which in turn produced the
server and client stubs, helloworld_svc.c and helloworld_clnt.c, and
the common header file, helloworld.h.
Normally, the client code, the remote procredure's implementation,
and Makefile are created by the programmer from scratch. But, I actually
cheated here. "rpcgen -a" will create, in addition to the stubs,
skeletons for three more files: the Makefile, the client program, and
the remote procedure's implementation. I took the files it produced,
filled the remote procedure's implementation into the skeleton, and
slightly modified the client.
- helloworld.x:
The definition file fed to rpcgen
- Makefile:
The Makefile generated by "rpcgen -a"
- helloworld_client.c:
The client program's source, modified slightly from
the one generated by "rpcgen -a"
- helloworld_server.c:
The remote method's implementation, filled into the
skeleton provided by "rpcgen -a"
- helloworld.h:
The common header file generated by rpcgen
- helloworld_clnt.c:
The client stub produced by rpcgen from the helloworld.x file
- helloworld_svc.c:
The server stub produced by rpcgen from the helloworld.x file
Java's RMI: Introduction
Last class, we talked about ONC RPC and XDR. RPC and XDR provided
a facility for remote procedure calls across platforms. But, it did
not provide support for the object extraction -- an RPC program is
really nothing more than a collection of RPC procedures. The RPC
mechanism does not provide any way to represent an instantiation of
a program with private state or any other way of adaquately modeling
objects.
This class, we're going to talk about Java's RMI mechanism, which
provides a beautiful and highly transparent model for Remote Method
Invocation (RMI). Although Java's RMI supports the object abstraction,
it in some sense has it easy. Unlike RPC, it does provide true support for
interoperability. Instead, it provides the Java Native Interface (JNI)
to allow other languages to adapt to it. CORBA, which we'll discuss
next class, is a remote object solution that was designed specifically
with interoperability in mind.
The Big Picture
The figure below illustrates the model used by Java's RMI facility.
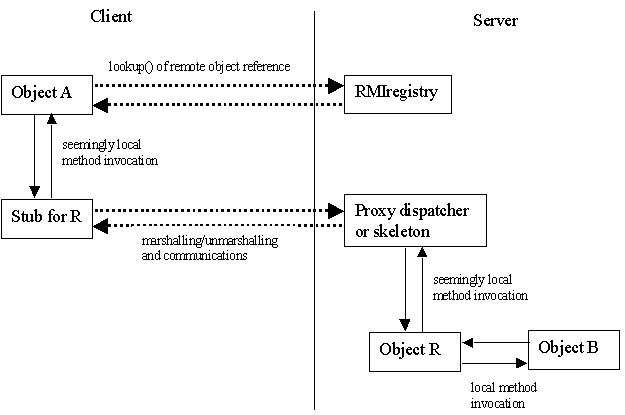
Remote Objects and Remote Object References
Java remote objects are exactly the same objects as Java's local objects.
Any object which implements a Remote interface can be used
as a remote object (programmers might also want their remote object
classes to extend UnicastRemote, because this fixes some
methods of the Object class, which are otherwise non-functional due
to exception issues that can't be made transparent).
For those less familiar with Java, remember that an interface
serves roughly the same function as a C/C++ header file with function
prototypes or a class definition -- except that Java enforces
it rigorously.
Java identifies objects using references. References are nothing more
than names for objects. Typical references, such as those contained
within Java's primitive reference variables are local references. That is
to say that these references are capable of naming object only within a
single JVM. Internally, Java also implements remote object references.
That is to say that Java can name on object within one JVM from another
JVM.
Java application programmers never actually
object known as a stub within the client's JVM. The application
programmer interacts with this stub as a proxy for the remote object. The
stub, in cooperation with the Java runtime, interacts with the remote object.
In other words, for practical purposes, the programmer just pretends that
the stub object is the remote object -- and it all works out.
Client-side Stubs
Java application programmers never actually posess a reference to a remote
object. Instead, Java represents objects to remote callers by placing a
proxy object, known as a stub, locally within the caller's JVM. It is
the job of this stub to handle the marshalling of the method invocation
into a message, the delivery of the message to the communication module,
and the reverse of this process, all the way to the client object, upon
the methods return. Since the stub object and the remote object implement
the same interface, the client can interact with the stub exactly as it
would the remote object, even though they are technically different classes.
There is at least one instance of the stub class for each remote object in
use within the JVM. If there are several remote objects, even if they are of
the same type, there are several different instances of the stub class, one
for each. Each instance of the stub class contains the remote object
reference for the object that it represents.
In order to ensure that only one stub exist for each remote object, Java's
RMI maintains a mapping between the remote object reference and the
local reference to the stub.
In one of Java's more magic features, if the class for the stub is not
already available on the client, it can be downloaded from the server via
HTTP. Java achieves this by sending the URL of the stub's .class file along
with the reference to the remote object.
Server-side Skeletons
In the original version of RMI, there was a server-side compliment to the
stub, known as the skeleton. The skeleton, like the stub, was
responsible for marshalling. Java 2 eliminated the need for the server-side
skeletons. It did this by factoring this functionality a common component,
which I call the proxy dispatcher.
This was possible, because no part of the process is necessarily unique to
the particular target object. The unmarshalling of the method call is a
mechanical step which yields a local object reference, a method to invoke,
and the parameters to this method. Once this is known, the process of invoking
the method using the local reference is the same for all objects. And, the
last step, the marshalling of the return value, is just as mechanical as the
initial unmarshalling.
The Stub Compiler: rmic
Just as RPC provides a tool, rpcgen, to generate the stubs, so does RMI.
RMI's tool is called "rmic". The application programmer feeds "rmic"
the .class file, and "rmic" generates both the stub and skeleton classes.
As discussed above, the skeleton classes are only needed for Java 1.
Pass by Value vs. Pass by Reference
In Java, parameters are passed into methods and returned from methods by
reference. This is problematic for an RMI facility, because not all objects
can be remote objects - not all JVMs are willing to expose any of their
objects, never mind all of them. As a result, the RMI facility needs to
determine which object can be passed by reference, and which can't. And, it
needs to have some mechanism for handling those that can't be passed by
reference.
To address the first concern, Java has a very simple rule. Any object that
is to be remotely accessible must be an instance of a class that implements
the Remote interface. Objects that implement the Remote interface are passed
by reference into methods and when they are returned from methods. Other
objects are passed by value, in other words by creating local copies.
Java passes object by value using a process known as serialization. Basically,
this means that Java flattens out the object, copies it, and sends this copy
to the other side. At the other side, the object is recreated from the
serialized copy, and a reference to this recreated object is used. Java needs
to have an object's .class file to reconstitute it from the serialized copy.
In order to recreate an object from a serialized copy, the object's .class
file is needed. To facilitate this, Java sends the URL for the .class file
along with the serialized copy. If the recipient doesn't already have the
.class file, it can download it via HTTP using the provided URL.
The result of this process is that there are two copies - one on each side.
The client's JVM has one copy and the server's JVM has another. Each acts on
its own copy. The object has been passed by value.
When Java passes an object by reference, it does this by passing a remote
reference to the object, along with the URL of the stub class. This enables
the recipient to recreate the stub object just as it did objects passed by
value. As before, if the recipient doesn't already have a copy of the
defining .class file, it can download it using HTTP via the provided URL.
The process of recreating a remote object or stub on the local system is
called localization. Pass by value localizes the remote object, pass by
reference localizes a stub for the remote object.
Failure and Exceptions
Unlike local method calls, remote method calls can fail. As an example, the
network could be down or partitioned. Java's native RMI handles this by
requiring that all methods of remote objects throw RemoteException. This,
in turn, requires that each use of a remote method catch the RemoteException.
Finding Remote Objects
Most remote objects are "found" when references to them are returned by
methods invoked on other remote objects. But, for obvious reasons, this
mechanism does not explain how all remote objects are found -- we need to
find the first object somehow.
Java does this using a server program known as the RMIregistry.
Servers that create remote objects designed to be the first point of contact
by a client can register these remote objects using bind() or rebind(),
which take a common, URL-style name and the local reference to the object.
Once that happens, a client can connect to the RMIregistry on that server and
ask for an object by name. In return, the client will get a reference to the
remote object. A client can also invoke the list() method on the RMIregistry,
which will return an array containing the names of all of the registered
objects. The registry isn't global, instead there is one per server.
Clients need to connect to a particular server's registry, which can tell
them only about the objects registered on the same server.
"Hello World!" RMI
Here's a really quick "Hello World" RMI. The client takes a String,
representing a person's first name and sends it as a parameter to
the (remote) instance of the Hello object. The Hello object then
returns a string such as, "Hello World! Hello Greg". The client then prints
this String.
I wrote Hello.java (the remote object) and HelloClient.java.
These were compiled, as usual, using "javac". I then used the rmi compiler,
"rmic" to create the stub class from the "Hello.class file": "rmic Hello".
For the curious, I used the DJ Java to decompile the resulting
"Hello_Stub.class" file, producing "Hello_Stub.java".
If you want to test this, first compile everything and run "rmic" on
the "Hello.class" file. Then, start the registry on the server:
rmiregistry &
Then, you'll need to start the server. The simplest possible way is like this:
java Hello &
But, if you do want the client to be able to automatically download the
_Stub file, you'll need to tell the server where it lives, by starting the
server as follows:
java -Djava.rmi.server.codebase=http://somemachine/somedirectory/ Hello &
In order for the client to have proper permission to access the network,
you may need a security policy file, such as the one I used,
"client.policy". If this is the case, start the client as follows:
java -Djava.security.policy=client.policy HelloClient Greg
Otherwise, you can just start it the simple, intuitive way:
java HelloClient Greg
In either case, we're directing java to instantiate the class "HelloClient"
and to run main with one parameter, "Greg".
The sample files are below: