Return to the lecture notes index
Lecture 3 (January 20, 2009)
Scheduling Basics
Scheduling the access of processes to non-sharable resources is a
fundamental part of an operating system's job. The same is
true of the thread scheduler withina user-level thread library.
The CPU is the most important among these resource, because it typically
has the highest contention. The high cost of additional CPUs, both in terms
of the price of the processor and the cost of the technology in massively
parallel systems, ensures that most systems don't have a sufficient surpless
of CPUs to allow for their wasteful use.
The primary objective of CPU scheduling is to ensure that as many jobs
are running at a time as is possible. On a single-CPU system, the goal
is to keep one job running at all times.
Multiprogramming allows us to keep many jobs ready to run at all times.
Although we can not concurrently run more jobs than we have available
processors, we can allow each processor to be running one job, while
other jobs are waiting for I/O or other events.
Observation: The CPU-I/O Burst Cycle
During our discussion of scheduling, I may make reference to the
CPU-I/O burst cycle. This is a reference to the observation that
programs usually have a burst of I/O (when the collect data) followed
by a burst of CPU (when they process it and request more). These bursts
form a cycle of execution.
Some processes have long bursts of CPU usage, followed by short bursts of
I/O. We say that thee jobs are CPU Bound.
Some processes have long bursts of I/O, followed by short bursts of
CPU. We say that thee jobs are I/O Bound.
The CPU Scheduler
Some schedulers are only invoked after a job finishes executing or
voluntarily yield the CPU. This type of scheduler is called a
non-premptive scheduler.
- A process blocks itself waiting for a resource or event
- A process terminates
But, in order to support interaction, most modern schedulers are
premeptive. They make use of a hardware timer to interrupt running
jobs. When a scheduler hardware interrupt occurs, the scheduler's
ISR is invoked and it runs. When this happens, it can continue the
previous task or run another. Before starting a new job, the
scheduler sets the hardware timer to generate an interrupt after
a particular amount of time. This time is known as the time
quantum. It is the amount of time that a job can run without
interruption.
A preemptive scheduler may be invoked under the following four
circumstances:
- A process blocks itself waiting for a resource or event
- A process terminates
- A process moves from running to ready (interrupt)
- A process moves from waiting to ready (blocking condition satisfied)
The Dispatcher
Once the CPU scheduler selects a process for execution, it is the job of
the dispatcher to start the selected process. Starting this process
involves three steps:
- Switching context
- Switching to user mode
- Jumping to the proper location in the program to start or
resume execution
The latency introduced by the dispatch is called the dispatch
latency. Obviously, this should be as small as possible -- but is
most critical in real-time system, those systems that must
meet deadlines associated with real world events. These systems are
often associted with manufacturing systems, monitoring systems, &c.
Actually, admission is also much more important in these systems --
a job isn't automically admitted, it is only admitted if the system
can verify that enough resources are available to meet the deadlines
associated with the job. But real-time systems are a different story
-- back to today's tale.
Scheduling Algorithms
So, given a collection of tasks, how might the OS (or the
user-level thread scheduler) decide which to place on an available CPU?
First Come, First Serve (FCFS)
First In, First Out (FIFO)
FCFS is the simplest algorithm. It should make sense to anyone who has
waited in line at the deli, bank, or check-out line, or to anyone
who has ever called a customer service telephone number, "Your
call will be answered in the order in which it was received."
The approach is very simple. When a job is submitted, it enters the ready
queue. The oldest job (has been in the ready queue for the longest time)
in the ready queue is always selected to be dispatched. The algorithm is
non-premptive, so the job will run until it voluntarily gives up the CPU
by blocking or terminating. After a blocked process is satisfied and
returns to the ready queue, it enters at the end of the line.
This algorithm is very easy to implement, and it is also very fair and
consequently starvation-free. No characteristic of a job bias its
placement in the queue. But it does have several disadvantages.
- Because short jobs can be scheduled after very long jobs,
the average wait time can be increased. Unlike the grocery
store, the algorithm has no "Express Lane."
- Since the algorithm is non-premptive, there can be problems
on interactive systems. A long job may prevent responsiveness
to the user.
- A student actually pointed out this more subtle property
during class in the form of a question (good job!)
It is possible for one CPU bound process to hog the CPU for
a long time. In the meantime several I/O bound processes, that
could execute concurrently with the CPU-bound process, can't
start.
I didn't give this phenomenon a name in class, but
I probably should have -- it is called the convoy effect,
because cycle after cycle, the I/O bound processes will "follow"
the CPU bound processes, without overlapping.
Shortest-Job-First (SJF)
Another apporach is to consider the expected length of each processes's
next CPU burst and to run the process with the shortest burst next. This
algorithm optimizes the average waiting time of the processes. This is
because moving a shorter job ahead of a longer job helps the shorter
job more than it hurts the longer job. Recall my lunchroom story --
those who ate early had no lines, although there wasn't anyone to
vouch for this.
Unfortunately, we have no good way of knowing for sure the length of any
jobs next CPU burst. In practice this can be estimated using an exponential
average of the jobs recent CPU usage. In the past, programmers estimated
it -- but if their jobs went over their estimate, they were killed.
programmers got very good at "The Price Is Right."
Sometimes this algorithm is premeptive. A job can be prempted if another
job arrives that has a shorter execution time. This is flavor is often
called shortest-remaining-time-first (SRTF).
Shortest-Time-To-Completion-First (STCF)
Shortest CPU time to Completion First (STCF). The process that will
complete first runs whenever possible. The other processes only run
when the first process is busy with an I/O event.
But, much like SJF, the CPU time is not known in advance.
Priority Scheduling (PRI)
Priority scheduling is designed to strictly enforce the goals of a system.
Important jobs always run before less important jobs. If this scheduling
discipline is implemented preemeptively, more important jobs will preempt
less important jobs, even if they are currently running.
The bigest problem with priority-based scheduling is starvation.
it is possible that low priority jobs will never execute, if more
important jobs continually arrive.
Round Robin Scheduling (RR)
Round Robin scheduling can be thought of as a preemptive version of FCFS.
Jobs are processed in a FCFS order from the run queue. As with FCFS,
if they block, the next process can be scheduled. And when a blocked
process returns to the ready queue, it is placed at the end of the list.
The difference is that each process is given a time quantum or
time slice. A hardware timer interrupt preemept the running
process, if it is still running after this fixed amount of time.
The scheduler can then dispatch the next process in the queue.
With an appropriate time quantum, this process offeres a better
average case performance than FCFS without the guesswork of SJF.
If the time quantum is very, very small, an interesting effect is
produced. If there are N processes, each process executes as if
it were running on its own private CPU running at 1/N th the speed.
This effect is called processor sharing.
If the time quantum is very, very large -- large enough that the
processes generally complete before it expires, this approach
approximates FCFS.
The time quantum can be selected to balance the two effects.
Bonus Material
Everything in this section goes above and beyond lecture. It is just here
for those who happen to be curious for more real-world detail.
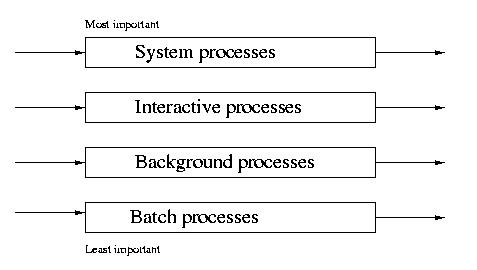
Multilevel Queue Scheduling (MQS)
MQS is similar to PRI, except that the jobs arrive sorted by their
priority. For example, all system jobs may have a higher priority than
interactive jobs, which enjoy a higher priority than batch jobs.
Jobs of different priorities are placed into different queues.
In some implementations, jobs in all higher priority queues must be
executed before jobs in any lower priority queue. This absolute approach
can lead to starvation in the same way as its simplier cousin, PRI.
In some preemptive implementations, a lower-priority process will be
returned to its ready queue, if a higher-priority process arrives.
Another approach is to time-slice among the queues. Higher priority
queus can be given longer or more frequent time slices. This approach
prevents absolute starvation.
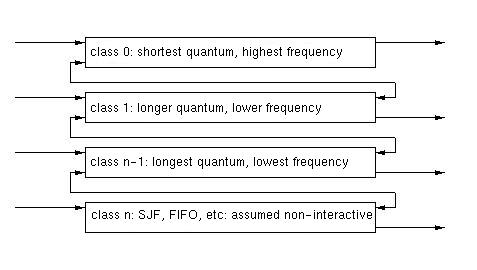
Multilevel Feedback Queue (MFQ)
In the multilevel queuing system we described above, there is no social
mobility. When aprocess arrives, it is placed in a queue based on its
initial classification. It remains in this queue throughout its lifetime.
In a MFQ system, a process's priority can change as the result of its CPU
utilization. Processes that have longer CPU bursts are lowered in
importance. Processes that are I/O bound and frequently release the CPU
prematurely by blocking are increased in importance.
This system prevents starvation and gives I/O bound processes the change
to be dispatched and overlap with CPU bound processes. It fights the
convoy effect.
Scheduling among queues can be done by varying the lenght or frequence
of the time slice. Scheduling within each queue can also be varied.
Although this system sounds very pretty, it is very complex. In general
this type of system is defined by the following parameters:
- the number of queues
- the method of scheduling for each queue
- the method of scheudling among the queues
- the method of promoting a process
- the method of demoting a process
Traditional UNIX Scheduling - Introduction
I thought it would be interesting to spend some time considering
scheduling in a real-world operating system. Today we'll talk about what
I call "traditional" UNIX scheduling. This scheduling system was used,
with little variation through AT&T SVR3 and 4.3BSD. Newer UNIX's use
more sophisticated approaches, but this is a good place to start.
Priorities
The scheduling in these systems was priority based. The priority of a
process ranged from 0 - 127. Counterintuitively, lower priorities
represent more important processes.
The range of priorities is partitioned. Priorities in the range of
0 - 49 are reserved for system processes. Both user and system processes
may have priorities over the full range from 0 - 127. Ths prevents
user processes from interfereing with more important system tasks.
Parameters
A processes ultimate scheduling priority varies with several factors.
The accounting of these factors is kept in the proc structure,
which contains the following fields:
- p_pri - current scheduling priority
- p_usrpri - the process's priority in user mode
- p_cpu - a measure of the prcoess's recent CPU usage
- p_nice - a user supplied measure of the process's importance.
Elevated Priority in System Mode
p_pri is a number in the range of 0 - 127 that represents the
priority of the process. This is the value of that the scheduler considers
when selecting a process to be dispatched. This value is normally the
same as p_usrpri. It however, may be lowered (making the process more
important) while the process is making a system call.
Traditional UNIX systems did not have preemptive kernels. This meant that
only one process could be in the kernel at a time. If a process blocked
while in a system call, other user processes could run, but not other
system calls or functions. For this reason a process which had blocked
while in a system call often would have its p_pri value lowered so
that it would expeditiously complete its work in the kernel and return
to user mode. This allowed other processes that blocked waiting to enter
the kernel to make progress. Once the system call is complete, the
process's p_pri is reset to its p_usrpri.
User Mode Priority
The priority that a process within the kernel receives after returning
from the blocked queue is called its sleep priority. There is
a specific sleep priority associated with every blocking condition.
For example, the sleep priority associated with terminal I/O was
28 and disk I/0 was 20.
The user mode scheduling priority depends on three factors:
- the default user mode priority, PUSER, typically 50
- the process's recent CPU usuage, p_cpu
- the nice value assigned by the user, p_nice
The p_usr value is a system-wide default. In most implementations it
was 50, indicating the most important level of scheduling for a user
process.
Let's be Nice
The p_nice value defaults to 0, but can be increased by users who
want to be nice. Remember that the likelihood of a process to be dispatched
is inversly proportional to the priority. By increasing the process's
nice value, the process is deacreasing its likelihood of being scheduled.
Processes are usually "niced" if they are long-running, non-interactive
backgorund processes.
Tracking CPU usage
p_cpu is a measure of the process's recent CPU usage. It ranges from
0 - 127 and is initially 0. Ever 1/10th of a second, the ISR that handles
clock ticks increments the p_cpu for the current process.
Every 1 second another ISR decreases the p_cpu of all processes, running
or not. This reduction is called the decay. SVR3 used a fixed
decay of 1/2. The problem with a fixed decay is that it elevates the
priority of nearly all processes if the load is very high, since very
few processes are getting CPU. This makes the p_cpu field nearly meaningless.
The designers of 4.3BSD remedied this side-effect by using a variable decay
that is a fuction of the systems load average, the average number
of processes in the run queue over the last second. This formula follows:
decay_factor = (2*load_average)/ (2*load_average + 1)
User Mode Priority - Final Formula
The scheduler computes the process's user priority form these factors
as follows:
p_usrpri = PUSER + (p_cpu/4) + (2*p_nice)
Implementation
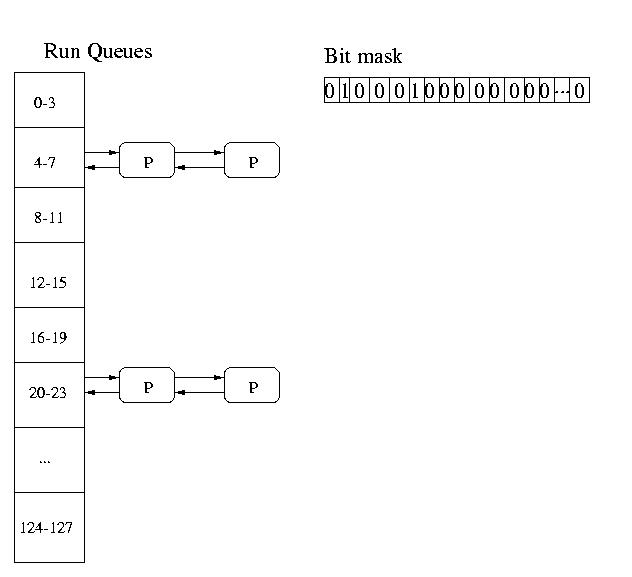
Artifacts of the old DEC VAX systems made it much more efficient
to collapse the 127 priorities into 32 queues. So these systems
in effect had 32 queues each holding processes in a range of
4 priority levels (0-3, 4-7, 8-11, 12-15, 16-19, etc).
The system maintained a 32-bit mask. Each bit represented a single
queue. If the bit was set, there were jobs in the queue. If the bit was 0,
the queue was empty. The system charged from low-bit to high-bit in this
mask until it found a non-empty queue. It would then select a job
Round Robin (RR) from this queue to be dispatched.
The round-robin scheduling with a time quantum of 100mS only applied to
processes in the same queue. If a process arrived in a lower priority
(more important) queue, that process would be scheduled at the end
of the currently executing process's quantum.
High priority (less important) processes would not execute until all
lower priority (more important) queues were empty.
The queues would be check by means of the bit mask every time a process
blocked or a time quantum expired.
Analysis
This method of scheduling proved viable for general purpose systems,
but it does have several limitations:
- it falls apart with a massive number of processes - the
overhead of recomputing priorities for every process every second
becomes too high
- nice values are a very weak and underutilized way for applications
to affect their priorities -- how often doyou nice your jobs?
- A non-preemptive kernel means that important processes may have to
wait for lower priority processes in the kernel. The temporary
sleep priority is a weak solution.