Return to the lecture notes index
Lecture 2 (August 28, 2008)
Abstraction
We'll hear about many abstractions this semester -- we'll spend a great
deal of time discussing various abstractions and how to model them in
software. So what is an abstraction?
An abstraction is a representation of something that incorporates the
essential or relevent properties, while neglecting the irrelevant details.
Throughout this semester, we'll often consider something that exists in the
real world and then distill it to those properties that areof concern to us.
We'll often then take those properties and represent them as data structures
and algorithms that that represent the "real world" items within our software
systems.
The Task
The first abstraction that we'll consider is arguably the most important
-- a represention of the work that the system will do on behalf of a
user (or, perhpas, itself). I've used a lot of different words to describe
this so far: task, job, process, &c. But I've never been very specific about
what I've meant -- to be honest, I've been a bit sloppy.
This abstraction is typically called a task. In a slightly different
form, it is known as a process. We'll discuss the difference when we
discuss threads. The short version of the difference is that a task is
an abstraction that represents the instance of a program in execution, whereas
a process is a particular type fo task with only one thread of control.
But, for now, let's not worry about the difference.
If we say that a task is an instance of a program in execution, what
do we mean? What is an instance? What is a program? What do we mean by
execution?
A program is a specification. It contains defintions of what type fo data is stored, how it can be accessed, and a set of instructions that tells the computer
how to accomplish something useful. If we think of the program as a
specification, much like a C++ class, we can think of the task as an instance
of that class -- much like an object built from the specification provided by
the program.
So, what do we mean by "in execution?" We mean that the task is a real
"object" not a "class." Most importantly, the task has state
associated with it -- it is in the process of doing something or changing
somehow. Hundreds of tasks may be instances of the same program, yet they
might behave very differently. This happens because the tasks were
exposed to different stimuli and their changed accordingly.
Representing a Task in Software
How do we represent a task within the context of an operating system?
We build a data structure, sometimes known as a task_struct
or (for processes) a Process Control Block (PCB) that contains
all of the information our OS needs about the state of the task. This
includes, among many other things:
- content of registers (like the PC)
- content of the stack
- memory pages/segments
- open files
When a context switch occurs, it is this information that needs to be
saved and restored to change the executing process.
Task State
Just like people, tasks have lifestyles. They aren't always running and
they don't live forever. Typical UNIX systems view tasks as existing in
one of several states:
- New: Recently created
- Ready: Ready to run, but not yet assigned to a processor
- Running: Actually executing on a processor
- Waiting: Not currently executing. Not currently able to
execute. Won't be runnable until some specific
external event occurs, such as an I/O operation.
- Terminated: Done executing, won't accomplish anything else
useful or again be placed on a CPU.
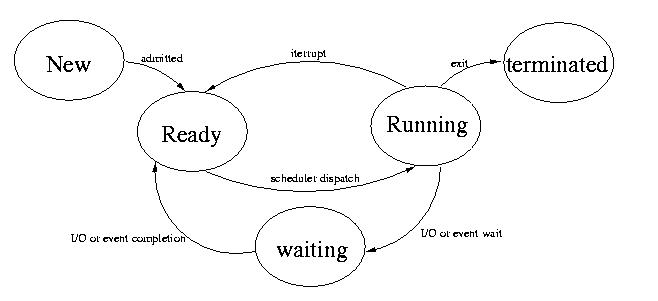
A task moves from the new state to ready state after it is created.
Once this happens, we say that the task is "admitted."
After the scheduler selects a task and assigns it to a processor, we say
that the task has been "dispatched."
When a task is done, it "exits." It is then in the terminated state.
If a task is waiting for an event, such as a disk read to complete,
it can "block" itself yielding the CPU. It is then in the "wait" state.
The system has many different wait queues -- not one universal wait
queue -- in fact, there is one wiat queue for each possible reason to
wait. This is because it would be very expensive to sift through a long
list each time a resource became available or other event occured. It
is not a case of needing a list of lists, either -- since each list is
associated with the event, it doesn't require any searching -- if we
take care of the queue when we handle the event, we're already in the
right place.
After the event occurs, the operating system can move it to the "ready"
state.
After a task has exhausted its time slice, it can be moved into the ready
state to allow another task access to the processor.
Please pay careful attention. The operating system is responsible for
creating tasks, dispatching them, readying them after an event, and
interrupting them after their time expires. Tasks must exit and block
voluntarily.
Creating New Tasks
One of the functions of the operating system is to provide a mechanism for
existing tasks to create new tasks. When this happens, we call the original
task the parent. The new task is called the child. It is possible for one
task to have many children. In fact, even the children can have children.
In UNIX, child tasks can either share resources with the parent or obtain
new resources. But existing resources are not partitioned.
In UNIX when a new task is created, the child is a clone of the parent.
The new task can either continue to execute with a copy of the parent
image, or load another image. Well talk more about this soon, when we talk
about the fork() and exec-family() of calls.
After a new task is created, the parent may either wait for the child to
finish or continue and execute concurrently (real or imaginary) with
the child.
Task Termination
A child may end as the result of the normal completion, it may be
terminated by the operating system for "breaking the rules", or it might be
killed by the parent. Often times parents will kill their children before
they themselves exit, or when their function is no longer required.
In UNIX, when a task terminates, it enters the defunct state. It remains in
this state until the parent recognizes the fact that it has ended via the
wait-family() of calls. Although a defuct task has given up most of its
resources, much of the state information is preserved so that the parent
can find out the circumstances of the child's death.
In UNIX children can outlive their parents. When this happens, there is a
small complication. The parent is not around to acknowlege the child's death.
A dead process is known as a zombie if its parent has already died.
The init process waits for all zombies, allowing for them to have a proper
burial. Sometimes zobies are known as orphans.
Fork -- A traditional implementation
fork() is the system call that is used to create a new task
on UNIX systems. In a traditional implementation, it creates a new task
by making a nearly exact copy of the parent. Why nearly exact?
Some things don't make sense to be duplicated exactly, the ID number,
for example.
The fork() call returns the ID of the child process in the parent
and 0 in the child. Other than this type of subtle differences, the two
tasks are very much alike. Execution picks up at the same point in both.
If execution picks up at the same point in both, how can fork() return
something different in each? The answer is very straightforward.
The stack is duplicated and a different value is placed on top of each.
(If you don't remeber what the stack is, don't worry, we'll talk about
it soon -- just realize that the return value is different).
The difference in the return value of the fork() is very significant.
Most programmers check the result of the fork in order to determine
whether they are currently the child or parent. Very often the child
and parent to very different things.
The Exec-family() of calls
Since the child will often serve a very different purpose that its
parent, it is often useful to replace the child's memory space, that
was cloned form the parent, with that of another program. By replace,
I am referring to the following process:
- Deallocate the process' memory space (memory pages, stack, etc).
- Allocate new resources
- Fill these resources with the state of a new process.
- (Some of the parent's state is preserved, the group id,
interrupt mask, and a few other items.)
Fork w/copy-on-write
Copying all of the pages of memory associated with a process is a
very expensive thing to do. It is even more expensive considering that
very often the first act of the child is to deallocate this recently
created space.
One alternative to a traditional fork implementation is called
copy-on-write. the details of this mechanism won't be completely
clear until we study memory management, but we can get the flavor now.
The basic idea is that we mark all of the parent's memory pages as
read-only, instead of duplicating them. If either the parent or
any child try to write to one of these read-only pages, a page-fault
occurs. At this point, a new copy of the page is created for the writing
process. This adds some overhead to page accesses, but saves us the
cost of unnecessarly copying pages.
vfork()
Another alternative is also available -- vfork(). vfork is even
faster, but can also be dangerous in the worng hands. With vfork(),
we do not duplicate or mark the parent's pages, we simply loan them, and
the stack frame to the child process. During this time, the parent
remains blocked (it can't use the pages). The dangerous part is this:
any changes the child makes will be seen by the aprent process.
vfork() is most useful when it is immediately followed by an exec_().
This is because an exec() will create a completely new process-space,
anyway. There is no reason to create a new task space for the child,
just to have it throw it away as part of an exec(). Instead, we can
loan it the parent's space long enough for it to get started (exec'd).
Although there are several (4) different functions in the exec-family,
the only difference is the way they are parameterizes; under-the-hood,
they all work identically (and are often one).
After a new task is created, the parent will often want
to wait for it (and any siblings) to finish. We discussed the
defunct and zombie states last class. The wait-family of
calls is used for this purpose.
The Conceptual Thread
In our discussion of tasks we said that a task
is an operating system abstraction that represents the state of a
program in execution. We learned that this state included such things as
the registers, the stack, the memory, and the program counter, as well
as software state such as "running," "blocked", &c. We also said that
the processes on a system compete for the systems resources, especially
the CPU(s).
Today we discussed another operating system abstraction called the
thread. A thread, like a task, represents a discrete piece
of work-in-progress. But unlike tasks, threads cooperate in their
use of resources and in fact share many of them.
We can think of a thread as a task within a task. Among other things
threads introduce concurrency into our programs -- many threads
of control may exist. Older operating systems didn't support
threads. Instead of tasks, they represented work with an abstraction
known as a process. The name process, e.g. first do ___,
then do ____, if x then do ____, finally do ____, suggests only
one thread of control. The name task, suggests a more general
abstraction. For historical reasons, colloquially we often say
process when we really mean task. From this point
forward I'll often say process when I mean task --
I'll draw our attention to the difference, if it is important.
A Process's Memory
Before we talk about how a tasks' memory is laid out, let's
first look at the simpler case of a process -- a task with
only one thread of control.
Please note that the heap grows upward through dynamic allocation
(like malloc) and the stack grows downward as stack frames are
added throguh function calls. Such things as return addresses, return
values, parameters, local variables, and other state are stored in
the runtime stack.
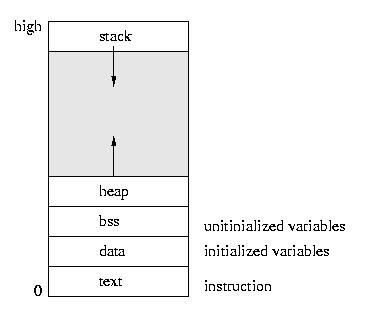
- The text area holds the program code.
- The data area holds global and static variables that must be
stored in the executible, since they are initialized.
- The bss area holds variables that are unitialized in the sense
that their need not be persistently stored on disk -- they can be
plugged in later.
The Implementation of Threads
All of the threads within a process exist within the context of that
process. They share the code section, data section, and operating system
resources such as open files.
But they do not share all resources. Since each thread executes
independently, each thread has its own understanding of the stack and of
the registers.
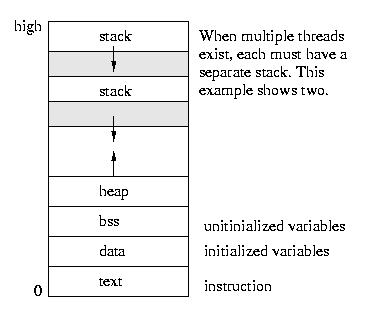
The good part about sharing so many resources is that switching
execution among threads is less expensive than it is among processes.
The bad part is that unlike the protection that exists among processes,
the operating system can not prevent threads from interfering with each
other -- they share the same process space.
Kernel Threads
The most primitive implementations of threads were invisible to the
user. They existed only within the kernel. Many of the kernel daemons,
such at the page daemon, were implemented as threads. Implementing
different operating system functions as threads made sense for many
reasons:
- There was no need for protection, since the kernel developers trust
themselves. Please note that we lose memory protection
once we go from processes to threads -- they all play in the
same address space.
- The different OS functions shared many of the kernel's resources
- They can be created and destroyed very cheaply, so they can be
easily used for things like I/O requests and other intermitent
activities.
- It is very cheap to switch among them to handle various tasks
- It is very easy to thing of kernel activities in terms of
separate threads instead of functions within one monolithic
kernel.
User Threads
But the UNIX developers couldn't keep such a great thing as their own
private secret for long. Users began to use threads via thread
libraries. Thread libraries gave users the illusion of
threads, without any involvement form the kernel. When a process
containing threads is executed, the thread scheduler, within the process,
is run. This scheduler selects which thread should run and for how long.
If a thread should block, the scheduler can select to run another thread
within the same process.
This implementation of threads is actually much more than an illusion. It
gives users the ability to write very efficient programs. These programs
can switch among threads and share resurces with very little overhead.
To switch threads, the registers must be saved and restored and the
stack must be switched. No expensive context switch is required.
Another advantage is that user level threads are implemented entirely
by a thread library -- from the interface to the scheduling. The kernel
doesn't see them or know about them.
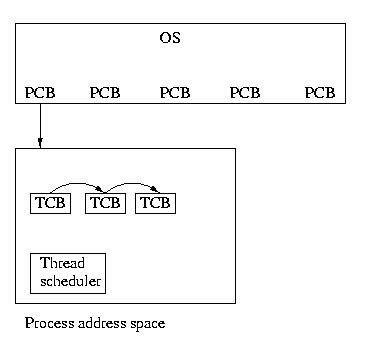
Kernel-Supported User-Level Threads
Kernel threads are great for kernel writers and user threads answer many
of the needs of users, but they are not perfect. Consider these examples:
- On a multiprocessor system, only one thread within a process
can execute at a time
- A process that consists of many threads, each of which may be
able to execute at any time, will not get any more CPU time
than a process containing only one thread
- If any thread within a process makes a system call, all threads
within that process will be blocked because of the context switch.
- If any user thread blocks waiting for I/O or a resource, the entire
process blocks. (Thread libraries usually replace blocking calls
with non-blocking calls whenever possible to mitigate this.)
To address these needs, we need to have a kernel supported user thread.
That is to say, we need a facility for threads to share resources within
a process, but we also need the ability of the kernel to preempt, schedule,
and dispatch threads. This type of thread is called a kernel supported
user thread or a light-weight process (LWP). A light-weight
process is in contrast with a heavy-weight process otherwise known
as a process or task.
Our model of the universe has gone from looking like this:
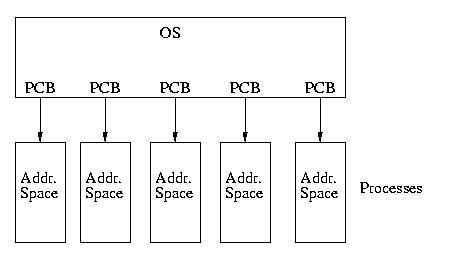
To looking like this:
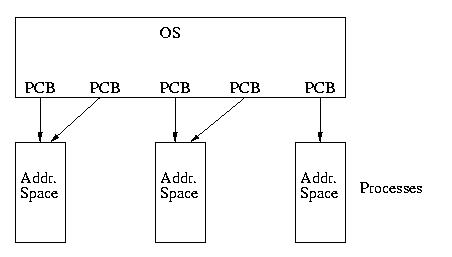
A More Complex Model
In some models, such as that used by Solaris, it is also possible to
assign several kernel-supported threads to a single process without
assigning them to specific user-level threads. In this case, the process
will have more opportunities to be seen by the OS's CPU scheduler. On
multiprocessor systems, the maximum level of concurrency is determined
by the number of LWPs assigned to the process (of course this is further
limited by the number of threads that are runnable within the process
and the number of available CPUs).
In the context of
Solaris, an LWP is a user-visible kernel thread. In some ways, it
might be better to view a Solaris LWP as a virtual light weight
processor (this is Kesden nomenclature!). This is because pools
of LWPs can be assigned to the same task. Threads within that task are
then scheduled to run on available LWPs, much like processes are scheduled
to run on available processors.
In truth, LWPs are anything but light weight. They are lighter weight
than (heavy weight) processes -- but they require far more overhead
than user-level threads without kernel support. Context-switching among
user-level threads within a process is much, much cheaper than context
switching among LWPs. But, switching among LWPs can lead to greater
concurrency for a task when user-level threads block within the kernel
(as opposed to within the process such that the thread scheduler can run
another).
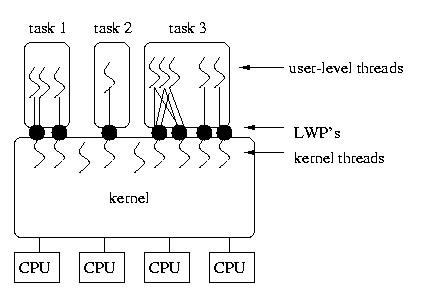
The diagram below shows LWP's associated with tasks and kernel threads, as
well as kernel threads without an associated LWP and several different
associations between user-level threads and the LWP(s) assigned to the
process.
LWP's offer a convenient and flexible compromise between user-threads and
separate processes. But it is important to realize that they are bulky
structures:
- Communications, even within a process, among LWPs requires
kernel involvement (read as: 2 context switches)
- LWPs are scheduled by the kernel, so blocking an LWP requires
kernel involvement.
- LWPs are very flexible, and very general -- this means that they
are very big. LWPs consume a great deal of resources
- LWPs are expensive to create and destroy, because this involves
the kernel
- LWPs are unpoliced, so users can create many of them, consuming
system resources, and starving other users processes by
getting more CPU time than similar processes with fewer LWPs.
Another Model
You might observe that threads within the same task share many of the
same resources -- the most significant difference is that they have
different stacks. This is exactly how Linux implements threads --
by leveraging the machinery it uses to create new processes.
In Linux, the system call beneath a fork() is known as clone(). It does
everything that fork() does -- but wiht a lot more flexibility. It allows
a newly created child to be created from the template of its parent by
either copying, sharing, or recreating various resources from the parent.
So, you can imagine that if all of the important resources are copies --
clone() is, in effect, a fork().
But, imagine two different processes that, in essence, share everything
but the stack. These processes are sharing global memory, so they are
really in the smae memory context -- but they have differnt stacks, so
can be doing different things. They are, in effect, threads.
So, as Linux evolved, they created kernel-supported threads by leveraging
clone() to create new processes that shared resources. They then created
a new task abstraction that aggregated related processes. So, in the
Linux model, within the kernel, a task is genuinely a collection of
processes. From the user's perspective, these thread-like processes
are presented as threads by the user-level thread library.
Tasks in Distributed Systems
In distributed systems, we find that the various resources needed to
perform a task are scattered across a network. This blurs the distinction
between a process and a task and, for that matter, a task and a thread.
In the context of distributed systems, a process and a thread
are interchangable terms -- they represent something that the user wants
done.
But, task has an interesting and slightly nuianced meaning. A
task is the collection of resources configured to solve a
particular problem. A task contains not only the open files and
communication channels -- but also the threads (a.k.a. processes).
Distributed Systems people see a task as the enviornment in which
work is done -- and the thread (a.k.a. process) as the instance of
that work, in progress.
I like to explain that a task is a factory -- all of the means of production
scattered across many assembly lines. The task contains the machinery and
the supplies -- as well the processes that are ongoing and making use of them.
Although this is traditionally a Distributed Systems view of the world, it
it is pretty applicable to modern operating systems that implement
kernel-supported threads, whether by a Linux-style close() or a Solaris-style
first-class task abstraction.