Return to the index of lecture notes
July 29, 2014 (Lecture 23)
Peer-To-Peer Systems
We began class with a discussion about peer-to-peer models vs client-server
models. The upshot of the discussion is that the client-server model
generates a service hot-spot at the server and increasingly hot
network utilization the closer one gets to the server. Traffic that is
diffuse toward the client is concentrated near the serve.
Distributing the service helps. But, as long as clients out number servers,
there is a natural imbalance. The solution to this imbalance is a
peer-to-peer architecture where services are provided (hopefully, but not
likely) in proportion to their use.
Peer-to-Peer Challenges
Peer-to-peer systems present several challenges:
- Describing and searching for content
- Naming
- Finding objects and directory services
- Stability of the peers
- Trust of the peers
It becomes difficult to search for object in peer-to-peer systems,
because high-level searches don't localize well. For this type of thing,
we really do want a distributed map-reduce or toher parallel search
or large, in memory monolithic database, or both. We don't want to have
to ask a large number of distant peers and then need to coordinate the
results.
Naming needs to be universal. How do we know that there arne't multiple
"Greg Kesdens" in the world, or "Super Distributed Systems Textbooks"?
There are a lot of ways we could address this. And, we discussed some
in class, most of which could identify buckets of results. But, for the
rest of the discussion, we're going to assume everything is named by
a hash of the contents -- this way, the name (virtually) guarantees that
it identifies what we expect.
Once can identify each object we want, we need to find it. One option
is a fully distributed directory service (ouch!), another is a directory
service distributed among select peers (super peers?), and a third is
a distributed hash -- we're going to focus on that approach for the rest
of class.
Stability of peers is obviously an issue. Some peers will be well
resourced and stable, others will be thin and brittle. The stability
of the system depends upon haivng enough stable resources to mitgate the
impact of a smaller quantity of brittle resources. One common solution
here is to appoint willing, richer, more stable, longer-serving peers as
"super peers" and giving them more responsibility, perhaps incentivising
them by proving more or better service (or just by the good feeling from
being a good citizen).
Trust is the nearly impossible part. Insert the whole discussion about
public key infrastructure here. It is really challenging to trust the
identity of hosts. With luck, we can get a hash of what we want from
enough sources trusted enough to trust the answer -- and then we can
check that what we get matches the hash. Thus, the must brittle part
of this is really trusting the search results and/or human-name to
hash-name mapping.
Distributed Hashing: Consistent Hashing and Chords
Another idea for a peer-to-peer system is to implement a huge distributed
hash table. The problem with traditional hash tables, though, is that
they don't handle growth well. The hash function produces a large number,
which is then taken modulus the table size. As a result, the table size
can't change without needing to rehash the entire table -- otherwise the
keys can't be found.
A consistent hashing scheme is one that makes the hash value
independent of the table size. The result is that keys can be found, even
if the table size changes. In the contest of a distributed hash table, this
means that keys can be found, even if nodes enter (and possibly leave) the
system.
One technique for doing this is the Chord protocol. This protocol
views the world as a logical ring. Given an m bit key, it has
logical positions 0 ... 2m-1. Think of them as hours on a clock.
Some of these positions have actual nodes assigned to them, others do not.
Like token ring, each node "need" only know its successor, but actually
knows the topology of the entire ring in order to handle failures.
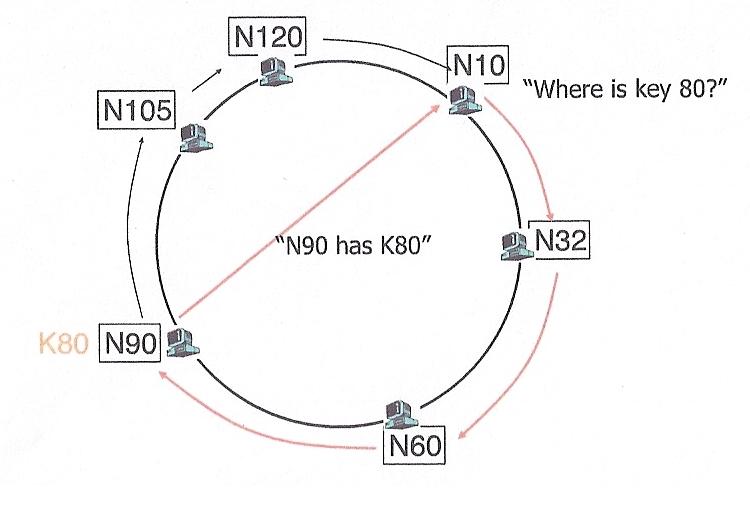
Since there are fewer nodes than actual addresses (hours on the clock),
each node can be responsible for more than one key. Keys are mapped to actual
nodes by assigning them to the "closest" node with an equal or greater number.
In order to find a key, we could do a brute fource search of the circle,
but instead each node keeps a "finger" pointing to the next node,
two nodes away, 4 nodes away, 8 nodes away, etc. In other words,
each node keeps pointer to nodes exponentially farther and farther away.
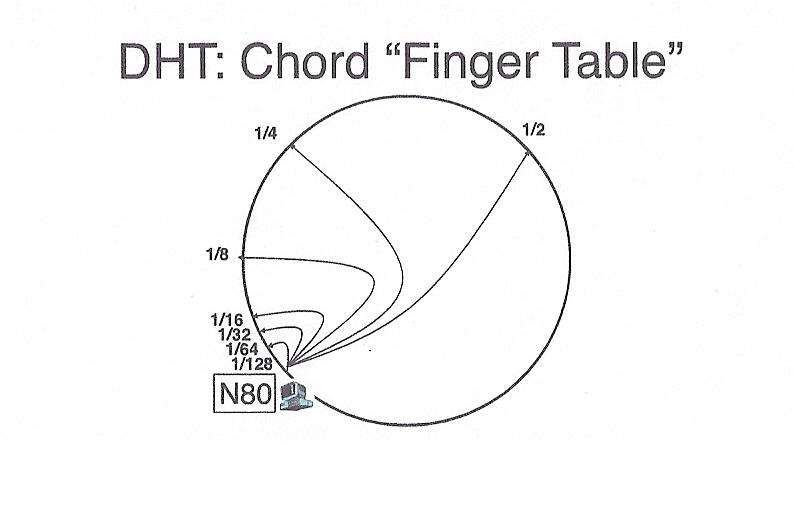
These pointers are stored in a table such that the ith entry of the
table contains a pointer to a node that is 2i away from it, e.g.
at position node_number + 2i. As with keys, if a node
is not present at the exact location -- the next greater node is used. This
arrangement makes it possible to search for a bucket in O(log n) time,
because, with each step, we either find the right node, or cut the search
space in half.
In order for a node to join, it simply is added to an unrepresented
position (hour on the clock) within the hash table. It gets its portion of
the keys from its successor, and then goes live. Similarly, disappearing
from the hash simply involves spilling ones keys to one's successor.
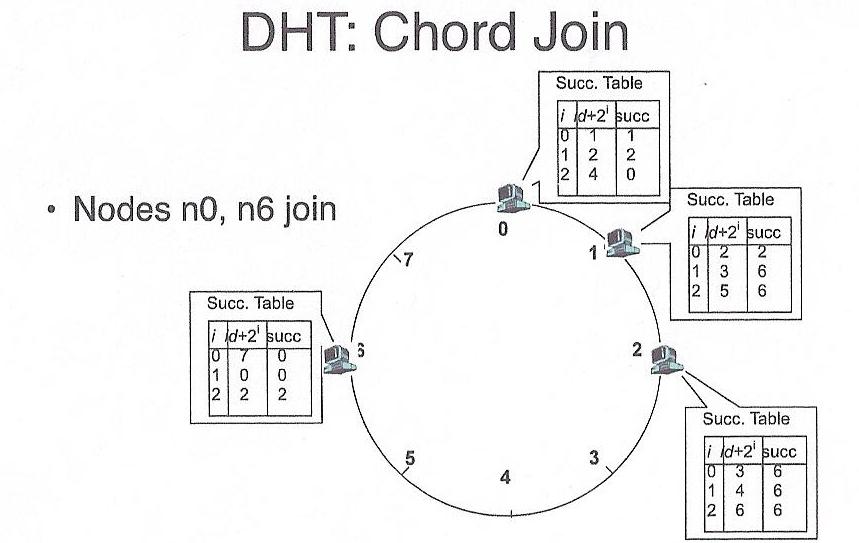
Credit: Thanks to Dave Anderson for these pictures!
LH* (Distributed Linear Hashing)
Linear Hashing is a technique for implementing a growable hash table
on disk. Given a hash value, viewed as a binary number, it starts out
using one bit, then two bits, then three bits, etc. As the table grows,
it uses additional bits. To make sure that the bits maintain their same
meaning as the table grows, it uses the bits from right-to-left, instead of
left-to-right. This way, as bits are added, they are the more-significant,
not less-significant bits. The result is that the one's bit stays the one's
bit, and the two's bit stays the two's bit, etc., they don't multiply as
more and more bits are used.
The other thing that is interesting is that, when an overflow occurs, it
isn't necessarily the overflowing bucket that splits. Instead, overflows
are interpreted as an indication that the table should grow, not an
immediately fatal condition. Think of them as soft "high water marks",
not fatal conditions -- they are resolved locally, somehow. So, when
an overflow occurs, the next bucket, in order, splits, adding one more
bucket. This is why the algorithm is known as "Linear hashing". The growth
is linear.
The "old" bucket knows to which node it split and can provide a reference.
Because things "wrap around" the address space eventually catching up with
all buckets, the maximum number of redirects is O(log n).
The growth of the table is illustrated below:

It is easy to see that this algorithm lends itself to distributed
implementations. Each bucket is a separate node. When an overflow
occurs, the overflowing node asks for help, like from a coordinator, but
possibly by broadcast or multicast. The new node then get the information
about where to split, from the same source, and makes it happen.
One distributed implementation is "LH*"
This is a much older approach than the Chord protocol. It is straight-forward
for nodes to join -- nodes leaving is, well, not so good.
Distributed Hashing and Fault Tolerance
Fault tolerance is likely managed (a) at the node level, and/or (b)
at the system level by replication. To solve this problem, you can
more-or-less apply what we've already learned about checkpointing,
logging, replication, etc.