Return to the lecture notes index
Lecture 24 (December 1, 2005)
Overview
Last class, we discussed Berkeley sockets, and the SOCK_DGRAM and SOCK_STREAM
modes. Today we're going to look at the underlying protocols, UDP and
TCP, respectively.
User Datagram Protocol (UDP): Introduction
UDP is a very minimal transport level protocol and offers very little added
value over the network layer. UDP is an unreliable, transport-level, datagram
protocol. Like TCP, it provides the abstration of a session -- an ongoing
association between two processes. Unlike TCP, it is unreliable and
message-oriented.
Unreliable implies that the application must determine how or if
to deal with packets that are lost or dropped. Message-oriented
service is a contrast to TCP's stream-oriented service. In TCP,
boundaries between transmissions are not preserved -- TCP transmissions
are seen as a continuous stream. By contrast, each UDP message is distinct
-- much like individual messages in a mailbox. The receive gets messages
one at a time, not byte by byte.
Packet Format

- The source port, much like the source port in TCP, identifies
the process on the originating system. TCP ports and UDP ports
are not the same. There is no relationship between the two.
- The destination port identifies the receiving process on
the receiving machine. Whereas the IP address identifies which machine
should get the packet, the port identifies which machine should get
the data.
- The length field contains the length of the UDP datagram.
This includes the length of the UDP header and UDP data. It does
not include anything added to the packet in-transit by other
protocols -- but these are stripped away before UDP sees the
datagram at the other side.
- The checksum field is used by UDP to verify the correctness
of the UDP header and data. If the checksum indicates an error, the
packet is dropped. UDP is unreliable, so it makes no attempt to
mitigate the loss.
A UDP packet contains a 12-byte pseudo-header, an 8-byte header, and the
data. Remeber that a netowrk level protocol, such as IP delivers the UDP
packet. It views the UDP packet, including the headers as data. In turn, the
UDP packet's data might include meta-data useful to another protocol, e.g.
another protocol's header.
The UDP checksum can be disabled. This is accomplished by setting the
checksum to 0 (a checksum of 0 is represented as 65,535). It might
make sense to disable the checksum if the link layer provides similar
protection, as is the case with ethernet. But this is a risky thing to
do -- the packet might cross several networks.
If the packet crosses several networks, routers, switches, &c could install
errors that aren't checked. And, certain link-layers don't provide error
detection -- including some popular protocols, such as SLIP. In the case
of SLIP, this is done because of the limited bandwidth available with the
typical physical layer (phone line) makes error control uneconomical.
For this reason, I highly suggest that you never disable
checksums in any application -- the physical configuration might change
and no one will ever suspect this problem!
Internet Protocol (IP) Header
We talked a little bit about IP -- for the most part we are going to
leave the details to 15-441. But, since we talked about UDP and mentioned
the IP header, we can take a quick look.

Most of the fields in the IP header are self-explanatory:
- Version is the version of the IP protocol -- either 4 or 6.
- The header length field specifies the size of the header,
this is needed, because the number of options can vary.
- The type of service is typically ignored, but can be
used to specify things like cheapest route, lowest latency route,
highest bandwidth route, &c.
- The total length filed is the size, in bytes, of the datagram,
including the header. The datagram ID is a unique number
assigned to the datagram -- it is used to determine which whole
datagram is the owner of a particular fragment.
- The flags field can be used to specify that a packet is a
fragment, or that it shouldn't be fragmented. It should be noted that
if a packet is marked unfragmentable and is too large, it will be
dropped.
- The fragment offset identifies the offset of the fragment
within the original datagram.
- The time to live (TTL) has the same meaning as it did with TCP
-- the maximum amount of time that the protocol will assume that the
packet can exist on the network. A packet that actually outlives its
TTL is dropped.
- The checksum works as it did with UDP.
- The protocol ID identifies which upper-level protocol (such
as TCP or UDP) should get the data on the receiving side.
Each protocol is assigned a unique number by IANA.
- The source IP address specifies which machine (or, more precisely
interface) is sending the packet.
- The destination IP address specifies the machine (or more
precisely interface) that should ultimately receive the datagram.
- The option field contains one or more optional parameters,
such as "use strict source routing", "use loose source routing",
"timestamp at routers", &c.
IP Fragmentation
Datagrams are fragmented, or broken into smaller datagrams, if the
size is larger than the maximum transmission unit (MTU) of the
interface upon which it will be sent. If the packet is marked "don't fragment"
and exceeds the MTU, it is dropped. The receiving side maintains a list of
the fragments for each datagram ID. The datagram is passed upward to the
next layer, once it is complete. If it is not completed within a time-out
period, the existing fragments are dropped. If a missing fragment arrives
too late, it will be thrown onto a new list for the datagram. This list
cannot be completed, since some fragments have already been sent -- it
will eventually time out and be thrown away.
Transmission Control Protocol (TCP): Introduction
TCP is a reliable, point-to-point, connection-oriented,
full-duplex protocol. What do these words mean?
- Reliable: A reliable protocol ensures that data sent from one
machine to another will eventually be communicated
correctly. It does not guarantee that this data will
be transmitted correctly within any particular
amount of time -- just that given enough time, it
will arrive. Life isn't perfect, and it is possible
for corrupted data to be thought correct by a
reliable protocol -- but the probability of this
occuring is very, very, very low (recall our
discussion of ECCs and EDCs).
- Point-to-point: Point-to-point protocols are those protocols
that communicate information between two machines.
By contrast, broadcast and multicast protocols
communicate information from one host to many
hosts.
- Connection-oriented:A connection oriented protocol involves
a connection or session between the
endpoints. In other words, each host is aware of
the other and can maintain information about the
state of communication between them. The connection
needs to be initialized and destroyed. The shared
state that is possible with a connection-oriented
protocol is essential to a reliable protocol. In
particular, the notion of a sequence number or serial
number is a practical necessity, if not a theoretical
necessity.
- Full-duplex:By full-duplex we mean a mode of communication
such that both sides can send and receive concurrently.
Establishing a Connection: "Three-way Handshake"
The most common way a TCP connection is initiated is for one end,
we'll say the client, to perform an active open and for the
other side to perform a passive open. The active open is
performed by the side initiating the connection. The passive open
is performed by the other end. Consider the client-server model, where
the server waits for a connection, which is initiated by the client.
Step 1:
The client begins it's active open by sending a SYN to the server. SYN
stands for "Synchrnoization Sequence Number", but ti actually contains
much more. The SYN message contains the initial sequence number (ISN).
This ISN is the starting value for the sequence numbering that will be used
by the client to detect duplicate segments, to request the retransmission of
segments, &c. The message also contains the port number. Whereas the
hostname and IP address name the machine, the port number names a particular
processes. A process on the server is associated with a particular port using
bind().
SYN (synchronization sequence number)
Initiator --------------------------------------------> Participant
(Client) ISN(client) + Port #(server) (Server)
Step 2:
The server performs the passive open, by sending its own ISN to the client.
It also sends an Acknowledgement (ACK) of the client's SYN, using the ISN
that the client sent plus one.
SYN (synchronization sequence number)
+ ACK of SYN
Initiator <-------------------------------------------- Participant
(Client) ISN(server) + ACK(ISN sent by client + 1) (Server)
Step 3:
The client finishes the active open by acknowledging the server's SYN.
ACK of SYN
Initiator --------------------------------------------> Participant
(Client) ACK (ISN sent by server + 1) (Server)
Please be aware that in each of the above steps, each initial message is ACKed.
If the ACK does not occur, a time-out and retry approach is used. For this
reason, duplicate messages must be ignored.
Please also be aware that what we have shown is the common case. Simultaneous
active opens are also supported. Take 15-441 for more information :-)
How and Why Is the Initial ISN chosen?
Why do we send the ISN, instead of just always start with 1? The answer
to this is that we don't want to misinterprete an old segment. For example,
consider a short-lived client process that always talked to the same server.
If the ISN's would always start with one, a delayed segment from one
connection might be misinterpreted as the next segment for a newer instance
of the same client/server-port combination. By doing something more random,
we reduce the bias toward low sequence numbers, make things more random, and
reduce the likelihood of this type of situation.
RFC 793 specifies that the ISN should be selected using a system-wide 32-bit
counter that is incremented every 4 microsseconds. This approach provides
a "moving target" that makes segment number confusion unlikely.
4.4BSD actually does something different. It increments the counter by 64K
every half-second and every time a connection is established. This amortizes
to incrementing the counter by one every 8 microseconds.
Connection Termination
When either side of a TCP connection is done sending data, it sends a FIN
(finished) to the other side. When the other side receives the FIN, it
passes an EOF up the protocol stack to the application.
Although TCP is a full-duplex protocol, the sending of a FIN doesn't
tear down the whole connection. Instead it simply indicates that the
side sending the FIN won't send any more data. It does not prevent the
other side from sending data. For this reason, it is known as a
half-close. In some sense, a half-closed connection is a half-duplex
connection.
Although TCP allows for this half-closed state, in practice, it is very
rarely used. For the most part, when one side closes a connection, the
other side will immediately do the same. It is also the case that
both sides can concurrently sends FINs. This situation, called a
simultaneous close is perfectly legal and acceptable.
Half-close:
FIN
One side --------------------------------------------> Other side
ACK
One side <-------------------------------------------- Other side
What About Crashes, &c
But wait, if both sides need to close the connection, what happens if the
power fails on one side? Or a machine is shut off? Or the network goes down?
Well, the answer to this is very simple: Nothing. Each side will maintain
at least a half-open connection until the other side sends a FIN. If the
other side never sends a FIN, barring a reboot, the connection will remain
at least half-open on the other side.
What happens if neither process ever sends data? The answer to this is also
very simple: Nothing. Absolutely nothing is sent via TCP, unless data is
being sent.
TCP Keepalive Option
Well, some people were as upset as you were by the idea that a half-open
connection could remain and consume resources forever, if the other side
abruptly died or retired. They successfully lobbied for the TCP Keepalive
Option. This option is disabled by default, but can be enabled by either
side. If it is enabled on a host, the host will probe the other side, if the
TCP connection has been idle for more than a threshhold amount of time.
This timer is system-wide, not connection wide and the RFC states that, if
enabled, it must be no less than two hours.
Many people (including your instructor) believe that this type of feature
is not rightfully in the jursidiction of a transport layer protocol. We argue
that this type of session management is the rightful jurisdiction of the
application or a session-level protocol.
Please do realize that this is a religious issue for many and has received far
more discussion than it is probably worth. Independent of your beliefs,
please don't forget that the timer is system-wide -- this can be a pain
and might even lead many keepalive-worshipers opt for handling this within the
applications.
Reset (RST)
TCP views connections in terms of sockets. A popular author, Richard
Stevens refers to these as connections -- this is wrong, but
has worked its way into the popular vernacular. A socket is defined as the
following tuple:
<destination IP address, destination port #, source IP address, source port number>
A RST is basically a suggestion to abort the connection. A reset will generally
be sent by a host if it receives a segment that doesn't make sense. Perhaps
the host crashed and then received a segment for a port that is no longer in
use. In this case, the RST would basically indicate, "No one here, but
us chickens" and the side that received the RST would assume a crash, close
its end and roll-over or handle the error.
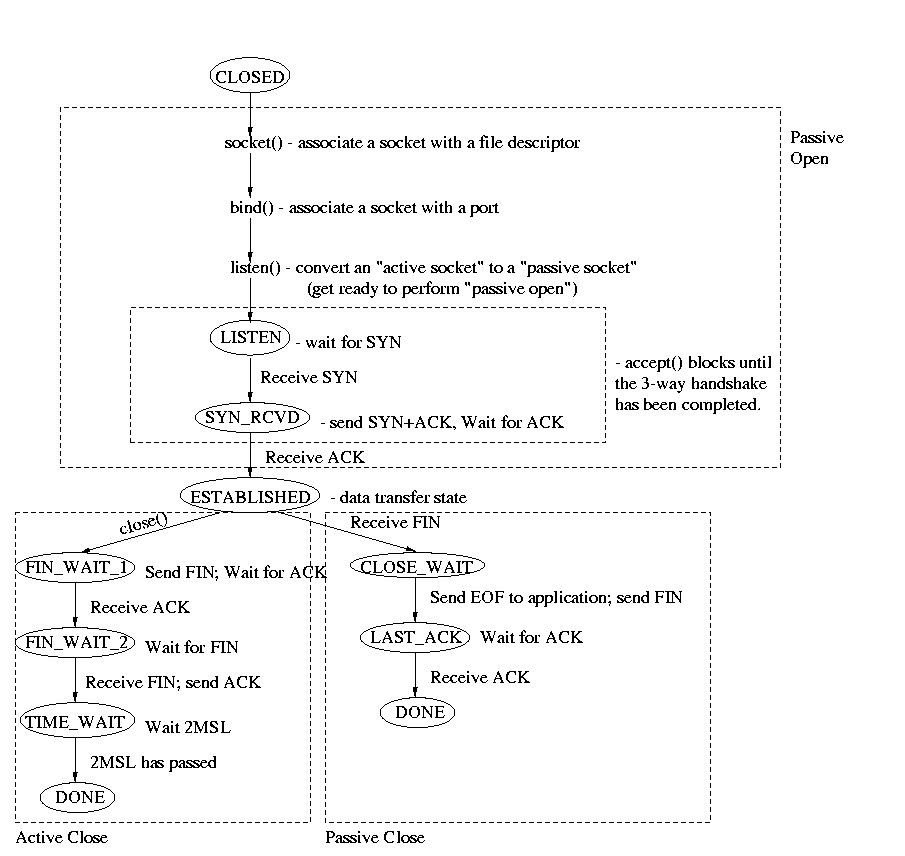
Typical Server State Transition Diagram
What follows is a diagram of the different states and transitions that
a server might experience. It is not all-inclusive. It is not a full
finite-state machine for the TCP protocol -- it is just one typical case.
One important thing to notice is the "2MSL wait" in the TIME_WAIT state.
MSL stands for "Maximum Segment Life." Basically, MSL is a constant that
defines the maximum amount of time that we belive a segment can remain in
transit on the network. 2MSL, twice this amount of time, is therefore an
approximation of the maximum rount trip time. The 2MSL delay in this
state exists to protect against a lost ACK. If the ACK is lost, the
FIN will be retransmitted and received. The ACK can then be resent and
the 2MSL timer restarted.
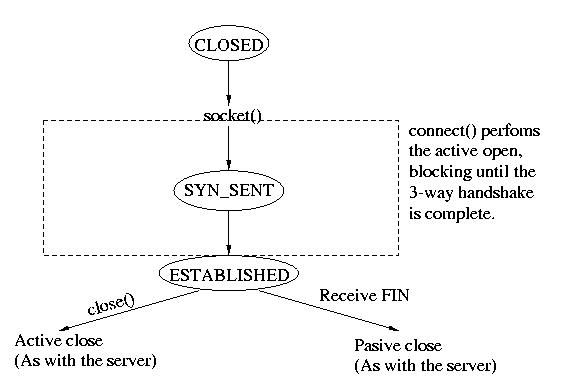
Typical Client State Transition Diagram
As before, this is diagram shows the common cases, it is not an all-inclusive
transition diagram for TCP. Want more information? Take 15-441.
Transferring Data
Well, we've talked about tons of good stuff, but none of it actually
accomplishes the most fundamental goal of TCP -- sending data. So, let's
now discuss how TCP actually moves data form one end to the other.
TCP operates by breaking data up into peices known as segments.
The TCP packet header contains many pieces of information. Among them is
the Maximum Segment Length (MSL) that the host is willing to accept.
In order to send data, TCP breaks it up into segmetns that are not longer
than the MSL.
Fundamentally, TCP sends a segment of data, including the segmetn number
and waits for an ACK. But TCP tries to avoid the overhead involved in
acking every single segment using two techniques. TCP will wait up to
200mS before sending an ACK. The hope is that within that 200 mS a segment
will need to be sent the other way. If this happens, the ACK will be
sent with this segment of data. This type fo ACK is known as a piggyback
ACK. Alternatively, no outgoing segment will be dispatched for the sender
within the 200mS window. In this case the ACK is send anyway. This is
known as a delayed ACK.
Note: My memory is that the RFC actually says 500mS, but the implementations
that I remeber use a 200mS timer. No big deal, either way.
Delayed ACK:
data
----------------->
(200mS passes)
ACK
<-----------------
Piggback ACK:
data
----------------->
(<200mS passes)
data + ACK
<-----------------
More About ACKs
TCP uses cumulative acknowledgement. Each ACK acknowledges
not only one particular segment, but also all prior segments. This
is accomplished by only ACKing the last contiguous segment. This can
mitigate the effects of lost ACKS, if a subsequent ACK occurs within the
time-out period. TCP actually does not specify what happens to segments
that arrive ahead of a prior segment. Most implementations buffer them
and ACK them when possible, but a TCP implemenation could technically o
discard them.
If a segment arrives out of order, TCP will use an immediate
acknowledgement of the last contiguous segment received, to tell the
sender which segment is expected. This is based on the assumption that
the likely case is that the missign segment was lost not delayed.
If this assumption is wrong, the first copy to arrive will be ACKed, the
subsequent copy will be discarded.
Nagle Algorithm
One interesting observation is that it takes just as much overhead to send
a small amount of data, such as one character, as it does a large amount
of data, such as a full MSL of data. The masive overhead associated with
small segments can be especially wasteful if the network is already bogged
down.
One approach to this situation is to delay small segments, collecting them
into a full segment, before sending. This approach reduces the amount
of non-data overhead, but it can unnecessarily delay small segments if the
network isn't bogged down.
The compromise appraoch that is used with TCP was proposed by Nagle.
The Nagle Algorithm will send one small segment, but will delay the others,
collecting them into a larger segment, until the segment that was sent
is acknowledged. In other words, the Nagle algorthm allows only one
unacknowledged small segment to be send.
This approach has the following nice property. If the network is very bogged
down, the ACK will take a long time. This will result in many small segments
being collected into a large segment, reducing the overhead. If the network
isn't bogged down, the ACK will arrive very rapidly, allowing the next small
segment to be sent without much delay. If the network is fast, fewer small
segments will be concatentated, but who cares? The network isn't doing much
else.
In other words, the Nagle algorithm favors the sending of short segments
on a "fast network" and favors collecting them into larger segments on
a "slow network." This is a very nice property!
There are certain circumstances where the Nagle approach should be disabled.
The classic example is the sending of mouse movements for the X Window system.
In this example, it is critically important to dispatch the short packets
representing mouse movements in a timely way, independent of the load on
the network. These packets need a response in soft real-time to satisfy the
human user.
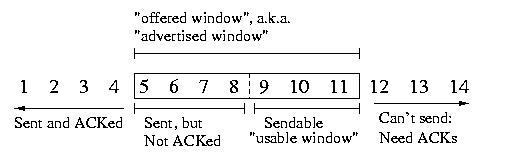
The Sliding Window Model
As we mentioned earlier, TCP is a sliding window protocol much like the example
protocol that we discussed last class. The sliding window model used by TCP
is almost identical to model used in the example. In the case of TCP, the
receiver's window is known as the advertised window or the offered
window. The side of the window is advertised by the receiver as part of
the TCP header attached to each segment. By default, this size is usually
4096 bytes. The usable window is the portion of the advertised
window that is available to receive segments.
The only significant difference is the one that we mentioned before:
TCP uses a cumulative ACK instead of a bit-mask.
Slow Start and Congestion Avoidance
The advertised window size is a limit imposed by the receiver. But the
sender doesn't necessarily need or want to send segments as rapidly as
it can in an attempt to fill the receiver's window. This is because the
network may not be able to handle the segments as rapidly as the sender can
send them. Intermediate routers may be bogged down or slow. If the sender
dispatches segments too rapidly, the intermediate routers may drop them
requiring that they be resent. In the end, it would be faster and more
bandwidth efficient to send them more slowly in the first place.
TCP employs two different techniques to determine how many segments can be
sent before acknowledgement: slow start and congestion avoidance.
These techniques make use of a sender window, known as the
congestion window. The congestion window can be no larger than the
receiver's advertised window, but may be smaller. The congestion window
size is known as cwnd.
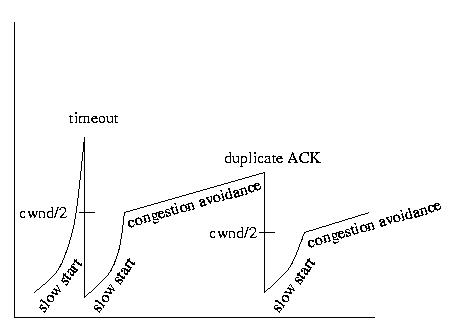
Slow Start
Initially, the congestion window is one segment large. The sender will send
exactly one segment and wait for an acknowledgement. Then the sender
will send two segments. Each time an ACK is received, the congestion
window will grow by two. This growth will continue until the congestion
window size reaches the smaller of a threshhold value, ssthresh
and the advertised window size.
If the congestion window reaches the same size as the advertised window,
it cannot grow anymore. If the congestion window size reaches ssthresh,
we want to grow more slowly -- we are less concerned about reaching a
reasonable transmission rate than we are about suffering from congestion.
For this reason, we switch to congestion avoidance. The same is true
if we are forced to retransmit a segment -- we take this as a bad sign
and switch to congestion avoidance.
Congestion Avoidance
Congestion avoidance is used to grow the congestion window slowly. This is
done after a segment has been lost or after ssthresh has been reached.
Let's assume for a moment that ssthresh has been reached. At this point, we
grow the congestion window by the greater of 1 segment and (1/cwnd).
This rate or growth is slower than it was before, and is more appropriate
for tip-toeing our way to the network's capacity.
cwnd = cwnd + MAX (1, (1/cwnd))
Eventually, a packet will be lost. Although this could just be bad luck,
we assume that it is the result of congestion -- we are injecting more
packets into the network than we should. As a result, we want to slow
down the rate at whcih we inject packets into the network. We want to back
off a lot, and then work our way to a faster rate. So we reset ssthresh and
cwnd:
- ssthresh = MAX (2, cwnd/2)
- cwnd = 1
The next thing we are going to do is to reinvoke slow start. This time it
will start with a cwnd size of 1 and grow rapidly to half of the
prior congestion window size. At that point congestion avoidance will be
reinvoked to make tip-toe progress toward a more rapid transmission rate.
Eventually, a packet will be lost, ssthresh will be cut, cwnd will be reset
to 1, and slow start will be reinvoked. It is important to notice that
ssthresh doesn't always fall -- it can grow. Since ssthresh is set to
(cwnd/2), if the new value of cwnd is more than twice the old value of
ssthresh, ssthresh will actually increase. This makes sense, because it
allows the transmission rate to slow down in response to a transient, but
to make a substantial recovery rapidly. In this respect, the exponential
growth rate of "slow start" is actually a "fast start".
It is also important to remember that what is being varied here is the
number of segments that TCP will send, without acknowledgement, to
fill the useable window.
An example showing the change in the congestion window under the
influence of slow start and congestion control is shown below.
Important Note
Please remember that there are many more details about TCP that
we haven't discused. My goal was not to discuss all of the details of
TCP -- those are best left to courses in networking and reference books.
Instead, I wanted to help you to gain some sense of real world solutions
to real-world problems. We discussed a large part of TCP today, but
there is more. If you are interested in this area, you can take
15-441, and/or I can recommend some reading in RFCs, articles, and books.