Return to lecture notes index
November 4, 2010 (Lecture 21)
What is a Distributed System?
A Distributed System as an abstraction. It is a way of organizing and
thinking about a collection of independent and possibly distant or
weakly connected resources as if they were all part of the same tightly
coupled package.
In his textbook, Andrew Tannenbaum, a famous pioneer in distributed
systems, defines it this way:
"A distributed system is a collection of independent computers that
appear to the users of the systems as a single computer.
--Andrew Tannenbaum, Distributed Operating Systems (1995), Pg 2.
Distributed Systems vs. Parallel Systems
Often we hear the terms "Distributed System" and "Parallel System."
What is the difference?
Not a whole lot and a tremendous amount -- all at the same time.
"Distributed System" often refers to a systems that is to be used by
multiple (distributed) users. "Parallel System" often has the connotation
of a system that is designed to have only a single user or user process.
Along the same lines, we often hear about "Parallel Systems" for
scientific applications, but "Distributed Systems" in e-commerce or
business applications.
"Distributed Systems" generally refer to a cooperative work environment,
whereas "Parallel Systems" typically refer to an environment designed to
provide the maximum parallelization and speed-up for a single task.
But from a technology perspective, there is very little distinction.
Does that suggest that they are the same? Well, not exactly. There are
some differences. Security, for example, is much more of a concern in
"Distributed Systems" than in "Parallel Systems". If the only goal of
a super computer is to rapidly solve a complex task, it can be locked
in a secure facility, physically and logically inaccessible -- security
problem solved. This is not an option, for example, in the design of
a distributed database for e-commerce. By its very nature, this system
must be accessible to the real world -- and as a consequence must
be designed with security in mind.
System Model
When I taught Operating Systems, I begin with a picture
that looked like the one below. If you didn't take OS, please don't
worry -- everything on the picture, almost, should be familiar to
you. It contains the insides of a computer: memory and memory
controllers, storage devices and their controllers, processors, and
the bus that ties them all together.
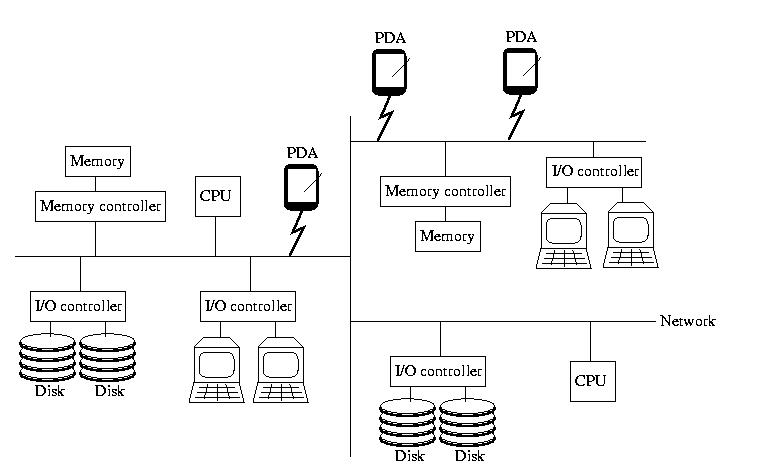
This time however, the bus isn't magical. It isn't a fast, reliable,
predictable communication channel called that always works and maintains
a low latency and high bandwidth. Instead, it is a simple, cheap,
far-reaching commodity network that may become slow and bogged down
and/or lose things outright. It might become partitions. And, it might
not deliver messages in the same order that they were sent.
To reinforce the idea that this is a commodity network, like the
Internet, I added a few PDAs to the picture this time. Remember,
the network isn't necessarily wired -- and all of the components
aren't necessarily of the same type. But, in all honesty, PDAs are
unlikely to be part of a distributed data base, beyond, possibly, serving
as hosts for users.
Furthermore, there is no global clock or hardware support for
synchronization. And, to make things worse, thr processors aren't
necessarily reliable, and nor is the RAM or anything else. For
those that are familiar with them, snoopy caches aren't practical,
either.
In other words, all of the components are independent, unreliable
devices connected by an unreliable, slow, narrow, and disorganized
network.
What's the Good News?
The bottom line is that, despite the failure, uncertainty, and
lack of specialized hardware support, we can build and effectively
use systems that are an order of magnitude more powerful. In fact we can
do this while providing a more available, more robust, more convenient
solution. This semester, we'll learn how.
Measures of Quality
In building a distributed system to attack a particular problem,
what are our specific measures of quality? What are the
characteristics of a good system?
Just as there isn't one "perfect fod" for all people and all occasions,
our goals in implementing a distributed system may vary with the
particular problem. But, the following are some very typical and common
measures of quality in distributed systems:
- Efficiency: Resources should perform productive work whenever
possible.
- Convenience: The user should be free to apply the system to one
or more tasks, with as little overhead as possible.
- Robustness: The system should be resiliant to failure. Failures
should have as little an impact on the system's
ability to perform useful work as possible.
- Availability: A user should be able to harness the utility of
the system with as few barriers as possible.
For example, users should not be bound to an
unavailable instance of a resource, when an equally
capable resources is available.
- Consistency: see below
- Coherency: see below
- Transparency: see below
Consistency vs. Coherency
Although these two terms actually mean very different things, they
are often interchanged or used as synonyms. Although this practice
isn't descriptive, it is common place -- please don't be surprised.
Different processes are said to have a consistent view of
data, if each process sees the same value. If different processes
see different values, they are said to have an inconsistent
view of the data. Inconsistencies often arise as the result of
replication. For example, if each process uses its own private
replica of the data, one process might not see another process's
changes. This could result in an inconsistent view.
Later we'll see that constantly maintaining atomic consistency,
a.k.a. perfect consistency, is very, very expensive, and often
not required in a particular application. For this reason, we often
will select a more relaxed consistency model that describes
when the data values can diverge, without generating incorrect results.
But more on this later in the semester...

Data is said to be incoherent if it is the result of a collection of
operations that make sense sense individually, but not collectively.

Transparency
A distributed system should hide the machinery from the user and present a
unified interface that provides the features and hides the complexity.
To the extent that this illusion is achieved, we say that transparency
is achieved. No useful real-world system achieves complete transparency,
so we often talk about the transparency of particular characteristics or
features of a system. And even when discussing a particular feature
or characteristic, there are many shades of gray.
A few examples are given below:
- access transparency -- the user should have the same view of
the system regardless of how she or he
access it. For example, consider a
user accessing the system locally versus
remotely, or on her or his workstation
versus another machine on the system.
- location transparency -- the user should need to know or care
where resources are located -- they
should just be accessible.
- migration transparency -- user's should know or care if
resources or processes move -- they
should function exactly as they did before.
- concurrency transparency -- concurrent operation should not result
in noticable side-effects.
- failure transparency -- the user should not notice failures. The
system should function as before (fail-safe)
or should suffer only in performance
(fail-soft).
- revision transparency -- software and hardware upgrades should not
interrupt service or generate user-visible
incompatibilities.
- scale transparency -- the system should be able to grow without
noticable side-effects. It should be as good
for small systems as large ones.
Transactions in a Distributed Environment and Atomic Commit Protocols
Think back to yesterday's discussion of transactions -- packages of
operations that, as a whole, need to be executed with the ACID properties.
Now, imaging that a transaction is to be executed across a distributed
data base, where the tables, or portions thereof, are spread across
multiple systems. This might be the case if several replicas of a database
must remain uniform.
We've got a few hurdles. The first, is finding the objects that we want
to access and manipulate. Our distributed data base needs to know who
has what. Another, perhaps more interesting question, is how do we
ensure the ACID properties across otherwise weakly systems?
To achieve this we need some way of ensuring that the distributed transaction
will be valid on all of the systems or none of them. To achieve this, we will
need an atomic commit protocol. Or a set of rules, that if followed,
will ensure that the transaction commits everywhere or aborts everwhere.
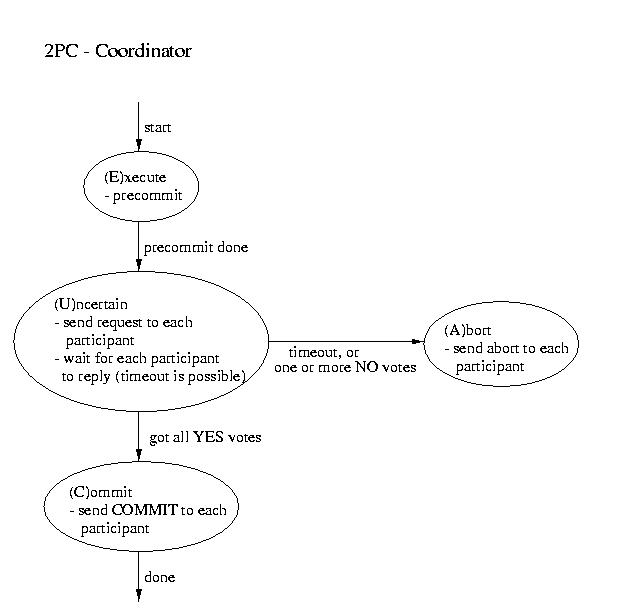
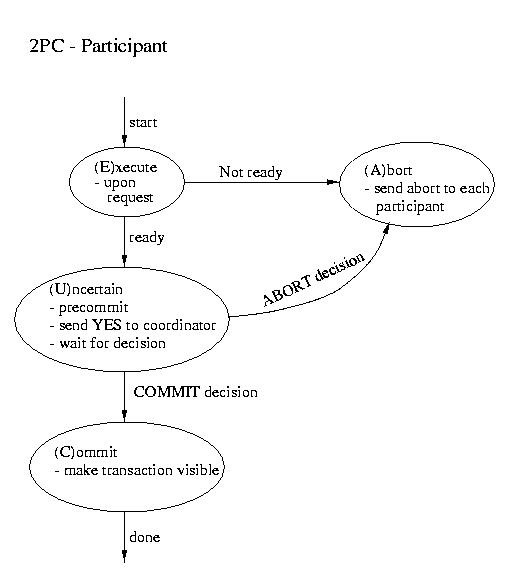
Two Phase Commit (2PC)
The most commonly used atomic commit protocol is two-phase commit.
You may notice that is is very similar to the protocol that we used
for total order multicast. Whereas the multicast protocol used a
two-phase approach to allow the coordinator to select a commit time
based on information from the participants, two-phase commit lets the
coordinator select whether or not a transaction will be committed
or aborted based on information from the participants.
| Coordinator | Participant |
|---|
| ----------------------- Phase 1 ----------------------- |
|---|
- Precommit (write to log and.or atomic storage)
- Send request to all participants
|
- Wait for request
- Upon request, if ready:
- Precommit
- Send coordinator YES
- Upon request, if not ready:
|
Coordinator blocks waiting for ALL replies
(A time out is possible -- that would mandate an ABORT) |
|---|
| ----------------------- Phase 2 ----------------------- |
|---|
|
This is the point of no return!
- If all participants voted YES then send commit to
each participant
- Otherwise send ABORT to each participant
|
Wait for "the word" from the coordinator
- If COMMIT, then COMMIT (transaction becomes visible)
- If ABORT, then ABORT (gone for good)
|
Three-phase Commit
Another real-world atomic commit protocol is three-pahse commit (3PC).
This protocol can reduce the amount of blocking and provide for more
flexible recovery in the event of failure. Although it is a better choice
in unusually failure-prone enviornments, its complexity makes 2PC the
more popular choice.
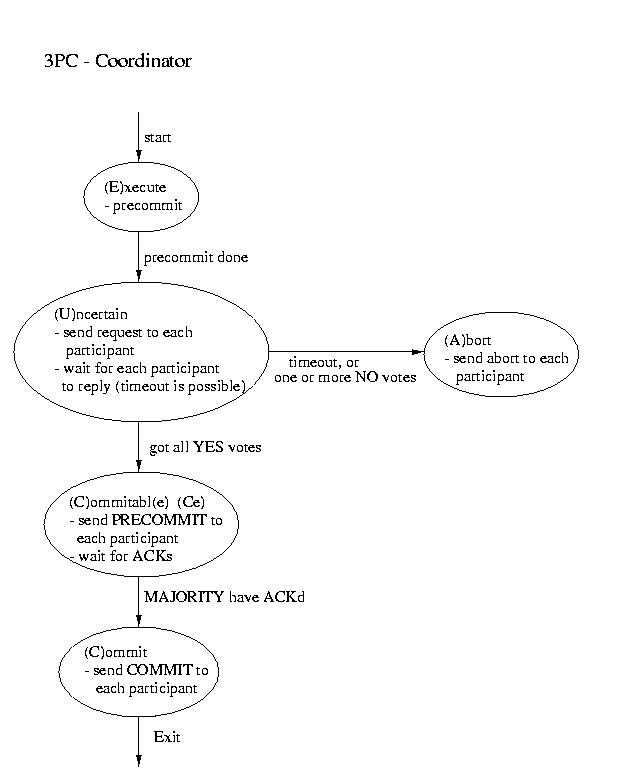
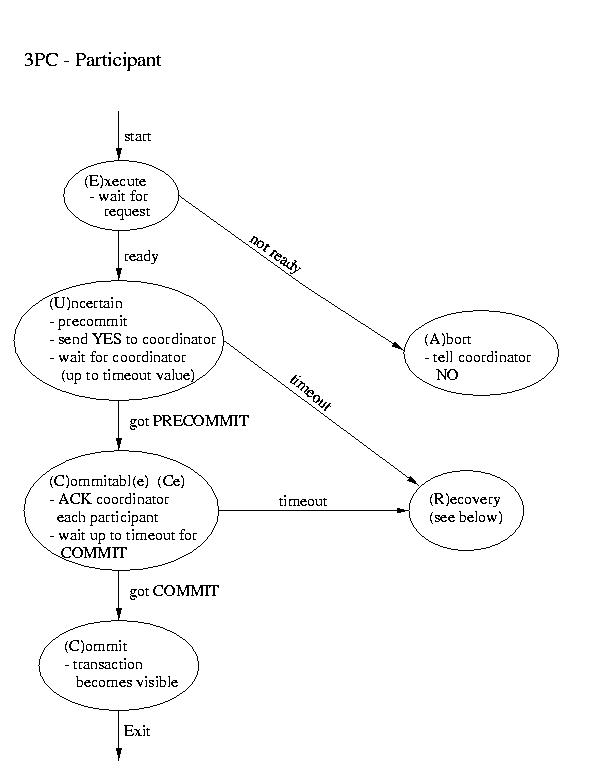
Recovery in 3PC
If the participant finds itself in the (R)ecovery state, it
assumes that the coordinator did not respond, because it failed. Although
this isn't a good thing, it may not prove to be fatal. If a majority
of the participants are in the uncertain and/or commitable states, it
may be possible to elect a new coordinator and continue.
We'll discuss how to elect a new coordinator in a few classes. So, for now,
let's just assume that this happens auto-magically. Once we have a new
coordinator, it polls the participants and acts accordingly:
- If any participant has aborted, it sends ABORTs to all
(This action is mandaded -- remember "all or none").
- If any participant has committed, it sends COMMIT to all.
(This action is mandaded -- remember "all or none").
- If at least one participant is in the commitable state
and a majority of the participants are commitable or
uncertain, send PRECOMMIT to each participant and proceed
with "the standard plan" to commit.
- If there are no committable participants, but more than half
are uncertain, send a PREABORT to all participants. Then
follow this up with a full-fledged ABORT when more than
half of the processes are in the abortable state. PRECOMMIT and
abortable are not shown above, but they are complimentary to
COMMIT and commitable. This action is necessary, because
an abort is the only safe action -- some process may have
aborted.
- If none of the above are true, block until more responses are
available.
"Cloud Computing"
In the past, the focus of distributed databases has been this type of
projection of traditional databases onto distributed systems. But, in
recent years, things have shifted a bit. "Cloud computing", which is
closely related to "Utility computing" has become a hot topic.
The basic idea here is that service providers offer farms of relatively
interchangeable compute nodes and storage nodes. Clients dispatch their
work across these machines using virtual machines, whether JVMs or
VMWare/KVM/VirtualBox VMs. The work is agnostic about which nodes it
runs on and mkaes use of the provided storage. The client gets billed for
the services used and has the ability to rapdily scale those services
up or down to meed demand and economic need.
Cloud computing is similar to parallel compuitng in that the cloud is
often maintained by one administrative organization and is often
organized such that large chunks of the cloud are nearby, both physically
and in network space. But, it departs from traditional parallel computing
into traditional distributed systems space in that the components are
generally closer to commodity equipment than highly specialized, high-cost
super computers, and in that multiple users are using the cloud for
multiple purposes, with the resulting conflicting demand for resources.
One important class of problem that can be addressed through cloud computing
is Data Intensive Scalable Computing (DISC). One of the prevelant
techniques for addressing this problem was originally published by our
friends at Google,
MapReduce: Simplified
Data Processing on Large Clusters.
There are, perhaps, two key ideas the paradigm that they published. The first
is that the compute nodes are location aware and generally operate on nearby
data. In order to achieve this, and to allow for the most parallelism in
accessing the data, it is, in effect, hashed, spreading the blocks of
large files across many systems. Multiple copies of the blocks are stored,
both to allow for redundancy, and also to allow for more opportunities for
parallel access. This is somewhat of a departure from the traditional
distributed systems model that favored location transparency.
The second key idea is that the processing is perofrmed using phases of
relatively simple map and reduce operations, similar to the
map and fold operations in some functional programming languges, e.g. ML.
Two distributed databases have recently come to prominence in the Open
Source community, Cassandra and HBase. HBase is an open
implementation of a database, BigTable, originally described by
Google, and built above a cloud described, as above. Cassandra
offers similar services to the end user, but is built above a distributed
system that uses a different underlying organization. Cassandra
comes to use from our friends at Amazon.
Next class
We'll talk more about the details of these systems in a couple of classes.
Next class, we'll talk about techniques for distributed hashing.