Return to the lecture notes index
Lecture 12 (Thursday, October 2, 2008)
Taking a Pass on Routing
Last class, we talked about many of the details associated with the IP
protocol and how packets find their way across a network. We talked about the
role of routers. We talked about the routing table, the table held by
each router that describes the global state of the network. And, we talked
about the forwarding table, the table derived from the routing table,
also present on each router, that contains the simple mapping from destination
network to port number. And, we said that the routers talk to each other
in order to collect routing information and then build their own forwarding
tables.
But, we did not talk about the details of this router-router conversation.
We're going to leave that for 15-441 (Networks). It isn't that it is hard.
It isn't. But, there are actually several different protocols that might
be in use. And, they all of havey interesting, and sometimes subtle,
behaviors. And, some of them dovetail really nicely with discussions
about non-routing (circuit or virtual circuit) techniques for selecting
a message's path.
So, in the end, the details of routing protocols are a long and interesting
discussion -- and an unnecessary one for us at this time. It is really a
discussion about disributed state -- and we'll get into that later. For now,
we can just assume that we're old fashioned and that a sysadmin builds the
tables. The model still works and we get to keep focus.
Network Layers, A Reference Model
As we work our way up from network hardware to the application programmer,
we are beginning to see the overal organization of a network. This
architecture is sometimes described using the following model:
| Application Layer: The details of the messages and structures used by a particular application |
| Transport Layer: Establishment of endpoints and other services commonly used by programmers |
| Network Layer: Movement of packets from network to network across an intern-network |
| Link Layer: Management of stations sharing the same channel |
| Physical layer: Voltages, connector shapes, power levels, light colors, &c |
Thus far, we've worked our way up, talking a little about the physical layer,
which is really the domain of various engineering disciplines, and a lot about
the link and network layers. Today, we are going to begin our discussion
of the transport layer.
The Transport Layer
The transport layer establishes an end-to-end abstraction that is useful to
the programmer. Part of that is that it needs to hide the hop-by-hop
nature of the network layer's routing process. And, part of that is that
it needs to establish program-to-program communication, since multiple
programs might be running on the same host -- and the network layer just
goes hop-to-hop.
In addition to these basic requirements, it must somehow answer the question,
"What is a message, and how do we know when we have one?". For example,
we often classify transport layers as being either:
- Message-oriented: Messages are sent like the mail. When you get
a message, it comes in a discrete chunk. Whatever is placed
into the envelope when sent is exactly what is in the envelope
when it is read. Envelopes, even those sent in series from the
same sender to the same receiver are never merged.
- Stream-oriented: There really isn't the concept of a discrete
message -- there is the flow of data. Consider a phone
conversation or radio broadcast. These don't come in envelopes.
There can be periods of quiet, but there is no packaging or
dividing line.
Protocols are often also classified in terms of their quality of service:
- Best-effort: Also like the post office, the protocol does its best,
but makes no guarantees. Messages may be lost or delivered out of
order
- Reliable: The protocol will try diligently to resent anything that
is not confirmed to be delivered.
As we'll talk about soon, unreliable protocols may, or may not,
be session-oriented. A session-oriented protocol establishes a
relationship between the sender and receiver before any data is exchanged.
this session remains in place until it is closed. So, in some sense, the
recipient knows to be waiting for communication. Unreliable protocols need
not be session-oriented. But, reliable protocols need to be session
oriented so that the sender and receiver can coordinate what has, and
what has not, been successfully received.
In the context of Internet protocols, the TCP/IP protocol suite, there are
two general-purpose transport protocols:
- User Datagram Protocol (UDP): Unreliable, message-oriented
- Transport Control Protocol (TCP): Reliable, stream-oriented
UDP adds very little value of IP, itself -- basically, it adds port
numbers. It allows applications to be identified with ports so that
messages, upon arriving at the destination, can be sent to the right
program.
We'll talk about TCP tomorrow. It adds a lot of value. It adds streams
and reliability. But, for today, I'd like to examine what it means
--and does not mean-- to be a reliable protocol.
Simple Reliability
It is easy to see how we could create a reliable protocol above UDP.
We add a sequence number to each message. We send a message and wait for
an ACKnowledgement. We know the maximum round-trip time, and wait at
least that long. If we don't get an ACK within that time, we assume that
the message got lost en route to the recipient -- even though maybe only
the ACK got lost. We resend. When the sender gets it, it'll ACK,
possibly again. There won't be any confusion, even if it is received twice,
because the sequence number will enable the duplicate to be detected and
discarded. The same is true of a duplicate ACK. If we send more than once
copy, and more than one ACK eventually makes its way to the sender, the
sender just ignores the duplicates -- it ignores any ACK that is not
associated with the present message number.
To this end, it is important to note that only one message is in flight
at a time. The time between the sending of a message and when its ACK is
received is dead air. For this reason, this type of reliable protocol
is often known as a stop-and-wait protocol.
The Two Army Story
Consider two waring armies, the Red Army, and the Blue Army. The Blue
Blue Army is camping in a mountain valley. The Red Army, while larger
and more powerful, is divided into two groups hiding in the surrounding
mountains.
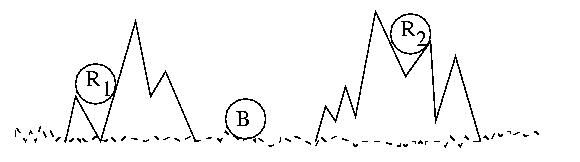
If the two Red Army platoons attack the Blue Army together and at
exactly the right time, they will prevail. The longer they wait, the more
surpised the Blue Army will be by the attack. But if they wait too long,
they will run out of supplies, grow weak, and starve. The timing is
critical. But if they are not coordinated, they will surely lose.
They must attack at exactly the same time.
When the time is right R1 will send a messenger to
R2 that says, "Attack at dawn!" But R1 may
become concerned that R2 did not get the message and
consequently not attack. If that happens, R1 will
be defeated. Alternately, R2 may become concerned that
R1 will beocme concerned, so they may not attack, leaving
R1 to be defeated in solitude.
So what if they agree that the recipient of the message, R2,
will return an ACK to the sender, R1? This is just one level
of indirection. The R2 may become concerned that the ACK was
lost and not attack. Or R1 may become concerned that
R2 became concerned and did not attack. This problem can't be
solved by ACK-ACK, or even ACK-ACK-ACK-ACK -- more ACKs just add more
levels of indirection, but the same problem remains.
Another issue might be fake messages. What if the Blue Army sent an
imposter to deliver a message to R2 telling them to attack
too early. They would be defeated if they followed it. But if they
did not obey messages for fear that they were fraudulant, R1
would be defeated when they did attack, even after advising R2.
This fear might also prompt an army from acting upon a perfectly valid
message.
The moral of this story is that there is no solution to this probem if the
communications medium is unreliable. Please note that I said
medium, not protocol. This is an important distinction.
A reliable protocol above an unreliable medium can guarantee that a
message will eventually be sent, provided of course that the
recipient eventually becomes ready and accessible. But no protocol
can guarantee that a message will be delivered within a finite
amount of time -- error conditions may persist for long and
indeterminate amounts of time.
Reliable vs Unreliable
A reliable media certainly beats one that is not. But, as we now know,
a reliable protocol is really just a diligent protocol. It tries, and
tries, and tries some more.
But, this is not always desirable. In some cases, a late packet is
worthless -- and resending it just wastes network time. This is the
case for many types of real-tiem communication, such as live video
or audio, e.g. telephone calls or web cams.
What does one do with a 10 minute old syllabal? If we delay the subsequent
syllabals by 10 minutes, the call is worthless. And, if we charge forward,
we can't exactly introduce a stray word later. It is best to just let
it go an hear a brief pause or pop. The same is true of video. We'd
rather see a brief freeze and a jump in one part of the frame than
have th4e whole thing delayed.