External Data Structures/File Structures
In 15-200, 15-211, and other courses, you have probably discussed many different data structures. But, most of the data structures you have discussed are tremendously limited in thier application. They are only useful in reasonably fast RAM. They aren't useful in slow memories or in those that are slow when accessed randomly (versus sequentially).As a consequence, they are great for use while a program is running -- but not so great for data that is larger than can be kept in main memory or for data that must be persistent (live beyond the program, for example, through a reboot).
When we need to manipulate large amounts of persistent data, we typically rely on a differnet class of data structure -- those that can perform well when maintained on disk drives.
Although capable of random access, disk drives are much faster when reading sequentually -- and in any case, they are slower than main memory. The random seek time of a modern disk might be 6ms. This is the time it takes to move the heads in or out on the platter (disk) to find the right track. It can take a small amount of extra time, the rotational delay for the data to actually rotate under the head. And then another interval, proportional to the amount of data to be read, known as the transfer delay to actually read the data as it spins by under the head.
Furthermore, unlike main memory, disks read in units of a sector to a few tracks, a few K to megabytes, at a time. At the operating system level, disk accesses are managed in units known as blocks, which are typically one to a small few sectors. So, it makes sense to make good use of what is read in.
The bottom line is that, for persisent storage, we want to avoid random accesses and hit disk on as few occasions as is possible.
Binary Search Trees (BSTs)
In an earlier class, I'm sure you learned of the venerable BST -- what a wonderful idea: Simple, good average-case complexity, eloquent. Unfortunately, it sticks on disk. This is for two reasons.The first, you already know. It can degenerate to badness. And, when possible, we'd like to dodge that risk. Approaches, such as the AVL rotations that provide this assurance, do it at a cost. Those rotations reorganize records that are already in place. They are time-consuming in memory -- and more so on disk. Furthermore, no one likes to think that thier precisou on-disk data, intended to last lifetimes, is being manipulated -- especially as the lights flicker. It is more comfortable for it to stay put!
The other concern is probably less familiar. In memory, jumping from node to node is cheap. On disk -- not so cheap. Each node requires a seek. So, with each seek, we make only one decision. It would be better if we could make more. Ideally, we'd like to make as many decisions as we can with a block worth of data. But, there is no way for us to do this -- it is tremendoulsy unlikely that the next node we need will be within the same block.
To address this problem, some on-disk BSTs, known as virtual BSTs cache recently used blocks in main meory. Typically, this results in caching the top portion of the tree. When this is done, seeks are only required for the branching at the lower portion of the tree. But, it is important to relaize that trees grow exponentially (2n), so more nodes live at the bottom than the top.
At the end of the day, we'd like a tree that remains balanced without frequent manipulation of existing nodes -- and that packs as many decisions as possible into a single node, so each seek gets all the bang for the buck that it can.
Enter the B-Tree
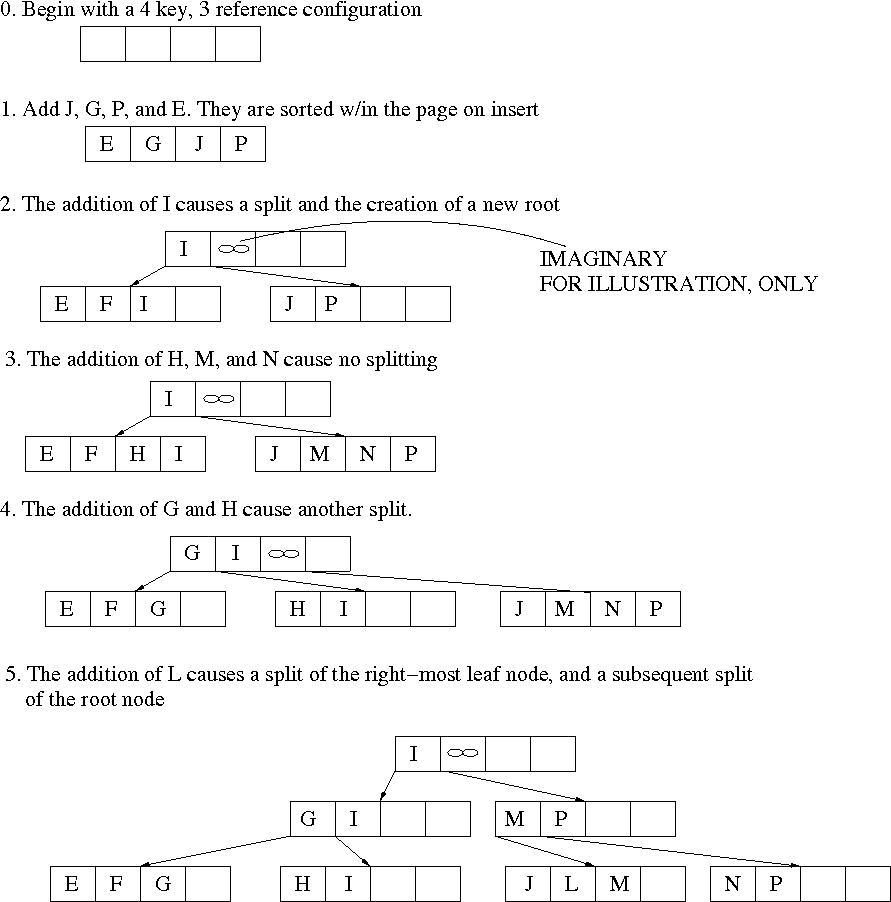
So, let's begin jumping the hurdles. We must: (a) make more decisions per seek and (b) balance the tree on the cheap. The so-called B-Tree's solution to the first of these is pretty straight-forward. Its answer to the second is truly beautiful.So, what do do about the fact that a binary tree makes only one decision per node? Easy enough: use a higher order tree. Instead of placing only one key per tree, we place as many keys per tree node as we can pack in. We fill the whole block with keys. Then, instead of doing a "Left or Right" comparison, walk through the keys and find the right position -- charge down the corresponding branch.
Normally, in memory, charing linearly down a list would be said to be inefficient -- better to divide up the tree than to linearly search a list. But, in the case of an on-disk data structure, we've already paid the huge mS price to get the block -- we might as well spend a few more uS getting everything we can out of it.
Consistent with this idea is the idea of placing only keys in the tree's internal nodes -- the actual data records are kept only in (or referenced only by) the leaf nodes. This lets us pack more keys into the nodes -- and also cheaply create a sequence set (sorted sequential list). We'll talk more about the sequence set soon.
Small ideas aside, the second of the key ideas is the "bottom up" growth of the B-Tree. When a BST grows, the new node gets added to the bottom. In an AVL tree, the branches then get rotated from the bottom up to repair the tree. In a B-tree, the tree actually grows from the bottom up.
Since new nodes are always added at the bottom, the tree can remain balanced. Basically, the tree grows on a level-by-level basis with the growth propogating from the bottom up. As nodes grow, they split causing a new key, the difference, to be inserted into their parent. This can in turn cause the parent to grow -- all the way up to the root.
B-Tree By Example
B-Tree Improvements
Some implementations of B-Trees implement two minor "improvements":
- 2-3 splits. Instead of spliting into two nodes, keys are "redistributed" between siblings until two adjacent siblings are full then these two are split into three. This adds cost to the insertion, but results in a higher packing density. The greater density means more decisions per seek to disk and, as a result, a shorter branch and fewer seeks.
- A "sequence set". Notice that all the data records run along the leaves. Notice that, from left to right, they are in sorted order. Notice also that they began as one page and split into siblings, eventually resulting in several. If we set up "next" and "prev" pointers upon leaf splits, we end up with a doubly linked list across the bottom. With that we can get forward and reverse sequential access without traversing the tree.