Return to the lecture notes index
Lecture 17: Thursday, November 9, 2006
The Conceptual Thread
In our discussion of tasks we said that a task
is an operating system abstraction that represents the state of a
program in execution. We learned that this state included such things as
the registers, the stack, the memory, and the program counter, as well
as software state such as "running," "blocked", &c. We also said that
the processes on a system compete for the systems resources, especially
the CPU(s).
Today we discussed another operating system abstraction called the
thread. A thread, like a task, represents a discrete piece
of work-in-progress. But unlike tasks, threads cooperate in their
use of resources and in fact share many of them.
We can think of a thread as a task within a task. Among other things
threads introduce concurrency into our programs -- many threads
of control may exist. Older operating systems didn't support
threads. Instead of tasks, they represented work with an abstraction
known as a process. The name process, e.g. first do ___,
then do ____, if x then do ____, finally do ____, suggests only
one thread of control. The name task, suggests a more general
abstraction. For historical reasons, colloquially we often say
process when we really mean task. From this point
forward I'll often say process when I mean task --
I'll draw our attention to the difference, if it is important.
A Process's Memory
Before we talk about how a tasks' memory is laid out, let's
first look at the simpler case of a process -- a task with
only one thread of control.
Please note that the heap grows upward through dynamic allocation
(like malloc) and the stack grows downward as stack frames are
added throguh function calls. Such things as return addresses, return
values, parameters, local variables, and other state are stored in
the runtime stack.
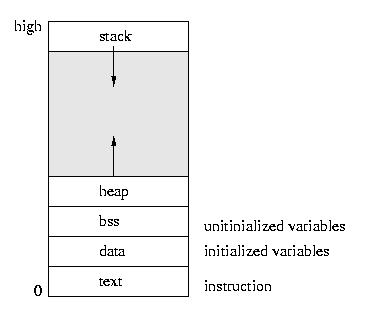
- The text area holds the program code.
- The data area holds global and static variables that must be
stored in the executible, since they are initialized.
- The bss area holds variables that are unitialized in the sense
that their need not be persistently stored on disk -- they can be
plugged in later.
The Implementation of Threads
All of the threads within a process exist within the context of that
process. They share the code section, data section, and operating system
resources such as open files.
But they do not share all resources. Since each thread executes
independently, each thread has its own understanding of the stack and of
the registers.
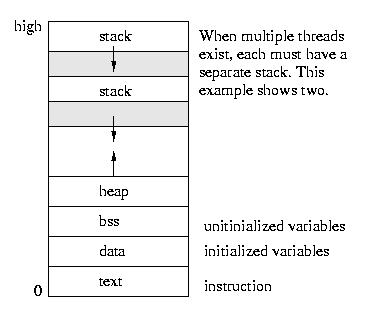
The good part about sharing so many resources is that switching
execution among threads is less expensive than it is among processes.
The bad part is that unlike the protection that exists among processes,
the operating system can not prevent threads from interfering with each
other -- they share the same process space.
Kernel Threads
The most primitive implementations of threads were invisible to the
user. They existed only within the kernel. Many of the kernel daemons,
such at the page daemon, were implemented as threads. Implementing
different operating system functions as threads made sense for many
reasons:
- There was no need for protection, since the kernel developers trust
themselves. Please note that we lose memory protection
once we go from processes to threads -- they all play in the
same address space.
- The different OS functions shared many of the kernel's resources
- They can be created and destroyed very cheaply, so they can be
easily used for things like I/O requests and other intermitent
activities.
- It is very cheap to switch among them to handle various tasks
- It is very easy to thing of kernel activities in terms of
separate threads instead of functions within one monolithic
kernel.
User Threads
But the UNIX developers couldn't keep such a great thing as their own
private secret for long. Users began to use threads via thread
libraries. Thread libraries gave users the illusion of
threads, without any involvement form the kernel. When a process
containing threads is executed, the thread scheduler, within the process,
is run. This scheduler selects which thread should run and for how long.
If a thread should block, the scheduler can select to run another thread
within the same process.
This implementation of threads is actually much more than an illusion. It
gives users the ability to write very efficient programs. These programs
can switch among threads and share resurces with very little overhead.
To switch threads, the registers must be saved and restored and the
stack must be switched. No expensive context switch is required.
Another advantage is that user level threads are implemented entirely
by a thread library -- from the interface to the scheduling. The kernel
doesn't see them or know about them.
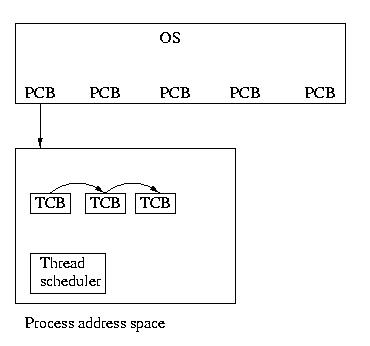
Light Weight Processes (LWPs)
Kernel threads are great for kernel writers and user threads answer many
of the needs of users, but they are not perfect. Consider these examples:
- On a multiprocessor system, only one thread within a process
can execute at a time
- A process that consists of many threads, each of which may be
able to execute at any time, will not get any more CPU time
than a process containing only one thread
- If any thread within a process makes a system call, all threads
within that process will be blocked because of the context switch.
- If any user thread blocks waiting for I/O or a resource, the entire
process blocks. (Thread libraries usually replace blocking calls
with non-blocking calls whenever possible to mitigate this.)
To address these needs, we need to have a kernel supported user thread.
That is to say, we need a facility for threads to share resources within
a process, but we also need the ability of the kernel to preempt, schedule,
and dispatch threads. This type of thread is called a kernel supported
user thread or a light-weight process (LWP). A light-weight
process is in contrast with a heavy-weight process otherwise known
as a process or task.
Our model of the universe has gone from looking like this:
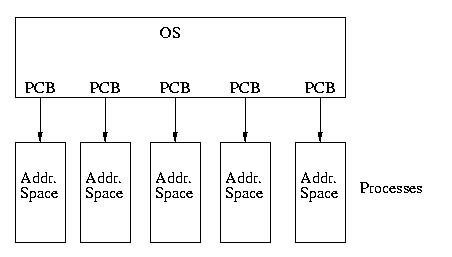
To looking like this:
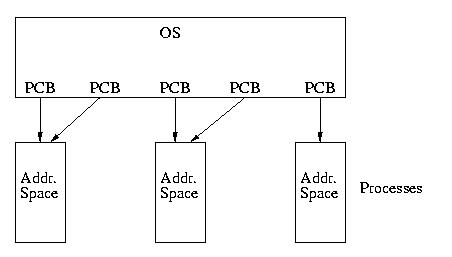
In this model each thread/LWP is associated with a single PCB that
is scheduled by the OS. If the system supports kernel threads (and
most, if not all that support LWPs do), it will probably have kernel
threads associated with each LWP and it is these threads that the kernel
will actually schedule.
A More Complex Model
In some models, such as that used by Solaris, it is also possible to
assign several kernel-supported threads to a single process without
assigning them to specific user-level threads. In this case, the process
will have more opportunities to be seen by the OS's CPU scheduler. On
multiprocessor systems, the maximum level of concurrency is determined
by the number of LWPs assigned to the process (of course this is further
limited by the number of threads that are runnable within the process
and the number of available CPUs).
Although in the main, LWP and kernel supported user thread
are synonymous, Sun uses the term differently. In the context of
Solaris, an LWP is a user-visible kernel thread. In some ways, it
might be better to view a Solaris LWP as a virtual light weight
processor (this is Kesden nomenclature!). This is because pools
of LWPs can be assigned to the same task. Threads within that task are
then scheduled to run on available LWPs, much like processes are scheduled
to run on available processors.
In truth, LWPs are anything but light weight. They are lighter weight
than (heavy weight) processes -- but they require far more overhead
than user-level threads without kernel support. Context-switching among
user-level threads within a process is much, much cheaper than context
switching among LWPs. But, switching among LWPs can lead to greater
concurrency for a task when user-level threads block within the kernel
(as opposed to within the process such that the thread scheduler can run
another).
The diagram below shows LWP's associated with tasks and kernel threads, as
well as kernel threads without an associated LWP and several different
associations between user-level threads and the LWP(s) assigned to the
process.
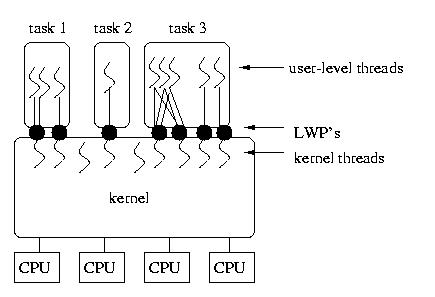
LWP's offer a convenient and flexible compromise between user-threads and
separate processes. But it is important to realize that they are bulky
structures:
- Communications, even within a process, among LWPs requires
kernel involvement (read as: 2 context switches)
- LWPs are scheduled by the kernel, so blocking an LWP requires
kernel involvement.
- LWPs are very flexible, and very general -- this means that they
are very big. LWPs consume a great deal of resources
- LWPs are expensive to create and destroy, because this involves
the kernel
- LWPs are unpoliced, so users can create many of them, consuming
system resources, and starving other users processes by
getting more CPU time than similar processes with fewer LWPs.
The API
In class, we discussed the POSIX Thread (pthread) library. For the detail
here, check out the man pages. Here are a few that will get you started:
- pthread_create
- pthread_join
- pthread_exit
- pthread_cond_init
- pthread_cond_destroy
- pthread_cond_signal
- pthread_cond_broadcast
- pthread_cond_wait
- pthread_mutex_init
- pthread_mutex_destroy
- pthread_mutex_lock
- pthread_mutex_trylock
- pthread_mutex_unlock
- sem_init
- sem_destroy
- sem_post
- sem_wait
- sem_trywait
- sem_getvalue
Linking Threaded Applications
The use of the posix thread library is not part of libc. Applications
using these functions should link against libposix (-lposix). The only
trick here is that code will comple -- but not function -- unless
linked against libposix.
The issue is that libposix strongly defines some methods that are
weakly defined stubs within libc. In doing so, it enables locking
on datastructures that are not otherwise thread safe. No locking, no
thread safety. No thread safety, plus threads = bad day.