As you know, distributed systems are very likely to suffer from failure.
This is a characteristic of their scale. Sometimes we have sufficient
redundancy to keep failures transparent. On other occasions, we need to
repair or replace failed processors and pick up where we left off before the
failure. This process is known as recovery.
Needless to say, recovery is a very important component of many real-world
systems. Recovery usually involves checkpointing and/or
logging. Checkpointing involves periodically saving the state of
the process. Logging involves recording the operations that produced the
current state, so that they can be repeated, if necessary.
Let's assume that one system fails and is restored to a previous state
(this is called a rollback). From this point, it will charge
forward and repeat those things that it had done between this previous
state and the time of the failure. This includes messages that it may
have sent to other systems. These repeated messages are known as
duplicate messages. It is also the case that after a rollback
other systems may have received messages that the revovering system
doesn't "remember" sending. These messages are known as orphan
messages.
The other systems must be able to tolerate the duplicate messages, such
as might be the case for idempotent operations, or detect them
and discard them. If they are unable to do this, the other systems
must also rollback to a prior state. The rollback of more systems
might compound the problem, since the rollback may orphan more messages
and the progress might cause more duplicates. When the rollback
of one system causes another system to rollback, this is known as
cascading rollbacks. Eventually the systems will reach a state where
they can move forward together. This state is known as a
recovery line. After a failure, cooperating systems must rollback
to a recovery line.
Another problem involves the interaction of the system with the real-world.
After a rollback, a system may duplicate output, or request the same
input again. This is called studdering.
One approach to checkpointing is to have each system periodically
record its state. Even if all processors make checkpoints at the
same frequency, there is no guarantee that the most recent checkpoints
across all systems will be consistent. Among other things, clock
drift implies that the checkpoints won't necessarily be made at
exactly the same time. If checkpointing is a low-priority background
task, it might also be the case that the checkpoints across the systems
won't necessarily be consistent, because the systems may have cycles
to burn at different times or with a completely different frequency.
In the event of a failure, recovery requires finding the recovery lines
that restores the system as a whole to the most recent state. This is
known as the maximum recovery line.
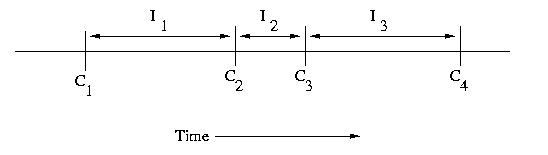
An interval is the period of time between checkpoints. If
we number checkpoints, C1, C2, C3,
C4, &c., the intervals following each of these checkpoints
can be labeled I1, I2, I3,
and I4, respectively. it is important to note
that the intervals need not be the same length.
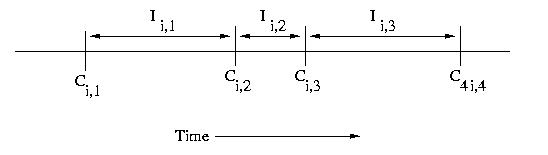
If we have multiple processors, we can use subscripts such
as Ci,c and Ii,c, where i is the processor number
and c is the checkpoint sequence number.
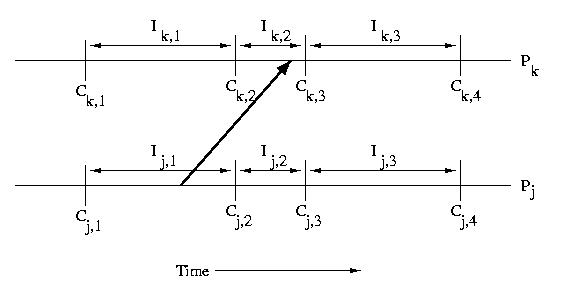
When a processor receives a message, that message usually causes it
to take some action. This implies that the processor that receives
a message is dependent on the processor that sent the message.
Specifically if a processor receives a message during an interval,
it is dependent on the interval on the sender's processor during
which the message was sent. This type of dependency can cause
cascading rollbacks.
In the example below, Ik,2 depends on Ij,1
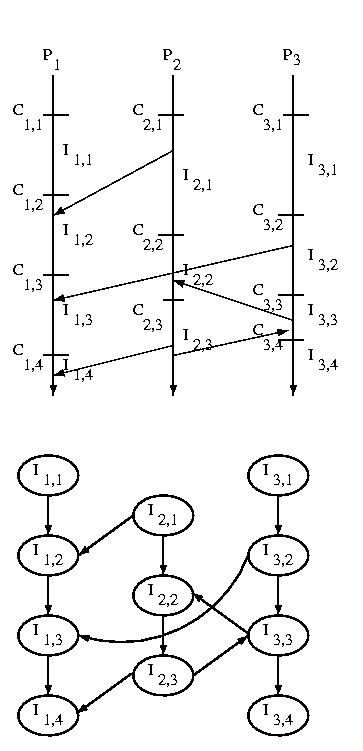
If we consider the messages sent among systems we can construct
an Interval Dependency Graph (IDG). If any intervals are
removed from the graph due to rollbacks or failures, we must
remove all intervals that they reference -- this is a transitive
operation.
The graph is constructed by creating a node for each interval,
and then connecting subsequent intervals on the same processor by
constructing an edge from a predecessor to its successor. Then
an edge is draw from each interval during which one or more messages
were received to the interval or intervals during which the message(s)
was or were sent.
The edge from one interval to its successor on the same processor
exists to ensure that we can't develop "holes" in our state
-- a hole would imply wasted checkpoints -- those before the
hole would be useless.
The edge from a receiver to the sender shows the dependency of
the sender on the receiver. Remember that the arrow goes the
opposite way in the IDG than it did when we showed the message
being sent earlier -- this is because the sender is dependent
on the receiver, not the other way around. If other actions
generate dependencies, they can be represented the same way.
Where is this graph stored? Each processor keeps the nodes and edges
that are associated with it.
If messages contain sequence numbers, we can use them to keep
track of who has sent us messages since our last checkpoint.
Each time we make a checkpoint, we send a message to each
processor that has sent us messages since the last time we
checkpointed -- we depend on these processors.
When these processors receive our message, they check to see if
they have checkpointed since the last time they sent us a message.
If not, they create a checkpoint, to satisfy our dependency in the
event of a failure.