Return to the lecture notes index
Lecture 26 (December 8, 2005)
Books Covering Kernel-level Allocators
- Vahalia, Uresh, Unix Internals: The New Frontiers, Prentice Hall,
1996.
Most of the discussion of kernel-level allocators was based on
Chapter 12 of this text. Although becoming slightly dated,
this text is still a very unique and valuable reference. There are
many survey texts covering operating systems in an abstract way. And
there are many texts that cover the internals of specific operating
systems, such as 4.4BSD, SYSVR4, Linux, Solaris, &c. This text is
unique becuase it is a survey of unique features of several major OSs.
It is the only text that can be summarized as "comparative oparating
system design and implementation."
Kernel Level Memory Allocators
In 15-213 you probably talked a good bit about user-level memory allocation
-- and even wrote your own user-level allocator or garbage collector. But,
what about the kernel? How does it allocate memory? Where?
In principle, the kernel's memory allocation is not much different than
that of a user process. There is a piece of the address space that is
reserved for the kernel -- that is to say that it can only be accessed
when the processor is in privliged mode. There exists a kernel heap that,
much like the heap of any user process, is advanced one or more pages
at a time. These pages are dealt out, much like user pages, by a memory
allocator that handles individual requests -- often requests smaller
than a page. In fact, most, if not all, kernels have a version of malloc()
and free() that works just like the one in user space -- the basic general
purpose allocator.
But it is also true that the kernel doesn't necessarily use memory in
the same way as a user process. It has a lifetime that is, by definition,
no shorter than that of the longest lived process -- and probably longer.
Most processes are short. If they make a poor use of memory, no big deal,
they will be dead and the evidence of their transgretion gone before too
long. But the kernel can't bet on a short lifetime to solve its problems.
It must be efficient.
It is also the case that, despite its long lifetime, the kernel has many
memory allocations with respectively short lifetimes. Consider the
lifetime of a particular network buffer, task_struct or PCB, inode
(file representation), terminal buffer, &c. These buffers have very short
lifetimes, but are allocated over-and-over again.
Think about how a general purpose malloc() works -- the
allocation-free-reallocation process isn't exactly recycling -- it can result
in fragmentation and other wastage. It is also the case that the kernel
often needs to "clear" the buffers out after each use -- or one user's
data could leak to another. Similarly, the buffers might contain structures
that need to be initialized before each first use.
Given these characteristics, it might be nice to have an object cache
that would allow the kernel to recycle objects. This would allow them
to be directly re-used, without risk of fragmentation. It could also
allow the "wiping" done after oen use to also perform the initialization
required for the next.
Given this, we'll see that kernels generally have two (or more) allocators.
One of which is designed specifically to handle these special needs
of the kernel -- the reuse of common buffer sizes or types, and possibly
the construction/destruction of the associated data structures. And
another of which is much like the user-level allocators you discussed in
15-213 -- designed to handle all of the less-frequent, odd-sized requests.
The Resource Map Allocator
The simplest allocator works much like those we discussed during our early
discussion of memory allocation. It is a simple lust of tuples,
<base_address, size>. This list can then be sorted by size, to
easy allocation, or address, to easy coalescing, or both. Allocations
can be managed using first-fit, best-fit, or worst-fit policies.
Typically, the first-fit policy is used, and the list is kept sorted by
address to allow for coalescing, which is done upon each free().
This allocator is good, because it is simple, allows for the allocation
of exactly the amount of memory that is required, whtout rounding, and
because allocated blocks can be released in part or as a whole.
But, as before, it suffers badly from fragmentation, it takes time to
sort the list. And, in the context of the kernel, it does nothing to
mitigate the reuse or initialization/destruction.
I don't know of any modern kernels that use this allocator for memory,
but is is used for some other applications within the kernel, such
as the allocation of semaphores (SYSV).
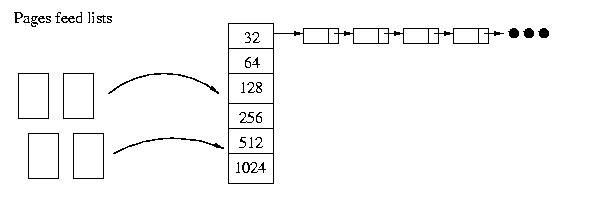
Simple Power-Of-Two Free Lists
Another approach that parallels our earlier discussion of simple memory
management is to round all allocations smaller than one page up to
a power of two and all allocations of larger than a page to a whole number
of pages.
Then, we can manage memory using a collection of lists, one for each power
of two and one for multiple-page allocations. When we free a small
allocation, we return it to the list for its size, when we free an allocation
of one whole page or more, we try to lower the break point, if possible.
Note: Although coalescing and returning memory are possibly, they are
generally not implemented, becuase of the cost associated with sorting
the list by address. Real systems neither coalesce buffers nor return
pages.
Actually, in order to free blocks and return them to the right list, it
is necessary to keep a header with each block that contains a pointer to
the list. Unfortunately, this header information has a nasty side-effect.
The fact of the matter is that many programmers do request memory in powers
of two. But, unfortunately, once this header is counted, the requests are
just greater than a power of two -- this leads to very high internal
fragmentation.
If there aren't enough buffers on a particular list to satisfy a
particular allocation, the allocator can block the allocation until
some are freed, create more by requesting and carving up a new page,
or using a block from a larger list. It should not cut up a block
from a larger list, because this would make coalescing more difficult.
Parts of the same page could be scattered among the lists.
With respect to the resource-map allocator, this allocator is trading
speen and external fragmentation for internal fragmentation. We are now
losing more space, in some cases almost as much as we allocate, with
each allocation, but much less space is lost outside of the allocations.
The powers of two fit nicely together and can be coalesced more easily.
This allocator does a little to mitigate the allocation-free-reallocation
cycle of the kernel -- it is very easy to refind a buffer of the same
size and it doesn't take a lot of work to free it or reallcoate it.
But, the cost -- rounding up -- can be very high in terms of wastage.
Furthermore, this allocator doesn't do anything to help with initialization
or destruction.
The McKusick-Karels Allocator
The McKusick-Karels Allocator is a very advanced system based on
the simple buddy allocator. It was originally developed for BSD, but is
now used in several other UNIX variants.
This system maintains power-of-two free lists, as before. But, it does not
keep the metadata within each allocated block. As a result, the common case,
where the programmer requests memory in a power-of-two sized chunk,
does not suffer from bad rounding.
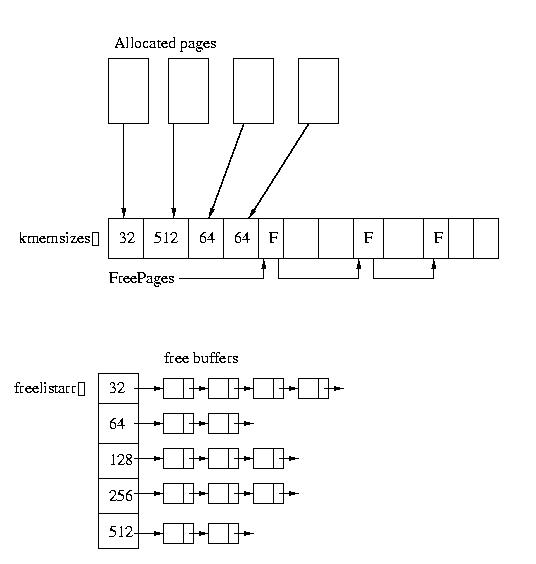
Instead, each page is broken up into the same power-of-two sized blocks.
There exists a global array with one entry per page. Each entry in this
array contains the size of the allocations within the page (which power of
two). Pages that are not in use form a free list. The points for the list
are stored with the free entries. The head of the list is kept in a
global pointer, freepages. If the allocated block spans pages,
the first page's entry stores the total size.
Additionally, the malloc(), including round-up is implemented as a macro,
which speeds the process, especially the round-up.
The McKusick-Karels Allocator is a big improvement over the simple
power-of-two allocator -- it makes it both faster and more space-efficient.
And, as before, makes it cheap to recycle objects of the same size. But,
it still isn't very efficient for buffers that are not powers of two,
nor does it do anything to help with the initialization or destruction
of buffers.
The Buddy System and the SYSVR4 Lazy Buddy System
Another approach to the kernel-level allocator is also a power-of-two
allocator, the binary buddy system. It works just like the buddy system
we saw during our discussion of rudimentary memory management. We'll
carve up memory into pieces by dividing it in half, until we reach
a chunk of the "right size". The "right size" is the requested size
rounded to a power of two, or the minimum size.
In the event of a free, the allocator checks to see if if an allocation's
buddy is free. When we do the allocation, we care a chunk into two
half, creating two smaller chunks. These chunks are buddies. When
memory is freed, the allocator attempts to reverse this process and reunite
the chunks. This is performed recursively, if possible.
To speed coalescing, a bitmap is used. This bitmap contains one flag for
each minimum allocation. When memory is used, the corresponding bits are
set. One propertt of the "cut in half" allocation scheme is that memory
is aligned based on the size of the allocation. As a result, the
buffer size and address can be used to identify the buddy.
Furthermore, this algorithm, much like ther McKusick-Karels Allocator,
maintains a separate free list with one entry per buffer size. As before,
this makes it easy to recycle buffers.
Unfortunately, this scheme requires coalescing at every opportunity
-- potentially every free(). This can get expensive -- it wastes a lot of
time. SYSVR4 improved this approach to include lazy coalescing.
Under this approach, the system has three different modes per list:
- Lazy: Don't bother to coalesce -- we'll probably need the
buffer again soon.
- Reclaiming: We've got a lot of extra buffers in this list, so let's
try to coalesce this one.
- Accelerated: We've got way too many extra buffers in this list, so
let's try to coalesce this one, plus another one.
It makes the decision about whcih mode to be in based on the amount of
slack in the list -- the number of extra buffers. Slack is defined as
follows:
slack = (number of buffers in the list) - 2*(number of buffers cached in
the free list) - (the number of marked free in the bit map)
Basically, in lazy mode, the system assumes that it will reuse the
buffer, so it doesn't mark it free in the global array. Whereas it
does in the other two modes.
If the slack parameter is 2 or more, the system is in lazy mode. If it
equals 1, the system is in reclaim mode. If it is 0, it is in accelerated
mode.
This system is a pretty efficient allocator -- but it still suffers from
internal fragementation and still doesn't address the probelm of buffer
initalization/destruction.
The Zone Allocator
The zone allocator, which is used in Mach and OSF/1 (a Mach derivative),
and in a limited form in Linux, is another approach, but it is not
based on powers of two. Instead, it is more of an object cache. Each type
of object has its own linked list. These lists cache objects for reuse.
If the list runs out, another page is requested and carved into new objects.
Each object list is called a zone. There is even a zone, called
the zone of zones to store the free zone objects.
A bursty usage pattern could leave the zone allocator storing a ton of
extra buffers. These are eliminiated using a garbage collector that runs
each time the swap taks runs -- in other words, if the system has to go
to disk, we look to free unnecessary allocations.
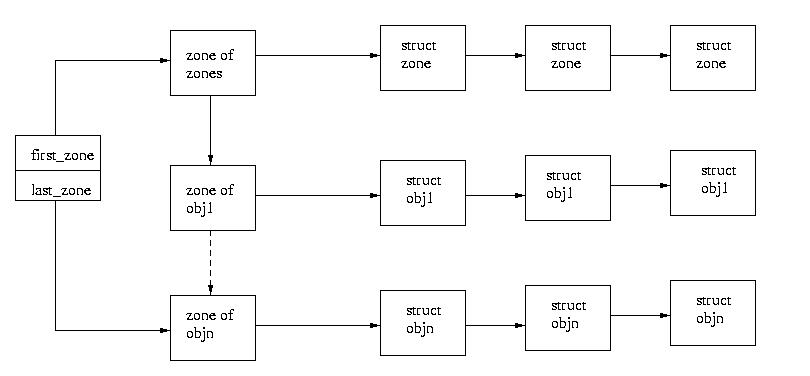
This garbage collection requires some additional overhead. In particular,
the system maintains an array with one enry per page. This array contains
a count of the number of free objects within a page and the number of objects
allocated from the page. These counts are not updated with each allocation
or free, instead they are updated by the garbage collector.
The first pass of the garbage collector walks through the linked lists and
adjusts these counts. The second garbage collector frees each page that is
holding only unused buffers (alloc count and free count are the same).
In this way, the zone allocator provides for fast, space-efficient,
low-fragmentation allocation and reusue of buffers within the kernel,
as well as a way to recover from a burst of buffer use. But, it still
doesn't provide any way to initialize or destroy objects residing
within each buffer.
The Solaris Slab Allocator
The Solaris Slab Allocator is based on the same idea as the
Zone Allocator. It creates a cache of objects of each type. But,
it takes the idea a couple of steps further. First, it is fully
object-oriented and supports constructors and destructors for each buffer,
and secondly it is more cache-aware. Thirdly, it is efficient
for both alrge and small objects.
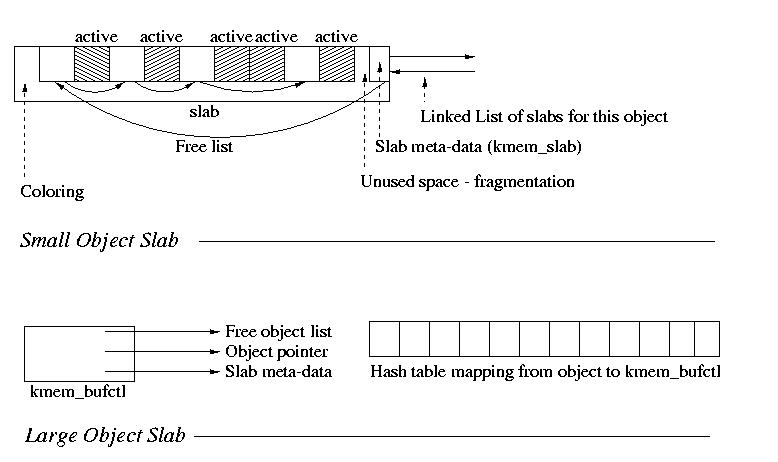
Each object type has its own cache, as well as its own constructor and
destructor. Small objects are allocated within a single page. Each page
contains an array of objects, free and used, as well as some meta data.
Additionally, there is a cache coloring area, which is nothing
more than an arbitrary amount of free space used to reduce collisions
within the cache -- by varying the amount of coloring, the slabs will,
in effect, begin at different addresses, and hopefully land in different
parts of the cache. This is because caches usually are divided into units,
each of which cahces addresses modulo a diferent value. Each small object
cache is nothing more than a linked list sof these slabs.
Large objects cannot fit within a page, so the slab meta data is stored
outside of the object. This is accomplished using a node that basically
contains pointers to everything important: the cache list, the allocated
object, and the metadata. These linkage objects, called kmem_bufctl,
are then kept within a linked list. Additionally, the reverse mapping
from object to kmem_bufctl is kept in a hash table to allow for quick
lookup.
In order to rapidly fre objects, a count and free count are kept within the
slab meta data. THe list of slabs is kept partially sorted. Empty slabs
at ne end, full slabs at the other, and partially full slabs in the middle.
When it is time to reclaim memory, the slabs at the end can be removed.
Objects are always allocated from partly full slabs. When a slab becomes
fully occupied, it is moved to the head of the list. The opposite is true if
it becomes empty. Similarly, a fully occupied slab gets moved further into
the list if it becomes only partly full.
This allocator is space-efficient, time-efficient, and fully object-oriented.
It also supports a simple garbage collection algorithm.
On the down side, caches with few objects have quite a bit of overhead --
it is better to use a general purpose allocator for these. But remember
that most modern kernels do have both a general purpose allocator,
as well as a specialize cache-liek allocator (such as slab or zone), or
simply cache objects locally within each sub-system.