Return to lecture notes index
June 4, 2014 (Lecture 8)
Coordinator Election: Introduction
Many of the approaches that we've discussed to distributed
computing involve a "special" machine that has a unique role
or purpose within the system. In the past, we've said that
the special machine is "appointed" by an administrator, or,
to improve availability can be "elected." Although we've never
described the process, we did say that elections typicaly occured
initially, and/or in the event of a failed coordinator.
Today, we're going to discuss how coordinators are "elected."
Please note this very subtle distinction in nomenclature --
"voting" is used in the context of synchronization; "election"
is used in the context of coordinator selection.
The similarity in the two is more than skin deep. Each process
selects one machine from many. There are two key differences:
- When it comes to synchronization, the selected process needs to
know that it can enter the critical section, and the other
processes need to know that they cannot enter the critical section.
But it is not necessary for any process, other than the selected
process, to know who has been selected.
In contrast, all participants must know which process is the
coordinator.
- When it came to synchronization, we discuss fault tolerance,
but only as an issue of secondary importance. In reality,
none of the approaches were terribly robust (failure w/in critical
section, &c).
But election is a process that is typically used in the event of
failure -- otherwise an "appointed" coordinator would suffice.
So fault tolerance is of primary importance in coordinator election.
Both of the election algorithms that we will discuss will assume that
version numbers, &c are stored on a stable store and can be restored after
a crash. Stable store bight be a hard drive, network drive, non-volatile
RAM, &c. This assumption is typical for election algorithms, even those
that we don't discuss.
The Bully Algorithm (Garcia-Molina '82)
This approach makes some somewhat fairytale-like assumptions:
- All messages are delivered within some Tm units of time,
called the message propogation time.
- Once a message is received, the reply will be dispatched within
some Tp units of time, called the message handling
time.
- Tp and Tm are known.
These are nice, because together they imply that if a response is
is not received within (2*TM + Tp) units of time
the process or connection has failed. But, of course, in the real
world congestion, load, and the indeterminate nature of most networks
make this a bit of a reach.
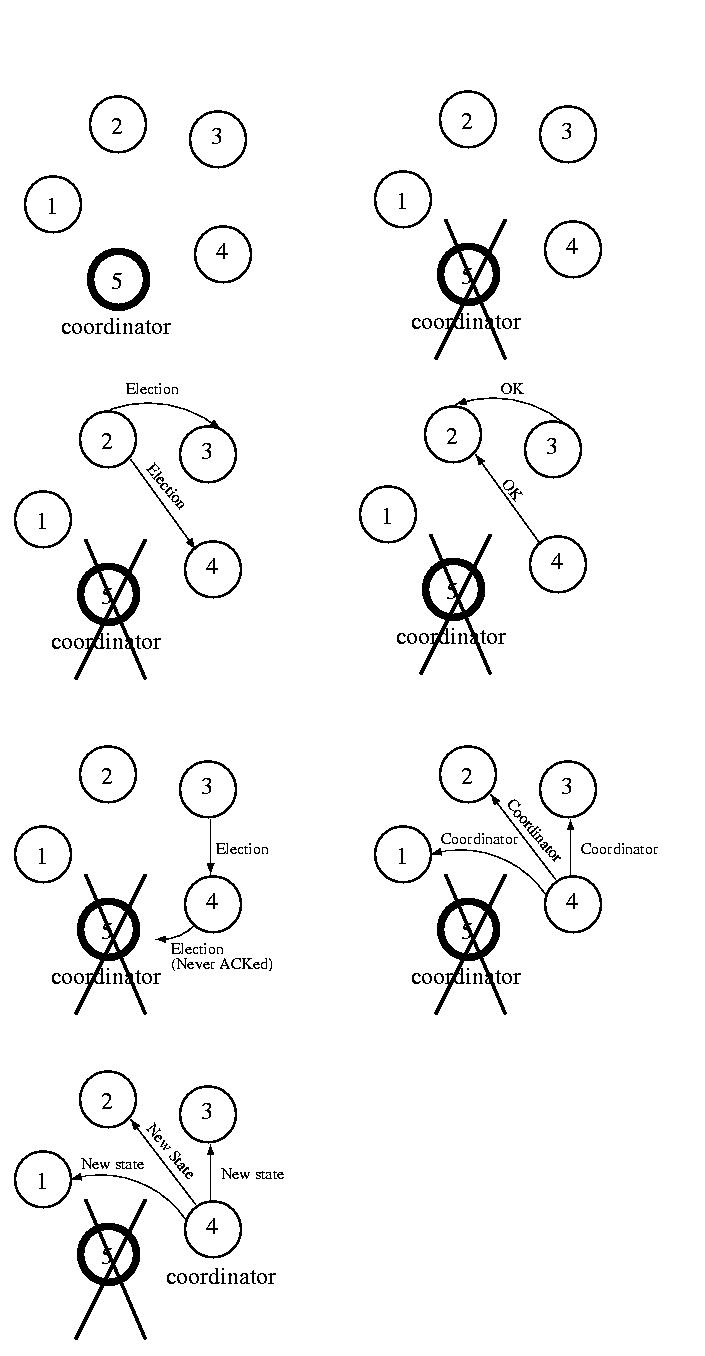
The idea behind the Bully Algorithm is to elect the highest-numbered
processor as the coordinator. If any host thinks that the coordinator
has failed, it tries to elect itself by sending a message to the
higher-numbered processors. If any of them answer it loses the election.
At this point Each of these processors will call an election and try to
win themselves.
If none of the higher-ups answer, the processor is the highest numbered
processor, so it should be the coordinator. So it sends the lower level
processors a message declaring itself the boss. After they answer (or
the ACK of a reliable protocol), it sends them the new state of the
coordinated task. Now everyone agrees about the coordinator and the
state of the task.
If a new processor arrives, or recovers from a failure, it gets the state
from the current coordinator and then calls an election.
The Invitation Algorithm
Let's assume that in practice communication failure, high latency,
and/or congestion can partition a network. Let's also assume that
a collection of processors, under the direction of a coordinator, can
perform useful work, even if other such groups exist.
Now what we have is an arrangement such that each group of processors
that can communicate among themselves is directed by a coordinator, but
different groups of processors, each operating under the direction of
a different coordinator, can co-exist.
The Invitation Algorithm provides a protocol for forming groups
of available processors within partitions, and then creating larger
groups as failed processors are returned to service or network partitions
are rectified.
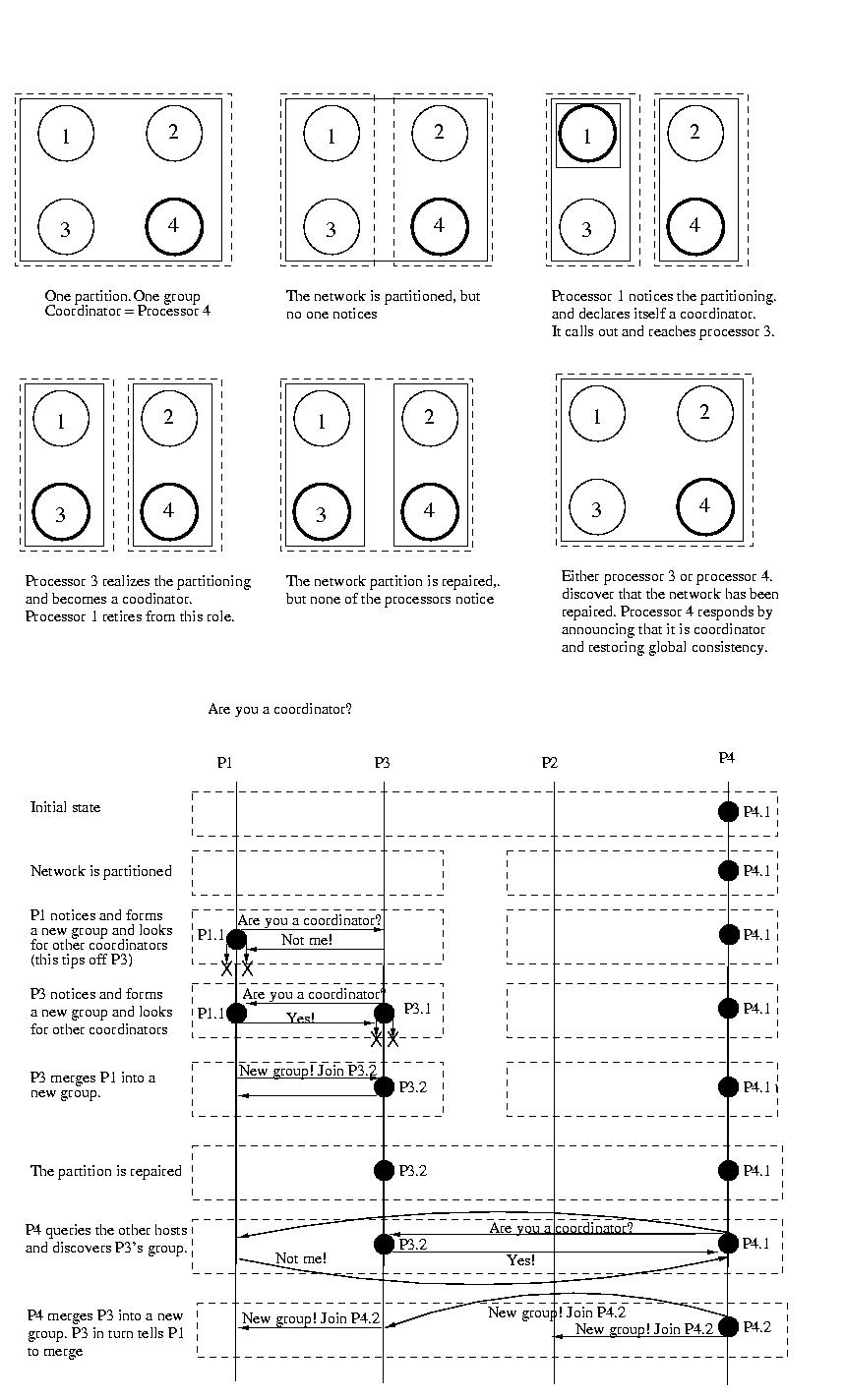
The Invitation Algorithm organizes processors into groups. Ideally all
processors would be a member of the same group. But network partitions,
and high latencies yielding apparent partitions, may make this impossible
or impractical, so multiple groups may exist. Each functioning processor
is a member of exactly one group.
A new group may be formed to perform a new task, because the coordinator
of an existing group has become unavailable, or because a previously
unreachable group has been discovered. Groups are named using a group
number. The group number is unique among all groups, is changed
every time a new group is formed, and is never reused. To accomplish this,
the group number might be a simple sequence number attached to the processor
ID. The sequence number component can be incremented each time the
processor becomes the coordinator of a new group.
Since the goal is to have all functioning processors working together in
the same group, the groups that resulted from network partitioning
should be merged once the partition is repaired. This merging is
orchestrated by the coordinators. The goal of every coordinator is to
discover other coordinators, if they are accessible. To achieve this
coordinators "yell out" perodically to each processor asking each if it
is a coordinator. Most processors, the participants, reply indicating
that they are not a coordinator. It is possible that some coordinators
are unreachable or don't reply before some timeout period -- that's okay,
they are perceived to be non-existent or operating in a separate partition.
Once one coordinator has identified other reachable coordinators, the goal
is for the coordinators to merge their groups of processors into one
group coordinated by one coordinator. Usually, it is acceptable to say
that the coordinator that initiated the merge will be the coordinator of
the new group. But it might be the case that two or more coordinators were
concurrently looking for other coordinators and that their messages may
arrive in different orders. To handle this situation, there should be some
priority among the coordinators -- some method to determine which of
the perhaps many coordinators should take over.
One way of doing this might be to use the processor ID to act as a priority.
Perhaps higher-numbered processors ignore queries from lower-level
processors. This would allow lower-level processors to merge the groups
with lower priority coordinators during this operation. At some later time
the higher-level coordinators will each act to discover other coordinators
and merge these lower-priority groups. Perhaps receiving the query will
prompt the higher-level coordinator to try to merge its group with others
sooner than it otherwise might. An alternative would be for a coordinator
only to try to merge lower-level coordinators.
Or perhaps processors delay some amount of time between the time that they
look for other coordinators and the time that they start to merge these
groups. This would allow time for a higher-priority coordinator to
search for other coordinators (it knows that there is at least one) and
ask them to merge into its group. If after such a delay, the old coordinator
finds itself in a new group, it stops and accepts its new role as a
participant. In this case, it might be useful to make the delay inversely
proportional to one's priority. For example, there is no reason for the
highest-priority processor to delay. But the lowest priority processor might
want to delay for a long time.
In either case, once the merging of groups begins, processing the
the affected groups should be halted -- the state may be inconsistent.
The coordinator that started the merge operation will become the
coordinator of the new group. It should increment the sequence number of
the group ID and tell the participants in its old group. It should also
tell the coordinators that it discovered to merge their partiticpants, and
themselves, into the new group.
Once this is done, the new coordinator should coordinate the state of the
partipants, and processing can be re-enabled.
If a node discovers that its coodinator has failed, is newly installed,
or returns to service after a failure, it forms a new group containing only
itself and becomes the coordinator of this group. It then searches for other
groups and tries to merge with them as described above.
This approach is really very simple. Periodically coordinators look for
other coordinators. If they find other coordinators, they invite them
to merge into a new. If they accept the invitation, the coordinators
tell their participants to move into the new group and move into the
new group themselves. In this way, groups can be merged into a single
group.
As discussed earlier, the state is consistent within a group, but isn't
consistent among groups -- nor does it need to be. This algorithm does not
provided global consistency, just relative consistency -- consistency within
each group. As such, it is useful is systems where this type of
asynchronous processing is acceptable.
For example, a coordinator might ensure that participants attack
non-overlapping portions of a problem to ensure the maximum amount of
parallelization. If there are multiple coordinators, the several groups
may waste time doing the same work. In this case, the merge process would
throw out the duplicate work and assemble the partial results. Admittedly,
it would be better to avoid duplicating effort -- but the optimism might
allow some non-overlapping work to get done.
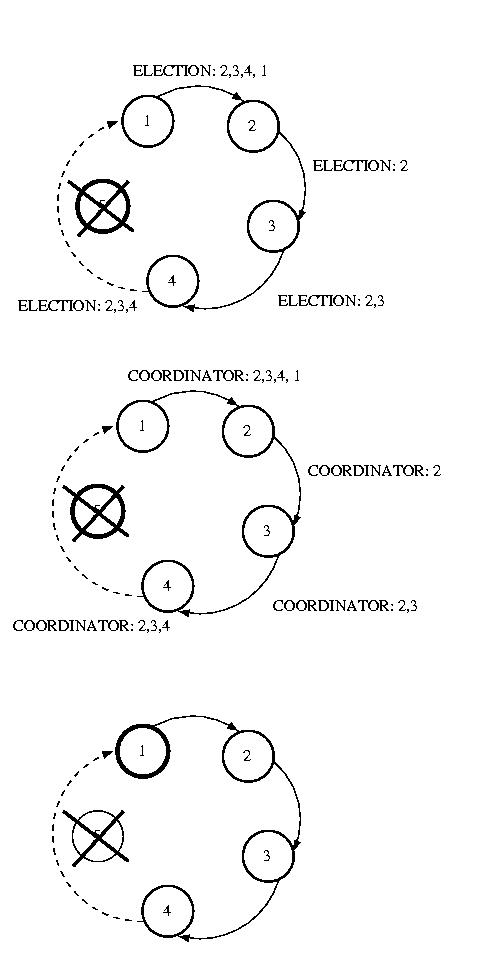
Ring Election
Another approach, Ring election, is very similar to token ring
synchronization, except no token is used. We assume that each processor
is logically ordered, perhaps by IP address, so that each processor
knows its successor, and its successor's successor, and so on. Each
processor must know the entire logical structure.
When a processor discovers that the coordinator has died, it starts
circulating an ELECTION message around the ring. Each node advances
it in logical order, skipping failed nodes as necessary. Each node
adds thier node number to the list. Once this message has made its
way all the way around the ring, the message which started it will
see its own number in the list. It then considers the node with the
highest number to be the coordinator, and this messages is circulated.
Each receiving node does the same thing. Once this message has made
its way around the ring, it is removed.
If multiple nodes concurrently discover a failed coordinator, each
will start an ELECTION. This isn't a problem, because each election
will select the same coordinator. The extra messages are wasted overhead,
while this isn't optimal, it isn't deadly, either.
The bully algorithm is simply, but this is because it operates under the
simplistic assumption that failures can be accurately detect failures.
It also assumes that failures are processor failures -- not network
partitions. In the event of a partitioning, or even a slow network and/or
processor, more than one coordinator can be elected. Of course, the timeout
can be be set large enough to avoid electing multiple processors due to
delay -- but an infinitely large timeout would be required to reduce this
proability to zero. Longer timeouts imply wasted time in the event of
failure.
ACID Transactions
Traditional database systems have relied upon bundling work into
transactions that have the ACID properties. In so doing,
they guarantee consistency at the expense of availability and/or
partition tolerance.
ACID is an acronym for:
- Atomicity
- Consistency (serializability)
- Isolation
- Durability
- Acid - "All or nothing"
- Consistency -- This implies two types of consistency. It implies
that a single system is consistent and that there
is consistency across systems. In other words,
if $100 is moved from one bank account to another,
not only is it subtracted from one and added to
another on one host -- it appears this way everywhere.
It is this property that allows one transaction to
safely follow another.
- Isolation - Regardless of the level of concurrency, transactions
must yields the same results as if they were executed
one at a time (but any one of perhaps several orderings).
- Durability - permanance. Changes persist over crashes, &c.
Transactions, Detail and Example
Transactions are sequences of actions such that all
of the operations within the transaction succeed (on all recipients)
and their effects are permanantly visible, or none of none
of the operations suceed anywhere and they have no visible effects;
this might be because of failure (unintentional) or an abort (intentional).
Characterisitically, transactions have a commit point. This is the
point of no return. Before this point, we can undo a transaction. After this
point, all changes are permanant. If problems occur after the commit point,
we can take compensating or corrective action, but we can't wave a magic
wand and undo it.
Banking Example:
Plan:
A) Transfer $100 from savings to checking
B)Transfer $300 from money market to checking
C) Dispense $350
Transaction:
1. savings -= 100
2. checking += 100
3. moneymkt -= 300
4. checking += 300
5. verify: checking > 350
6. checking -= 350
7.
|
8. dispense 350
Notice that if a failure occurs after points 1 & 3 the
customer loses money.
If a failure occurs after points 2, 4, or 5, no money is lost,
but the collectiopn of operations cannot be repeated and the result
in not correct.
An explicit abort might be useful at point 6, if the test fails
(a negative balance before the operations?)
Point 7 is the commit point. Noticve that if a failure occurs after
point 7 (the ATM machine jams), only corrective action can be
taken. The problems can't be fixed by undoing the transaction.
Distributed Transactions and Atomic Commit Protocols
Often times a transaction will be distributed across several systems.
This might be the case if several replicas of a database must remain
uniform. To achieve this we need some way of ensuring that the
distributed transaction will be valid on all of the systems or none
of them. To achieve this, we will need an atomic commit protocol.
Or a set of rules, that if followed, will esnure that the transaction
commits everywhere or aborts everwhere.
Two Phase Commit (2PC)
The most commonly used atomic commit protocol is two-phase commit.
You may notice that is is very similar to the protocol that we used
for total order multicast. Whereas the multicast protocol used a
two-phase approach to allow the coordinator to select a commit time
based on information from the participants, two-phase commit lets the
coordinator select whether or not a transaction will be committed
or aborted based on information from the participants.
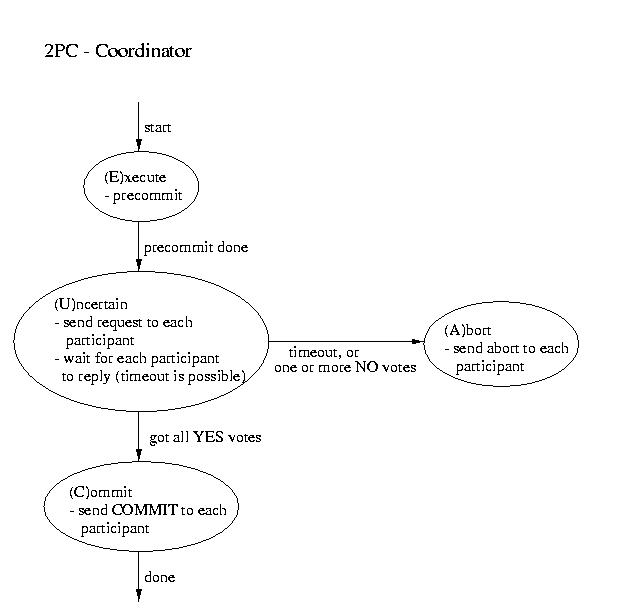
| Coordinator | Participant |
|---|
| ----------------------- Phase 1 ----------------------- |
|---|
- Precommit (write to log and.or atomic storage)
- Send request to all participants
|
- Wait for request
- Upon request, if ready:
- Precommit
- Send coordinator YES
- Upon request, if not ready:
|
Coordinator blocks waiting for ALL replies
(A time out is possible -- that would mandate an ABORT) |
|---|
| ----------------------- Phase 2 ----------------------- |
|---|
|
This is the point of no return!
- If all participants voted YES then send commit to
each participant
- Otherwise send ABORT to each participant
|
Wait for "the word" from the coordinator
- If COMMIT, then COMMIT (transaction becomes visible)
- If ABORT, then ABORT (gone for good)
|
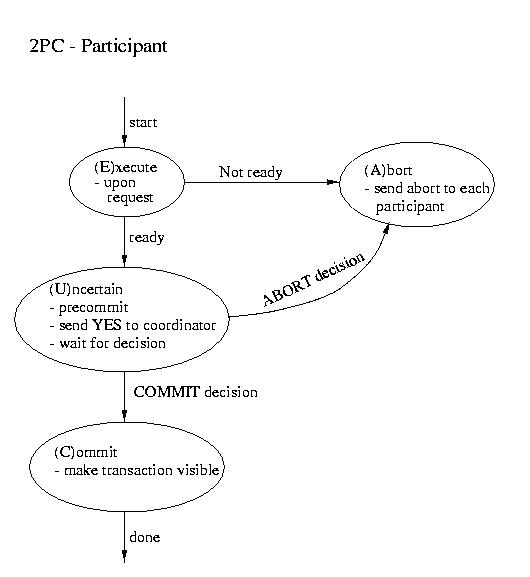
Three-phase Commit
Another real-world atomic commit protocol is three-pahse commit (3PC).
This protocol can reduce the amount of blocking and provide for more
flexible recovery in the event of failure. Although it is a better choice
in unusually failure-prone enviornments, its complexity makes 2PC the
more popular choice.
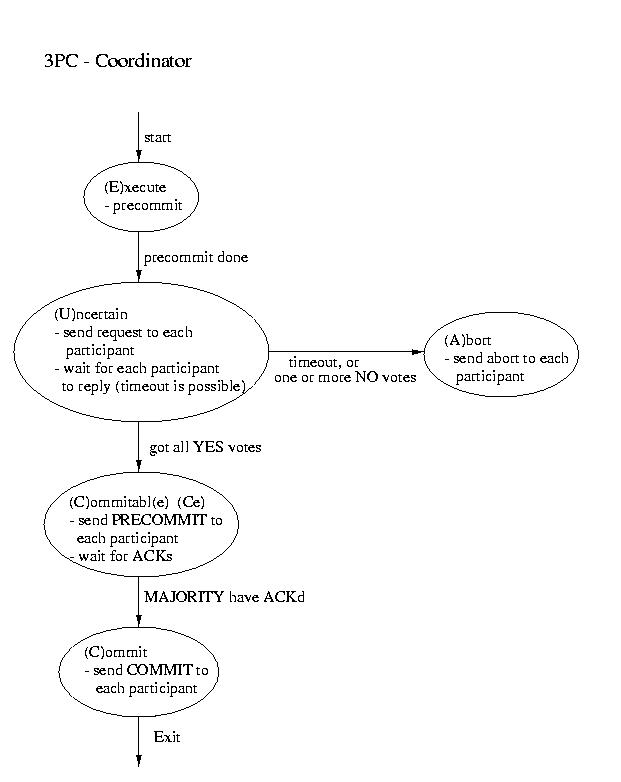
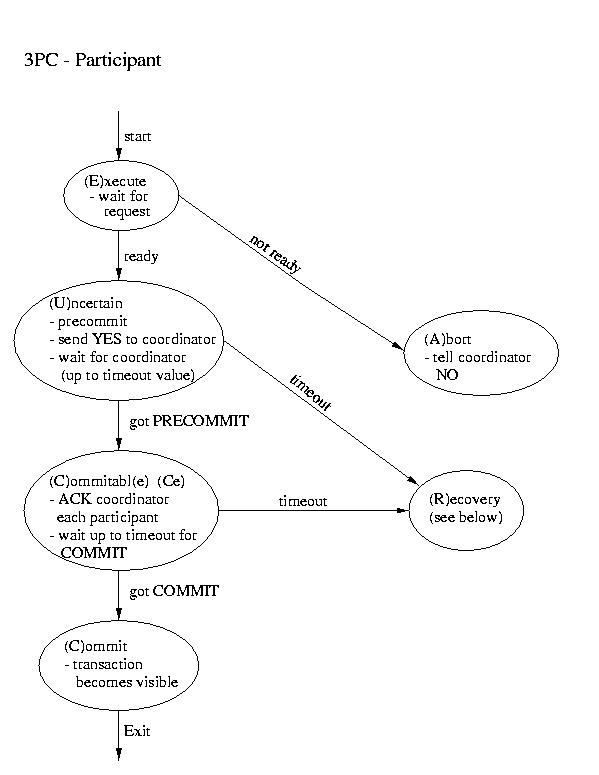
Recovery in 3PC
If the participant finds itself in the (R)ecovery state, it
assumes that the coordinator did not respond, because it failed. Although
this isn't a good thing, it may not prove to be fatal. If a majority
of the participants are in the uncertain and/or commitable states, it
may be possible to elect a new coordinator and continue.
We'll discuss how to elect a new coordinator in a few classes. So, for now,
let's just assume that this happens auto-magically. Once we have a new
coordinator, it polls the participants and acts accordingly:
- If any participant has aborted, it sends ABORTs to all
(This action is mandatory -- remember "all or none").
- If any participant has committed, it sends COMMIT to all.
(This action is mandatory -- remember "all or none").
- If at least one participant is in the commitable state
and a majority of the participants are commitable or
uncertain, send PRECOMMIT to each participant and proceed
with "the standard plan" to commit.
- If there are no committable participants, but more than half
are uncertain, send a PREABORT to all participants. Then
follow this up with a full-fledged ABORT when more than
half of the processes are in the abortable state. PRECOMMIT and
abortable are not shown above, but they are complimentary to
COMMIT and commitable. This action is necessary, because
an abort is the only safe action -- some process may have
aborted.
- If none of the above are true, block until more responses are
available.